ダビデはゴリアテに勝てるか?:リソース制約のあるエージェントによるマルチホップ推論について
本研究は、計算リソースが極めて限定された環境において、小規模な言語モデルエージェントが大規模モデルに匹敵する高度なマルチホップ推論能力を獲得するための新しい強化学習フレームワーク「DAVID-GRPO」を提案しています。
TL;DR(結論)
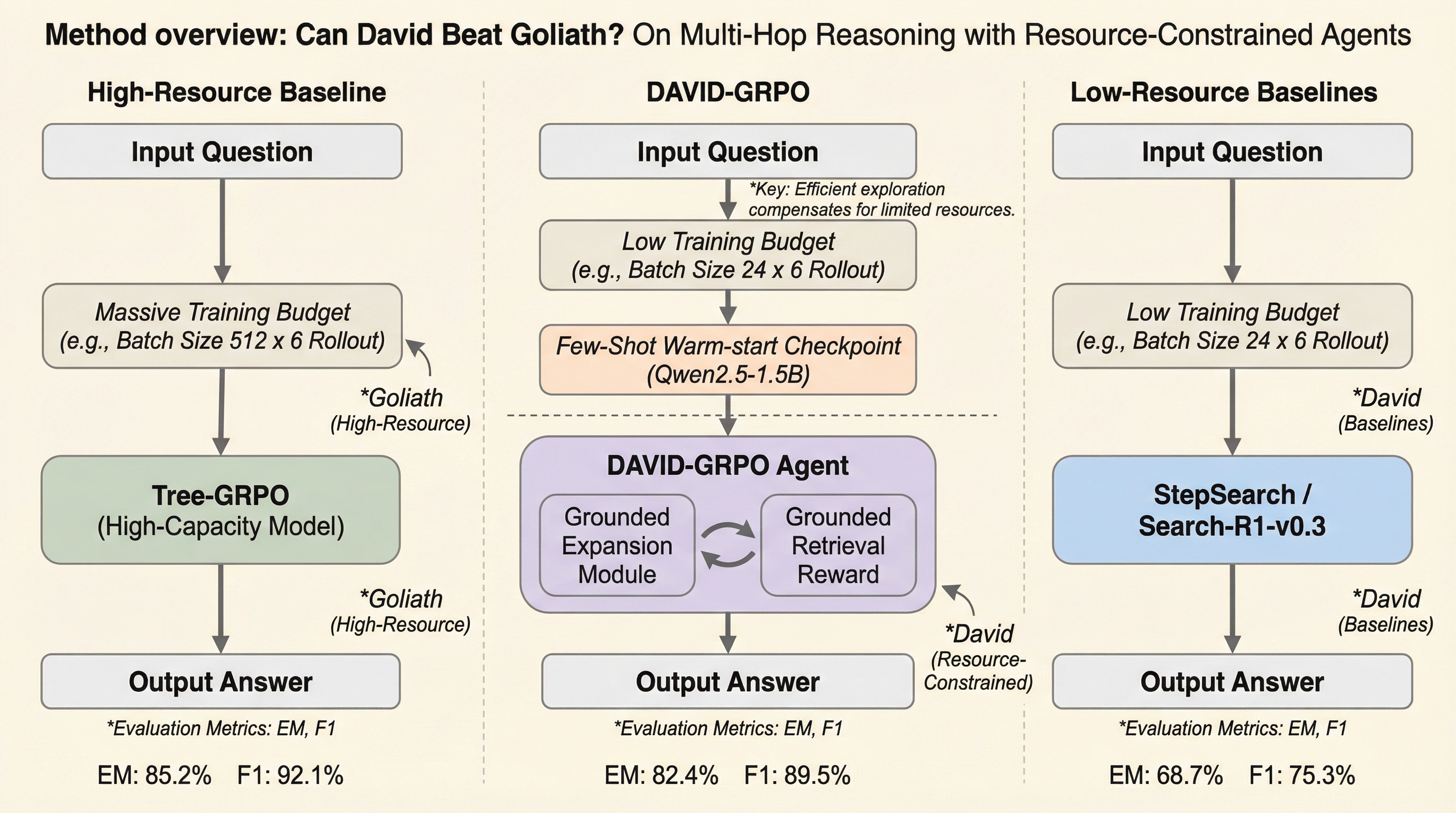
本研究は、計算リソースが極めて限定された環境において、小規模な言語モデルエージェントが大規模モデルに匹敵する高度なマルチホップ推論能力を獲得するための新しい強化学習フレームワーク「DAVID-GRPO」を提案しています。 従来の強化学習が膨大な計算コストと高精度なモデルを前提としていたのに対し、本手法は少数のデモンストレーションを用いたウォームスタート、証拠の再現率に基づく報酬設計、および失敗に近い軌跡の再サンプリングを導入することで、リソース不足による学習の不安定さを解消しました。 実験の結果、わずか4枚のRTX 3090 GPUという一般的な環境下で、1.5Bパラメータのモデルが既存手法のわずか4.7%の予算で同等の性能を達成し、6つの主要なベンチマークにおいて従来の大規模設定向け手法を大幅に上回る精度を記録しました。
なぜこの問題か
近年、強化学習(RL)は言語モデルエージェントに検索ツールや外部ツールを組み合わせた多段階の推論能力を与えてきましたが、その成功の多くは膨大な計算リソースを投入できる環境に依存しています。 大規模なモデルや高密度な探索をサポートできない現実的なリソース制約の下では、小規模な言語モデルエージェントは「低コスト・低精度」という罠に陥りやすく、学習が極めて不安定になるという深刻な問題があります。 具体的には、マルチホップ推論のような複雑なタスクにおいて、リソースが限られているとロールアウト(試行)の回数が制限され、その結果として探索が不足し、報酬が稀薄になり、適切なクレジット割り当てが困難になります。 この問題には3つの主要なボトルネックが存在しており、1つ目は高品質な初期ポリシーがないために効果的な検索意図を形成できず、学習が開始されない「コールドスタート」の問題です。 2つ目は、長い推論プロセスの最後にしか成功か失敗かの信号が得られないため、途中の検索アクションを正しく評価できず、どのステップが正しかったのか判断できない「稀薄な報酬」の問題です。…
核心:何を提案したのか
本研究では、情報検索(IR)の分野におけるゼロショット検索の知見を強化学習に応用した、予算効率の高い強化学習フレームワーク「DAVID-GRPO」を提案しています。 情報検索のコミュニティでは、過去のログやフィードバックがない状況での検索課題に対し、疑似検索フィードバックによる学習の開始、レビューアーによる関連性判定、および類似ドキュメントへの適応的な検索範囲の拡大という3つの原則で対処してきました。 DAVID-GRPOはこのアナロジーに基づき、小規模エージェントのマルチホップ推論における課題を解決するための3つの相乗的なコンポーネントを導入しています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related