Adamの$\beta_1 = \beta_2$設定が優れている理由:勾配スケール不変性の原理
Adamのハイパーパラメータである$\beta1$と$\beta2$を等しく設定することで、訓練の安定性と精度が向上するという経験的事実に対し、「勾配スケール不変性」という新たな理論的枠組みを導入して数学的な解明を行った。
TL;DR(結論)
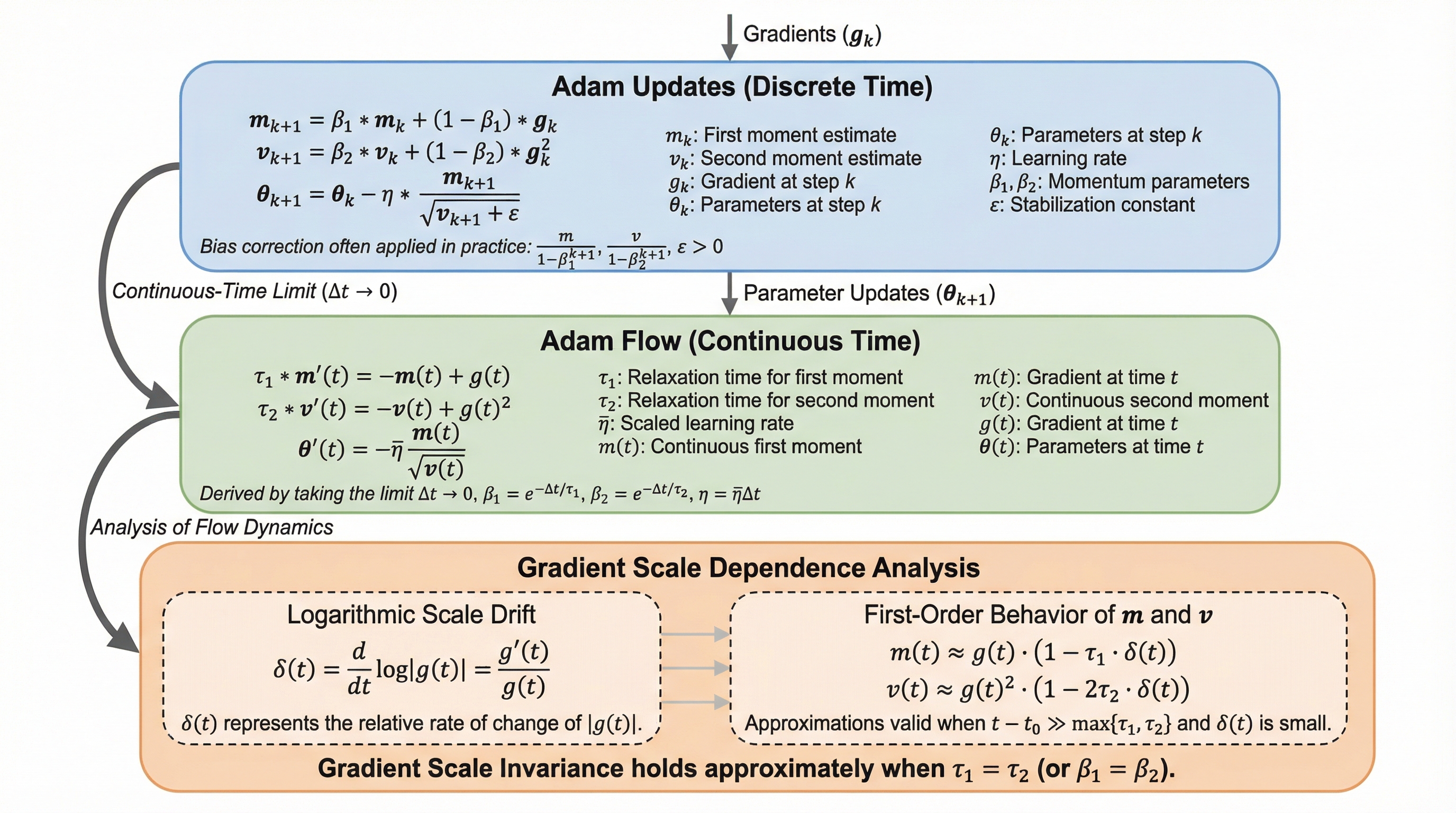
Adamのハイパーパラメータである$\beta1$と$\beta2$を等しく設定することで、訓練の安定性と精度が向上するという経験的事実に対し、「勾配スケール不変性」という新たな理論的枠組みを導入して数学的な解明を行った。 連続時間流を用いた解析により、$\beta1 = \beta2$の場合にのみAdamが一次の勾配スケール不変性を満たすことを証明し、この設定が勾配の急激な大きさの変化に対して更新ベクトルを安定化させる本質的なメカニズムであることを明らかにした。 画像認識や言語モデルを用いた広範な実験を通じて、この理論的予測が実際の訓練における更新ノルムの平滑化として現れることを確認し、最新の正規化最適化手法と同様の設計原理がAdamの内部にも存在することを事実として示した。
なぜこの問題か
Adamは導入から約10年の間、大規模なディープラーニング訓練の中核を担ってきた最適化アルゴリズムである。元々の論文では$\beta1 = 0.9$、$\beta2 = 0.999$という標準的なデフォルト値が提案されており、多くのタスクでこれが無批判に踏襲されてきた。しかし、近年の一部の研究や大規模言語モデルの訓練現場では、これら2つのパラメータを等しく設定する、つまり$\beta1 = \beta2$とすることで、訓練がより安定し、最終的な精度が向上するという報告がなされている。特に非常に深いネットワークや大規模なデータセットを用いる場合、この傾向は顕著に観察されているが、なぜこの特定の構成が優れた挙動を示すのかについては、厳密な理論的説明がなされていなかった。一方で、近年の新しい最適化手法であるLionやMuon、Scionなどは、勾配の大きさに依存しない正規化された更新や符号情報を利用する設計を採用している。これらの手法は、勾配のスケールに対する感度を低減させることを共通の目的としており、現代の最適化において望ましい特性として浮上している。…
核心:何を提案したのか
本研究の主要な貢献は、最適化アルゴリズムにおける「勾配スケール不変性」という概念を定式化したことである。勾配スケール不変性とは、あるステップにおいて勾配を正の定数倍しても、更新ベクトルが本質的に変化しないという性質を指す。標準的な勾配降下法はこの性質を持たず、勾配の大きさに比例して更新量が変化するが、Adamは特定の条件下でこの不変性を近似的に獲得できることを示した。具体的には、Adamを連続時間的な動的システムとして捉える「Adam流」の枠組みを用いて解析を行った。この解析により、Adamの更新ベクトルが勾配のスケール変化に対してどのように反応するかを数学的に導出した。その結果、Adamが一次の勾配スケール不変性を満たすための必要十分条件が$\beta1 = \beta2$であることを証明した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related