Typhoon-S:ソブリン大規模言語モデルのための最小限のオープン事後学習
現在の大規模言語モデル開発は膨大な計算資源とデータを持つ一部の組織に集中しており、特定の地域や国が独自のデータ管理や制御を維持しつつモデルを構築する「ソブリン設定」において、リソースの制約が大きな障壁となっています。
TL;DR(結論)
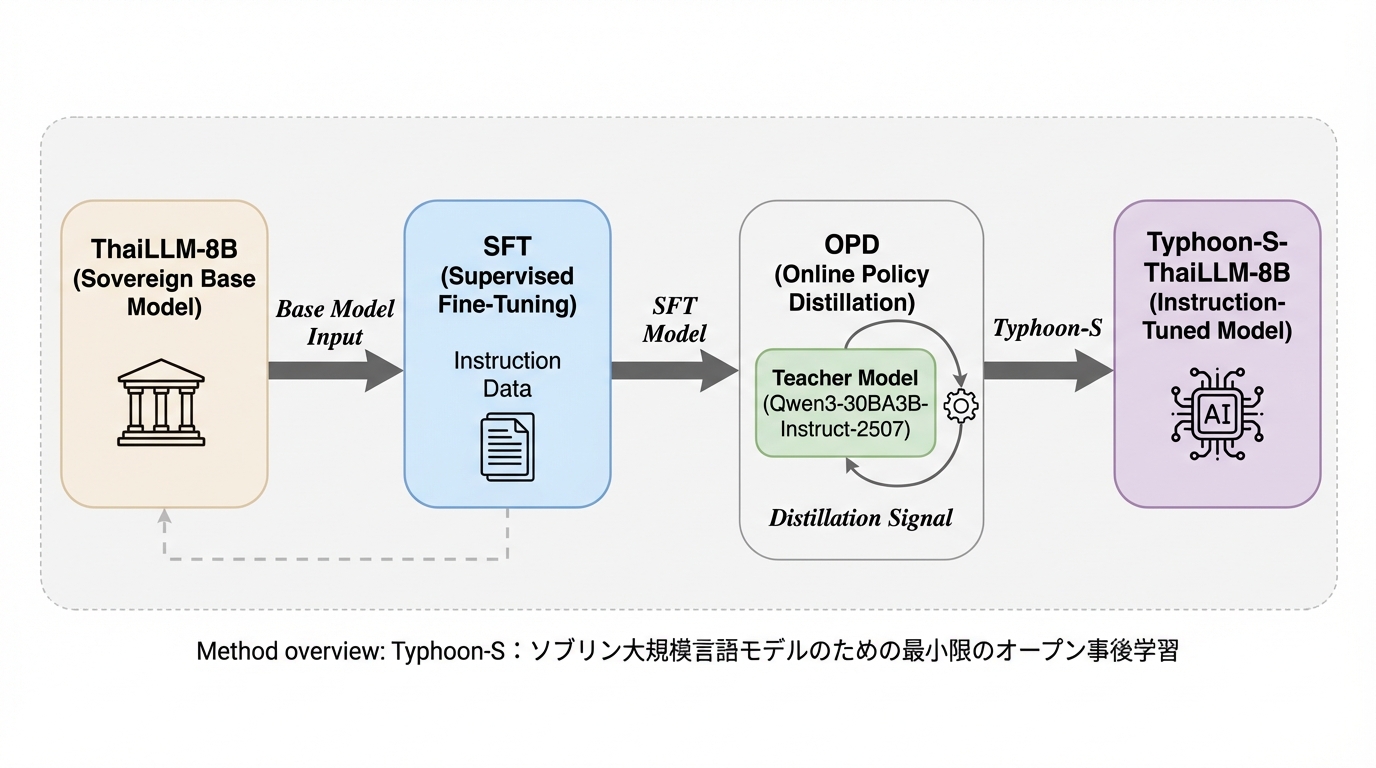
現在の大規模言語モデル開発は膨大な計算資源とデータを持つ一部の組織に集中しており、特定の地域や国が独自のデータ管理や制御を維持しつつモデルを構築する「ソブリン設定」において、リソースの制約が大きな障壁となっています。本研究では、限定的な計算資源でも汎用的なアシスタント能力と地域固有の高度なタスク遂行能力を両立させるための最小限かつオープンな事後学習レシピである「Typhoon-S」を提案し、タイ語を事例としてその有効性を検証しました。この手法は、教師モデルからの知識蒸留を行うオンポリシー蒸留と、新しい知識の習得と推論能力の向上を同時に実現するInK-GRPOを組み合わせることで、8Bクラスのモデルを数日の学習で最先端のオープンモデルに匹敵する性能へと引き上げることに成功しています。
なぜこの問題か
近年、大規模言語モデル(LLM)は急速な進歩を遂げていますが、その開発と評価の多くは英語や中国語といった高リソース言語に偏っているのが現状です。また、最先端モデルの開発は、大規模な計算資源と膨大なデータにアクセスできるごく一部の組織によって独占されており、これが「リソースによるゲートキーピング(門番)」という実質的な障壁を生み出しています。特に、特定の地域や国家、あるいは特定のドメインを所有する機関が、モデルの重みや学習データ、展開方法を自ら管理・理解しつつ、限られたリソースと厳格な透明性の制約下で運用しなければならない「ソブリン(主権的)設定」において、この問題は深刻です。既存の「完全にオープン」とされる取り組みであっても、数百万ドルの計算コストを要する場合があり、小規模な研究グループや国家レベルの取り組みが、地域固有のニーズに合わせてモデルを適応させることは困難を極めます。 タイ語のような言語においては、既存のソブリン適応型ベースモデルは地域的な知識については高い性能を示すものの、汎用的な指示への追従やツール利用、エージェント的な振る舞いにおいては、主要な商用モデルやオープンモデルに後れを取っているという課題があります。…
核心:何を提案したのか
本研究では、上述の課題を解決するために、最小限かつオープンな事後学習レシピである「Typhoon-S」を提案しています。このレシピは、学術レベルのリソース制約下で、最先端モデルに匹敵する性能を実現することを目的としており、主に2つの核心的な要件に焦点を当てています。第一の要件は「採用可能性(Adoptability)」であり、これはベースモデルを、指示追従、数学的推論、コード生成、ツール利用が可能な汎用的なアシスタントへと変換する能力を指します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related