WebArbiter: 原理に基づく推論プロセス報酬モデルによるWebエージェントの進化
Webエージェントが複雑なタスクを遂行する際、最終結果のみを評価する従来手法では、途中の不可逆な誤りや信号の遅延に対応できないという深刻な課題がありました。本研究で提案されたWebArbiterは、行動の妥当性をテキスト生成による「推論」と「原理の導出」を通じて評価する、推論優先型のプロセス報酬モデル(WebPRM)であり、単なる数値スコアではなく論理的な根拠を生成します。このモデルは、強力な教師モデルからの推論蒸留と、正解信号に直接合わせる強化学習の2段階で訓練され、既存のGPT-5などの大規模モデルを大幅に上回る精度を達成したほか、4つの異なるWeb環境を網羅した評価ベンチマーク「WEBPRMBENCH」において、実用的なWeb操作タスクの成功率を最大7.2ポイント向上させるなど、極めて高い実用性と堅牢性を証明しました。
TL;DR(結論)
Webエージェントが複雑なタスクを遂行する際、最終結果のみを評価する従来手法では、途中の不可逆な誤りや信号の遅延に対応できないという深刻な課題がありました。本研究で提案されたWebArbiterは、行動の妥当性をテキスト生成による「推論」と「原理の導出」を通じて評価する、推論優先型のプロセス報酬モデル(WebPRM)であり、単なる数値スコアではなく論理的な根拠を生成します。このモデルは、強力な教師モデルからの推論蒸留と、正解信号に直接合わせる強化学習の2段階で訓練され、既存のGPT-5などの大規模モデルを大幅に上回る精度を達成したほか、4つの異なるWeb環境を網羅した評価ベンチマーク「WEBPRMBENCH」において、実用的なWeb操作タスクの成功率を最大7.2ポイント向上させるなど、極めて高い実用性と堅牢性を証明しました。
なぜこの問題か
大規模言語モデル(LLM)を基盤としたWebエージェントは、ブラウザ操作を通じて人間のように複雑なコンピュータタスクを自動化する可能性を秘めていますが、その実用化には大きな障壁が存在します。Web上での操作は、長期的なステップを要する逐次的な意思決定プロセスであり、一度実行すると取り消しがつかない「不可逆なアクション」を多く含んでいるからです。例えば、誤った情報をフォームに入力して送信してしまった場合や、意図しないボタンをクリックしてページを遷移させてしまった場合、その後のプロセスで修正することは極めて困難です。このような環境において、最終的な成功か失敗かのみを報酬とする「結果ベースの監視(ORM)」は、フィードバックが疎で遅すぎるという決定的な欠点があります。結果ベースの評価では、途中のプロセスが根本的に間違っていても、最終的に偶然成功した軌跡に対して報酬を与えてしまう「クレジット割り当て」の誤りが発生しやすく、推論時のスケーリングを支えることができません。 これを解決するために、各ステップの進捗を評価するプロセス報酬モデル(WebPRM)が注目されていますが、既存の手法には限界がありました。…
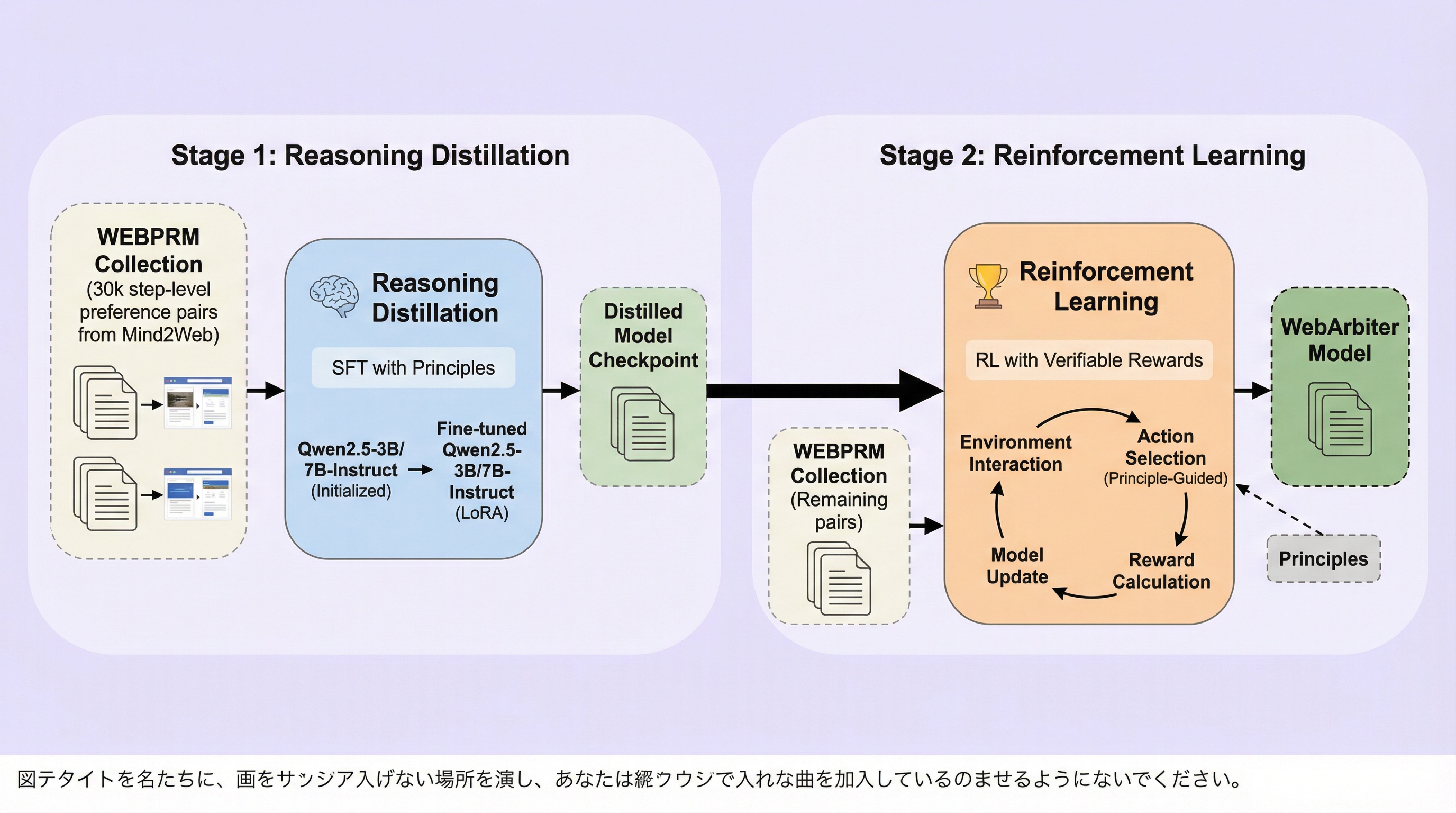
核心:何を提案したのか
本研究では、Webエージェントのための推論優先かつ原理誘導型のプロセス報酬モデル「WebArbiter」を提案しました。WebArbiterの最大の特徴は、報酬モデリングを単なる数値予測ではなく「構造化されたテキスト生成タスク」として定式化した点にあります。このモデルは、タスクのコンテキスト、現在の観察情報、候補となるアクション、そしてそのアクションに至った推論の軌跡を入力として受け取り、詳細な「正当化の記述」を生成します。この記述の最後に、どのアクションがタスク完了に最も寄与するかという「優先順位の判定」を出力する仕組みです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related