FBS: Transformer内部におけるネイティブな並列読解のモデリング
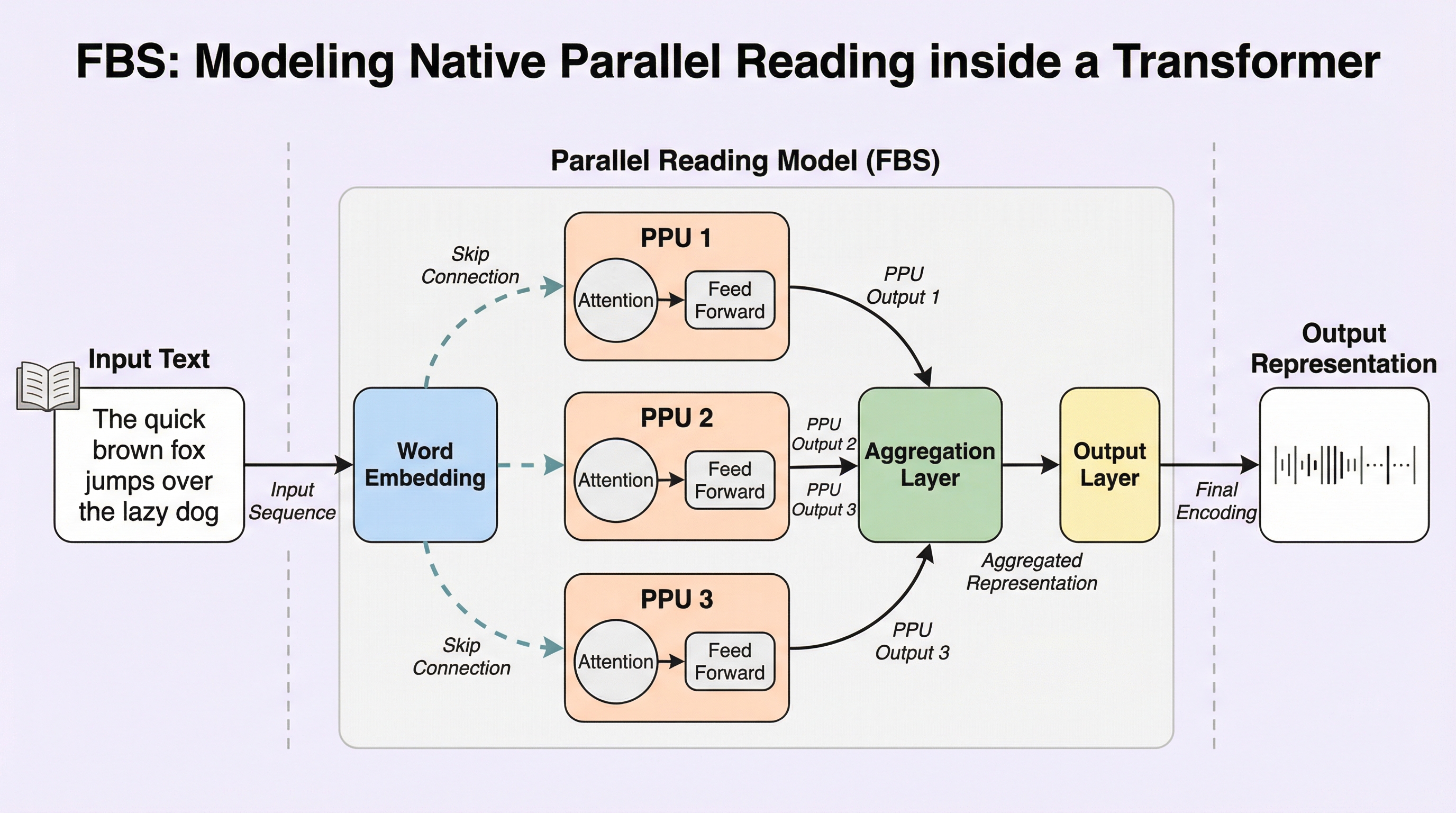
現在の大規模言語モデルが抱える「一語ずつ順番に生成する」という非効率な逐次処理を打破するため、人間の熟練した読解プロセス(予習・情報の塊化・飛ばし読み)をモデル内部に直接組み込んだ新しいアーキテクチャ「Fovea-Block-Skip Transformer(FBS)」が提案されました。
TL;DR(結論)
現在の大規模言語モデルが抱える「一語ずつ順番に生成する」という非効率な逐次処理を打破するため、人間の熟練した読解プロセス(予習・情報の塊化・飛ばし読み)をモデル内部に直接組み込んだ新しいアーキテクチャ「Fovea-Block-Skip Transformer(FBS)」が提案されました。 この手法は、自己回帰的な因果関係を維持したまま、予測的なプレビューを行うPAW、フレーズ単位で意味を統合するCH、そして不要な計算を動的にバイパスするSGという3つの軽量なモジュールを既存のTransformerレイヤーに注入することで、モデルのパラメータ数を増やすことなく推論効率を劇的に高めています。 広範なベンチマークによる検証の結果、FBSは主要な知識・推論タスクにおいてベースラインと同等以上の精度を維持しながら、生成時の遅延を約30%削減し、計算量を36%削減することに成功しており、特に構造化されたテキストや中国語のような言語において顕著な性能向上と効率化の両立を実証しました。
なぜこの問題か
現在の大規模言語モデル(LLM)は、対話、コード生成、複雑な推論など、多岐にわたるタスクで驚異的な能力を発揮していますが、その推論プロセスには「厳密なトークン単位の自己回帰」という根本的なボトルネックが存在しています。従来のモデルは、文脈の難易度や情報の重要度にかかわらず、すべてのステップで均一に膨大な計算資源を消費しており、これは熟練した人間が文章を効率的に処理する方法とは大きくかけ離れています。人間、特に母国語の読者は、周辺視野を利用して次にくる内容を予習(Parafoveal Preview)し、単語を個別に追うのではなく意味のある塊(Chunk)として捉え、さらに確信が持てる箇所では詳細な読みを省略する「スキミング」を駆使して、理解の質を落とさずに高速な読解を実現しています。 既存の推論加速手法の多くは、この逐次的なパイプラインに対して部分的な修正を加える「パッチ」のようなアプローチに留まっており、人間の読解における核心的な要素を統合的に取り込めていません。例えば、投機的デコーディングなどの手法は外部のドラフトモデルに依存しており、モデル内部の構造自体を効率化しているわけではありません。…
核心:何を提案したのか
本研究では、Transformerの各レイヤーに訓練可能な読解ループを注入する「Fovea-Block-Skip Transformer(FBS)」という新しいアーキテクチャを提案しています。FBSは、人間の視覚システムにおける中心窩(Fovea)と周辺視野(Parafovea)の役割を模倣した、3つの協調的なモジュールで構成されています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related