Quecto-V1:8ビット量子化した小規模言語モデルでオンデバイスのインド法検索を実証分析する
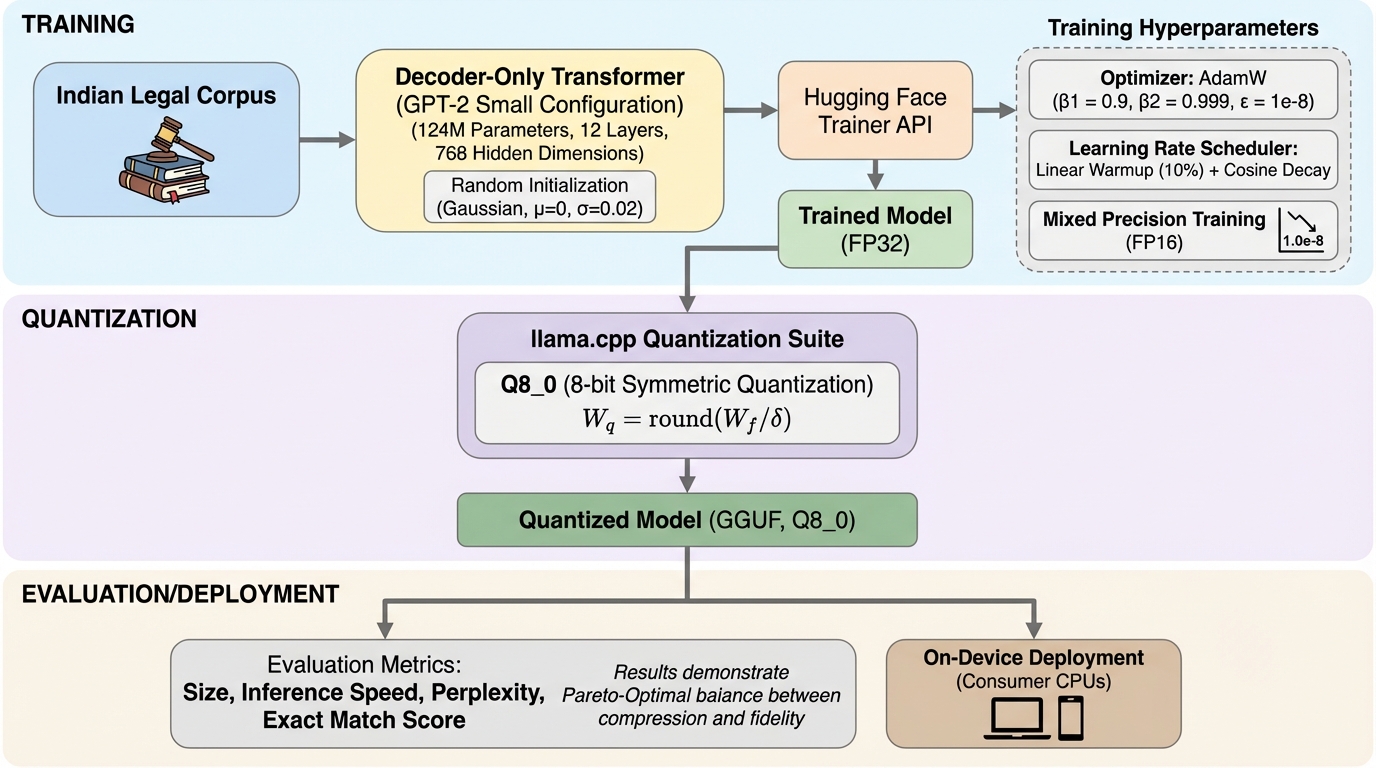
大規模言語モデルをクラウドで使う前提に頼らず、インドの制定法に対象を絞った小規模言語モデルを端末内で動かし、条文の定義や刑罰規定を高い忠実度で取り出せることを示した研究です。 / GPT-2系の124百万パラメータ構成を採用し、IPC・CrPC・インド憲法の制定法コーパスだけでゼロから学習させたうえで、学習後にGGUF形式の8ビット量子化(Q8_0)を行い150MB未満での配備を目指しています。 / ドメイン特化の厳密一致タスクで一般目的の小型モデルより良い結果が示され、量子化でもモデルサイズを74%削減しつつ検索精度の劣化を3.5%未満に抑えられるため、プライバシーを守りながらオフライン運用する選択肢になり得ます。