Text-to-SQLを超えて:LLMは本当にエンタープライズETLのSQLをデバッグできるのか?
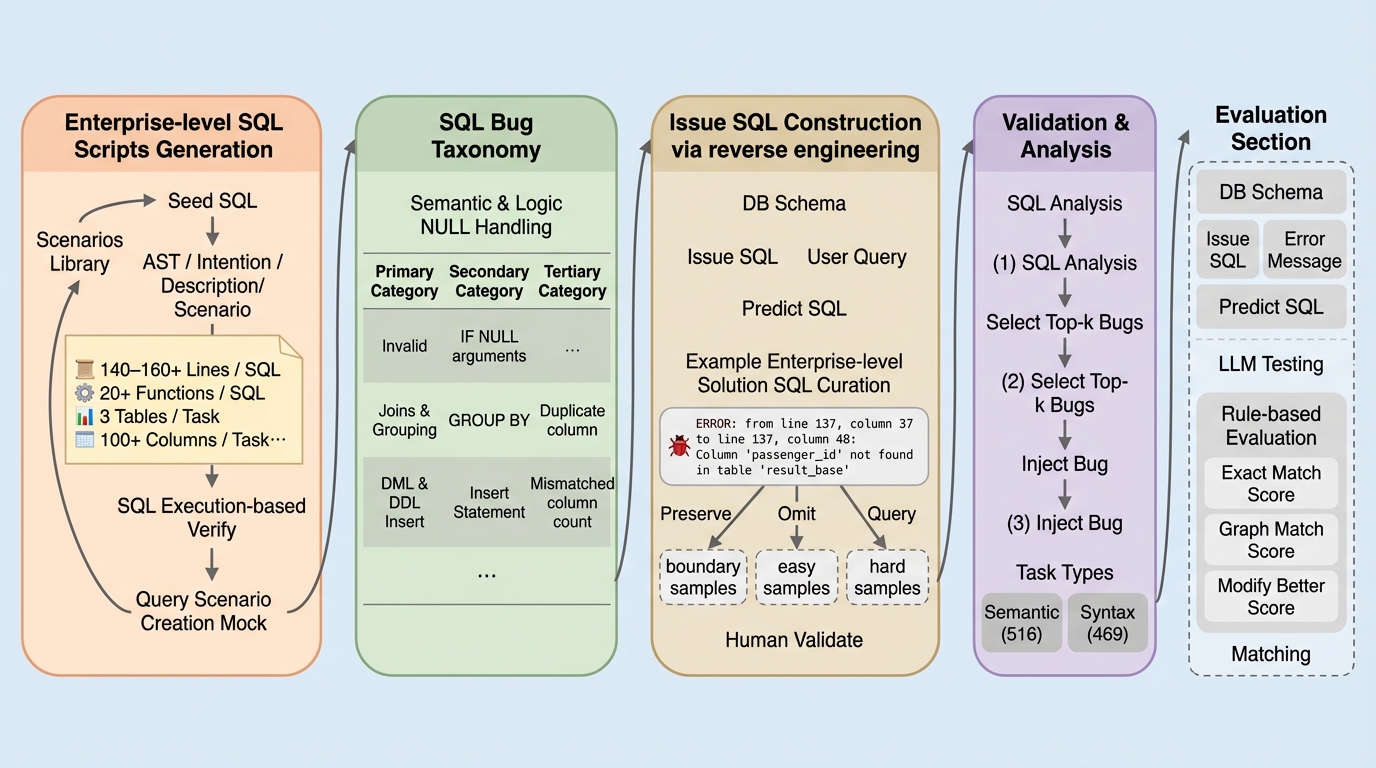
エンタープライズレベルのSQLデバッグ能力を評価するため、実世界の複雑なETLワークフローを反映した「Squirrel Benchmark」が提案されました。 このベンチマークは、平均140行を超える長大なコードと、構文エラーを扱う469件のタスク、および意味的な誤りを扱う516件のタスクで構成されています。
TL;DR(結論)
エンタープライズレベルのSQLデバッグ能力を評価するため、実世界の複雑なETLワークフローを反映した「Squirrel Benchmark」が提案されました。 このベンチマークは、平均140行を超える長大なコードと、構文エラーを扱う469件のタスク、および意味的な誤りを扱う516件のタスクで構成されています。 最新のClaude-4-Sonnetでも成功率は40%を下回り、既存の多くのモデルが20%未満に留まるなど、産業界の要求と現在のAI能力には大きな乖離があることが判明しました。
なぜこの問題か
現代のデータインフラにおいて、データベースは金融やウェブサービス、科学計算などの重要なアプリケーションを支える基盤となっています。その中心となるSQLは、大規模なデータの抽出、変換、読み込みを行うETLワークフローを動かす主要なインターフェースです。しかし、実際のエンタープライズ環境におけるSQLコードは、非常に長く、複雑で、深くネストされていることが一般的です。このような環境では、経験豊富な開発者や高度なText-to-SQLモデルであっても、一度の試行で完全に正しいコードを生成することは極めて困難です。 通常、SQLの開発には、エラー箇所の特定、原因の分析、スキーマ定義の確認、修正の適用、そして要件を満たしているかの検証という、反復的なデバッグプロセスが必要となります。しかし、既存の大規模言語モデル(LLM)は、この多段階の推論や反復的な修正プロセスにおいて、意味のない修正を繰り返したり、初期の修正が失敗した際に同じ行動をループしたりするアンチパターンに陥りやすいという課題があります。…
核心:何を提案したのか
本論文では、エンタープライズ規模のSQLデバッグを評価するための初のベンチマークである「Squirrel Benchmark」を提案しています。このベンチマークは、実世界のETLや分析ワークロードの複雑さ、多様性、実用性を捉えるように設計されています。主な提案内容は、自動化されたベンチマーク構築パイプラインと、実行環境に依存しない効率的な評価フレームワークの2点です。 構築パイプラインでは、リバースエンジニアリングの手法を用いて、大規模なSQLコードに現実的なバグを系統的に注入します。これにより、人手によるコストを最小限に抑えながら、高品質で多様なデバッグタスクを大規模に生成することが可能になりました。このプロセスは、単なる評価用データの作成だけでなく、現実的な学習データの合成にも応用できる基盤となります。 Squirrel Benchmarkは、大きく分けて2つのカテゴリで構成されています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related