VIBEVOICE-ASR 技術報告書
VIBEVOICE-ASRは、会議やポッドキャストなどの最長60分に及ぶ長尺音声を、分割せずに一度のパスで処理可能な汎用音声理解フレームワークであり、従来の手法で課題となっていた文脈の断片化や複数話者の複雑性を解消することに成功しています。
TL;DR(結論)
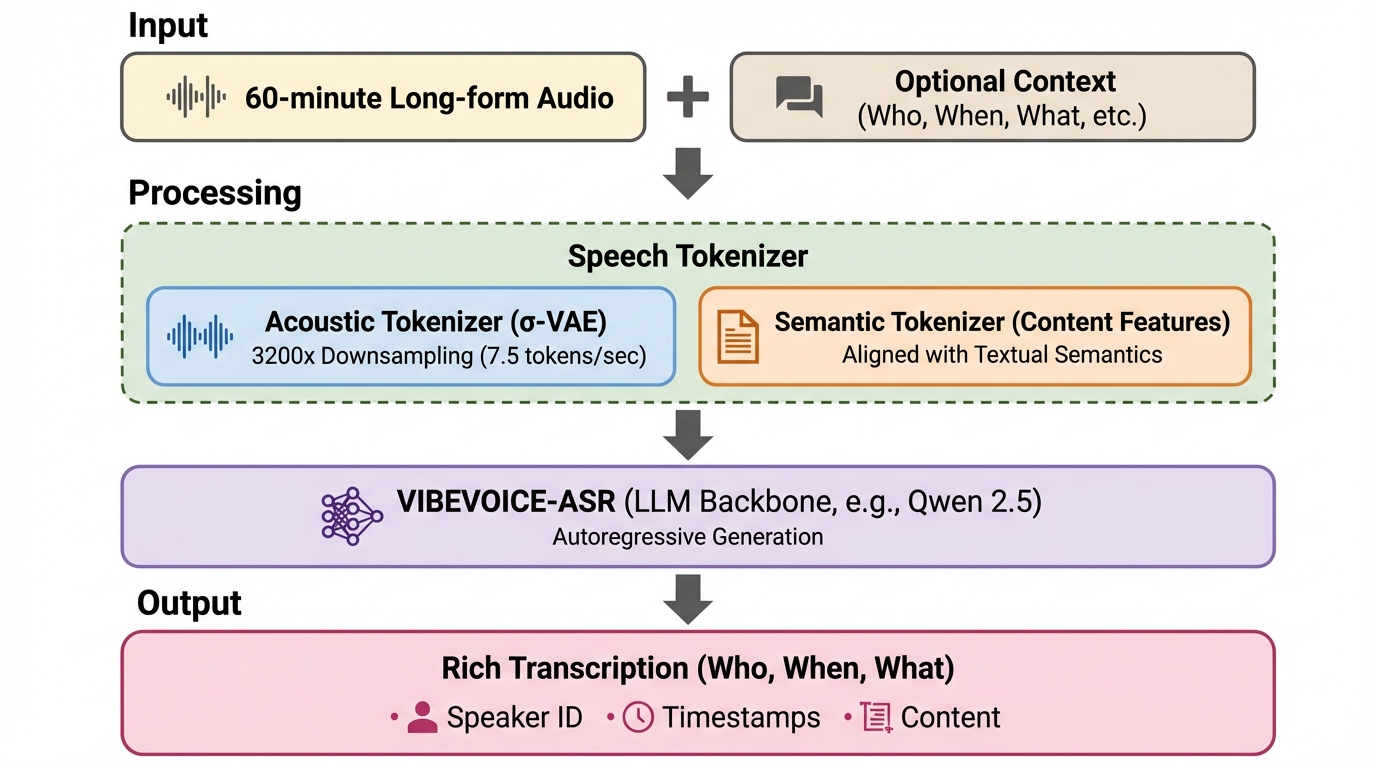
VIBEVOICE-ASRは、会議やポッドキャストなどの最長60分に及ぶ長尺音声を、分割せずに一度のパスで処理可能な汎用音声理解フレームワークであり、従来の手法で課題となっていた文脈の断片化や複数話者の複雑性を解消することに成功しています。 このシステムは、音声認識(ASR)、話者識別(Diarization)、タイムスタンプ付与を「Rich Transcription」という単一の生成タスクとして統合し、50以上の言語に対応するとともに、ユーザーが提供するプロンプトに基づいたドメイン固有の用語認識精度の向上を実現しています。 公開ベンチマークを用いた検証では、Gemini-2.5-ProやGemini-3-Proといった強力なマルチモーダル基盤モデルを、話者識別の正確性(DER)や時間制約付きの認識精度(tcpWER)において一貫して上回る性能を示し、長尺音声理解における新たな基準を確立しました。
なぜこの問題か
近年の音声処理技術は、大規模言語モデル(LLM)と音響エンコーダの統合により、短時間の音声認識において目覚ましい成果を上げています。しかし、1時間に及ぶ会議やポッドキャスト、学術講義といった長尺音声の文字起こしと分析は、依然として困難な課題として残されています。従来の一般的なアプローチでは、連続した音声を30秒未満の短いクリップに分割して独立して処理する「分割統治」戦略が採用されてきました。このパイプライン方式には、主に「文脈の断片化」と「パイプラインの複雑性」という2つの根本的な限界が存在します。 第一に、セグメントを独立して処理することで、グローバルな意味的依存関係が切断されてしまいます。これにより、モデルは文をまたいだ文脈を見失い、長い対話における同音異義語の判別や指示代名詞の解決が困難になります。これは、正確な理解を妨げる致命的な要因となります。第二に、従来のシステムでは音声認識、話者識別、タイムスタンプ付与を別々のモデルで処理し、それらの出力を複雑なヒューリスティックで統合していました。このプロセスでは、セグメンテーションや話者識別の失敗が最終的な文字起こし結果を汚染するという、エラーの伝播が発生しやすくなります。…
核心:何を提案したのか
本報告で提案されたVIBEVOICE-ASRは、従来の「スライディングウィンドウ」方式を根本から放棄し、最長60分の音声を一度のパスで処理する「シングルパス」アプローチを採用した統一フレームワークです。このシステムは、音声認識、話者識別、タイムスタンプ付与という個別のタスクを、単一のエンドツーエンドな生成タスクへと再定式化しています。その出力は「Rich Transcription」と呼ばれ、話者の識別情報(Who)、正確なタイムスタンプ(When)、そして発話内容(What)が構造的にインターリーブされたストリームとして生成されます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related