RouteMoA:事前推論なしの動的ルーティングによる効率的なMixture-of-Agentsのブースト
従来のMixture-of-Agents(MoA)は、全モデルを推論させてから統合するため計算コストと遅延が膨大でしたが、本研究は事前推論を行わずに最適なモデルを動的に選択する「RouteMoA」を提案しました。
TL;DR(結論)
従来のMixture-of-Agents(MoA)は、全モデルを推論させてから統合するため計算コストと遅延が膨大でしたが、本研究は事前推論を行わずに最適なモデルを動的に選択する「RouteMoA」を提案しました。軽量なスコアラー(SLM)による初期選別と、モデル自身の自己・相互評価を組み合わせた「Mixture of Judges」により、推論コストを抑えつつ高精度なルーティングを実現し、大規模モデルプールでの効率を劇的に改善しています。検証の結果、RouteMoAは従来のMoAと比較して精度を維持または向上させながら、コストを89.8%、遅延を63.6%削減することに成功し、15種類以上の多様なモデルを含む大規模な環境でも優れたスケーラビリティを示しました。
なぜこの問題か
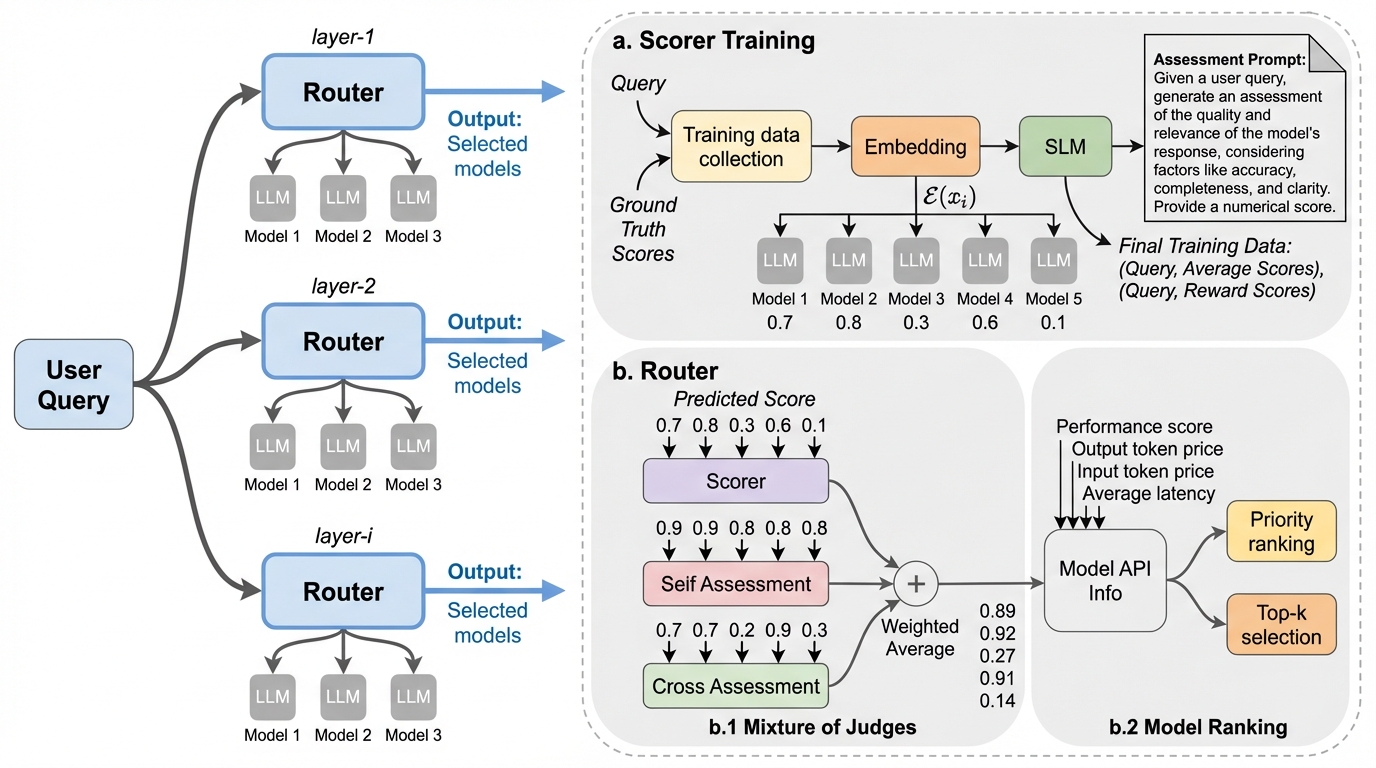
大規模言語モデル(LLM)の分野では、複数のモデルを連携させて性能を向上させるMixture-of-Agents(MoA)という手法が注目されています。しかし、従来のMoAは「密なトポロジー」を持っており、各レイヤーで参加するすべてのモデルを推論させる必要があるため、リソース消費が非常に激しいという課題がありました。特に、モデルの数が増えるほど計算コストと応答遅延(レイテンシ)は指数関数的に増大し、実用上の大きな障壁となっています。既存の改善策として、モデルの回答をフィルタリングする「Sparse MoA」なども提案されていますが、これらは「まず全モデルに推論させてから、どの回答が良いかを判断する」という手順を踏むため、推論コストそのものを削減することはできていません。また、判断のために追加のLLM(ジャッジモデル)を呼び出す必要があり、さらなるオーバーヘッドが発生します。 さらに、利用可能なモデルプールが10個を超えるような大規模なケースでは、すべてのモデルを動かすことは予算的に不可能であるだけでなく、コンテキスト制限を超えてしまうという物理的な限界にも直面します。モデルにはそれぞれ得意分野があることが分かっています。…
核心:何を提案したのか
本研究では、事前推論を必要としない動的ルーティングを備えた効率的なMixture-of-Agentsフレームワーク「RouteMoA」を提案しました。このフレームワークの核心は、クエリの内容から各モデルの性能を予測し、有望なモデルだけを起動させることで、計算リソースを大幅に節約する点にあります。RouteMoAは主に3つのコンポーネントで構成されています。第一に、軽量な小規模言語モデル(SLM)ベースの「スコアラー」です。これはクエリが入力された直後に、各モデルがそのクエリに対してどの程度のパフォーマンスを発揮するかを粗い粒度で予測します。 第二に、スコアラーの予測誤差を修正するための「Mixture of Judges(ジャッジの混合)」です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related