方策改善としての成功条件付け:成功の模倣によって解かれる最適化問題
成功条件付け(成功した軌跡を模倣する手法)は、LLMの調整や強化学習で広く使われていますが、その理論的な最適化対象は不明でした。本論文は、この手法が$\chi^2$ダイバージェンスを制約とした信頼領域最適化問題を正確に解いていることを証明しました。
TL;DR(結論)
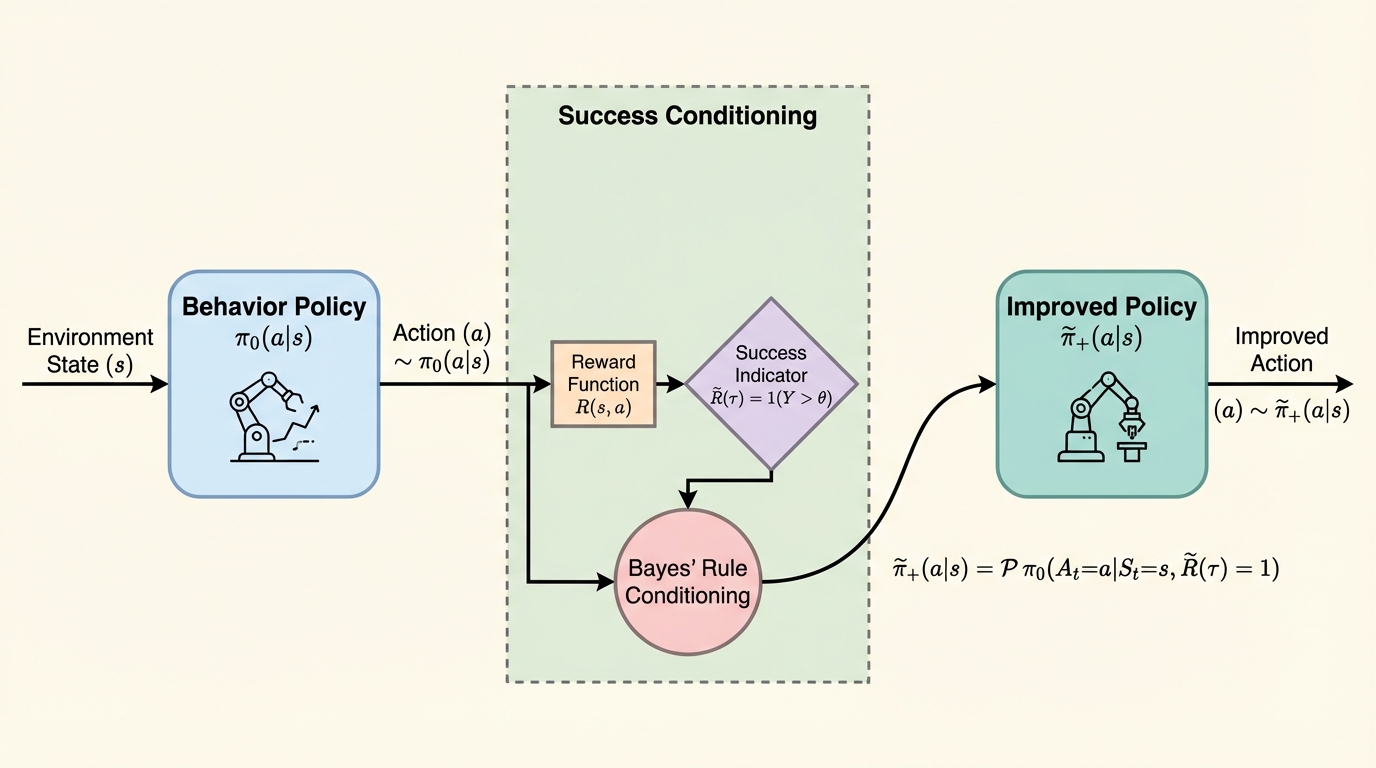
成功条件付け(成功した軌跡を模倣する手法)は、LLMの調整や強化学習で広く使われていますが、その理論的な最適化対象は不明でした。本論文は、この手法が$\chi^2$ダイバージェンスを制約とした信頼領域最適化問題を正確に解いていることを証明しました。 「方策の改善度」「方策の変化量」「アクションの影響力(行動選択が成功率に与える変動)」の3つが、すべての状態で数学的に一致するという「アクション影響力同一性」を提示しました。これにより、学習中の変化量から改善度を直接診断することが可能になります。 この手法は、TRPOなどの既存手法と比較して非常に保守的であり、過去に探索されていない稀な行動を抑制する性質を持っています。失敗する際も危険な挙動を示すのではなく、単に「方策をほとんど更新しない」という形で現れるため、安全性が高いことが示されました。
なぜこの問題か
強化学習や言語モデルの事後学習において、成功した軌跡を収集し、その行動を模倣するようにモデルを更新する「成功条件付け」という手法が広く採用されています。この手法は、言語モデルの整列における拒絶サンプリングと教師あり微調整(SFT)の組み合わせや、推論モデルにおける自己生成された正解に基づく微調整、さらにはDecision Transformerのような手法など、多岐にわたるドメインで異なる名称で現れています。例えば、DeepSeek-R1のような大規模システムでは、強化学習を安定させるためにこの戦略が適用されています。しかし、これらの手法が直感的に「うまくいったことを保持し、いかなかったものを捨てる」という仕組みであることは理解されていても、数学的にどのような最適化問題を解いているのかはこれまで不明確なままでした。 従来の強化学習手法では、価値関数の推定や方策勾配の計算を通じて明示的な最適化を行いますが、成功条件付けはこれらのプロセスを回避し、単に成功したデータに条件付けられた行動を模倣します。…
核心:何を提案したのか
本論文の主要な提案は、成功条件付けが「信頼領域方策最適化(Trust-Region Policy Optimization)」の一種であることを数学的に証明したことです。具体的には、成功条件付けによって得られる方策は、ある特定の幾何学的制約の下で方策のパフォーマンスを最大化する問題の厳密な解であることを示しました。この信頼領域は、一般的に使われるKLダイバージェンスではなく、$\chi^2$(カイ二乗)ダイバージェンスによって定義されます。また、その制約の半径はユーザーが設定するハイパーパラメータではなく、データ内の「アクション影響力(Action-influence)」という量によって自動的に決定されることが明らかになりました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related