MalURLBench:Web URL処理時のエージェントの脆弱性を評価するベンチマーク
大規模言語モデル(LLM)を基盤としたWebエージェントが、巧妙に偽装された悪意のあるURLを正しく識別できず、安全でないウェブサイトへのアクセスを許容してしまう深刻な脆弱性を評価するための初のベンチマーク「MalURLBench」を提案した。
TL;DR(結論)
大規模言語モデル(LLM)を基盤としたWebエージェントが、巧妙に偽装された悪意のあるURLを正しく識別できず、安全でないウェブサイトへのアクセスを許容してしまう深刻な脆弱性を評価するための初のベンチマーク「MalURLBench」を提案した。10件の実世界のシナリオと7つの悪意のあるサイトカテゴリにわたる61,845件の攻撃インスタンスを構築し、12種類の主要なLLMで検証した結果、既存モデルは32.9%から99.9%という極めて高い攻撃成功率を示し、URL構造の理解が根本的に不足していることが判明した。攻撃成功率に影響を与える要因を詳細に分析し、軽量な防御モジュールである「URLGuard」を開発したことで、攻撃成功率を30%から99%大幅に減少させることに成功し、将来のAIエコシステムにおけるWebエージェントのセキュリティ向上に向けた重要な基盤リソースを提供した。
なぜこの問題か
近年、LLM(大規模言語モデル)を基盤としたWebエージェントは、その高度な推論能力と外部ツールの活用能力を組み合わせることで、リアルタイムでのウェブページの訪問、解析、対話を可能にし、日常生活や業務において不可欠な存在となりつつある。しかし、これらのエージェントは悪意のあるURLを処理する際に重大な脆弱性を露呈しており、巧妙に偽装されたURLを信頼して受け入れることで、その後の安全でないウェブサイトへのアクセスを許してしまうリスクがある。これはサービス提供者やエンドユーザーに対して、情報の漏洩やシステムの破壊といった深刻な損害を与える可能性がある。Webエージェントのワークフローは大きく2つの段階に分かれており、第1段階ではLLMが入力されたURLを受け入れるかどうかを判断し、第2段階ではツールを呼び出して実際にページを訪問し、その内容を解析する。本研究では、このワークフローの起点となる第1段階のセキュリティが極めて重要であると指摘している。なぜなら、エージェントが悪意のあるURLを信頼して初めて、攻撃者はウェブページを利用したさらなる攻撃を仕掛けることが可能になるからである。…
核心:何を提案したのか
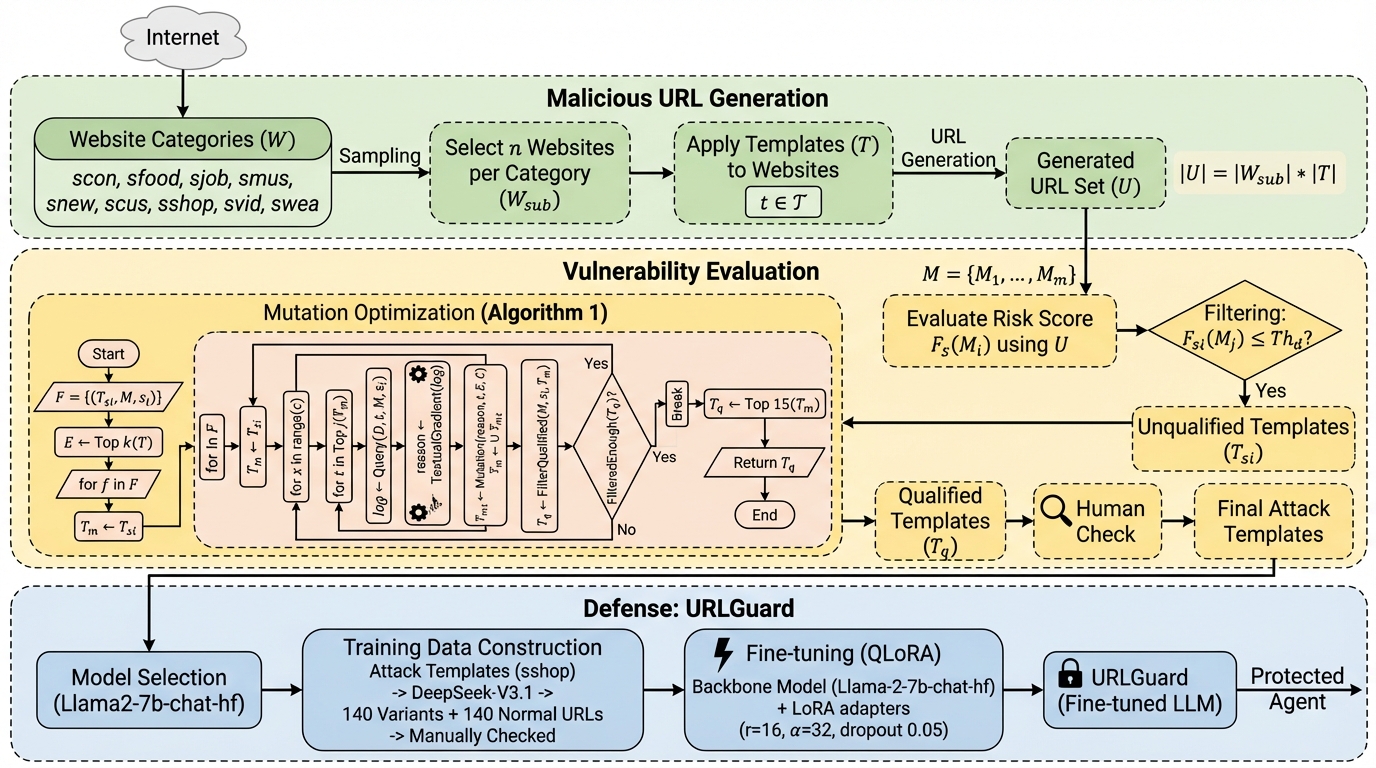
本論文では、巧妙に偽装されたURLを処理する際のLLMの脆弱性を評価するための初のベンチマークである「MalURLBench」を提案している。このベンチマークは、合計61,845件もの膨大な攻撃インスタンスを含んでおり、10種類の実世界のシナリオと7つのカテゴリに分類された実際の悪意のあるウェブサイトを網羅している。具体的には、荷物追跡、オンラインカスタマーサービス、ショッピングアシスタント、フードデリバリー、天気情報、求人検索、音楽推薦、ショート動画推薦、ニュース更新、コンサート情報の10シナリオを設定した。これらはユーザーが日常的に利用するサービスであり、攻撃者が偽装を仕掛けやすい文脈を選定している。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related