ILRR: マスク型拡散言語モデルのための推論時ステアリング手法
離散拡散言語モデル(DLM)の生成を制御するため、追加の学習や微調整を一切必要とせず、単一の参照シーケンスを用いてモデル内部の活性化状態を動的に調整する「反復的潜在表現洗練(ILRR)」という新しいフレームワークが提案されました。
TL;DR(結論)
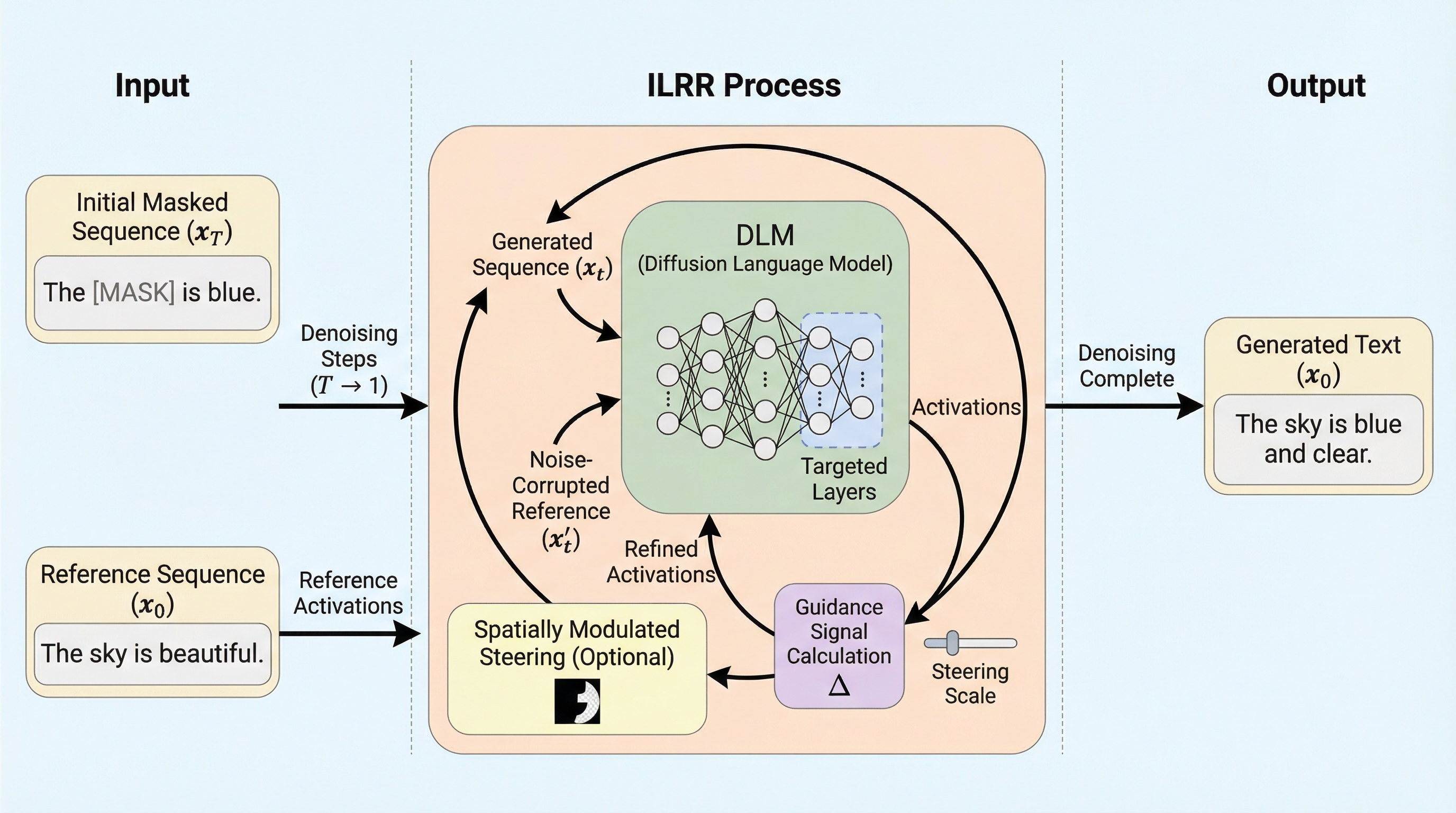
離散拡散言語モデル(DLM)の生成を制御するため、追加の学習や微調整を一切必要とせず、単一の参照シーケンスを用いてモデル内部の活性化状態を動的に調整する「反復的潜在表現洗練(ILRR)」という新しいフレームワークが提案されました。 この手法は、デノイジングの各ステップにおいて、生成中のシーケンスと参照用のシーケンスの両方をモデルに入力し、特定の層で抽出されたセマンティックな信号を整列させることで、感情や毒性といった高レベルな属性を生成物に反映させます。 計算負荷はデノイジングの各ステップで並列なフォワードパスを1回追加するのみと極めて低く、既存の手法と比較して属性制御の正確性を10ポイントから60ポイント向上させつつ、高い生成品質を維持することに成功しており、実用性が非常に高いです。
なぜこの問題か
近年、離散拡散言語モデル(DLM)は、従来の自己回帰型モデルに代わる有望な非逐次的テキスト生成フレームワークとして大きな注目を集めており、モデルのスケールアップや学習手法の進歩により、数学的推論やコード生成といった複雑なタスクにおいて、既存の強力な自己回帰型モデルに匹敵する能力を示すようになっています。 しかし、自己回帰型モデルでは生成時の制御手法が確立されているのに対し、DLMにおける推論時の制御メカニズムはまだ十分に探索されていないという大きな課題があり、推論時のステアリング(制御)は、モデルのパラメータを微調整するための膨大な計算リソースや追加の学習データを必要とせずに、安全性の制約を課したり、特定のスタイルや属性を付与したりできるため、実用上非常に魅力的な技術です。 既存のDLM向け制御手法には、サンプリングレベルでのガイダンスや軌道最適化メカニズムなどが存在しますが、これらは複数の候補シーケンスを並列に保持したり、反復的な再サンプリングを行ったりする必要があり、結果として大きな計算オーバーヘッドが発生するという問題がありました。…
核心:何を提案したのか
本論文では、学習を必要とせず、単一の参照シーケンスを用いてDLMの生成を制御する「反復的潜在表現洗練(ILRR:Iterative Latent Representation Refinement)」を提案しており、この手法は画像生成などの連続値拡散モデルで用いられるILVRという技術から着想を得て、それをテキストという離散的なドメインに適応させたものです。 ILRRの核心は、デノイジングの各ステップにおいて、生成中のシーケンスの内部活性化(アクティベーション)を、望ましい属性を持つ参照シーケンスの活性化と動的に整列させる点にあり、具体的には、モデルの特定の層のセットにおいて、参照シーケンスから抽出された高レベルな意味情報を生成プロセスに注入します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related