オーバースケーリングの呪いを打破する:並列思考の前に並列性を考える
大規模言語モデル(LLM)の推論において、複数の推論パスを並列生成して多数決で統合する「並列思考」は有効ですが、全データに一律の大規模な並列数(予算)を割り当てると、多くのサンプルで計算資源が無駄になる「オーバースケーリングの呪い」が発生します。
TL;DR(結論)
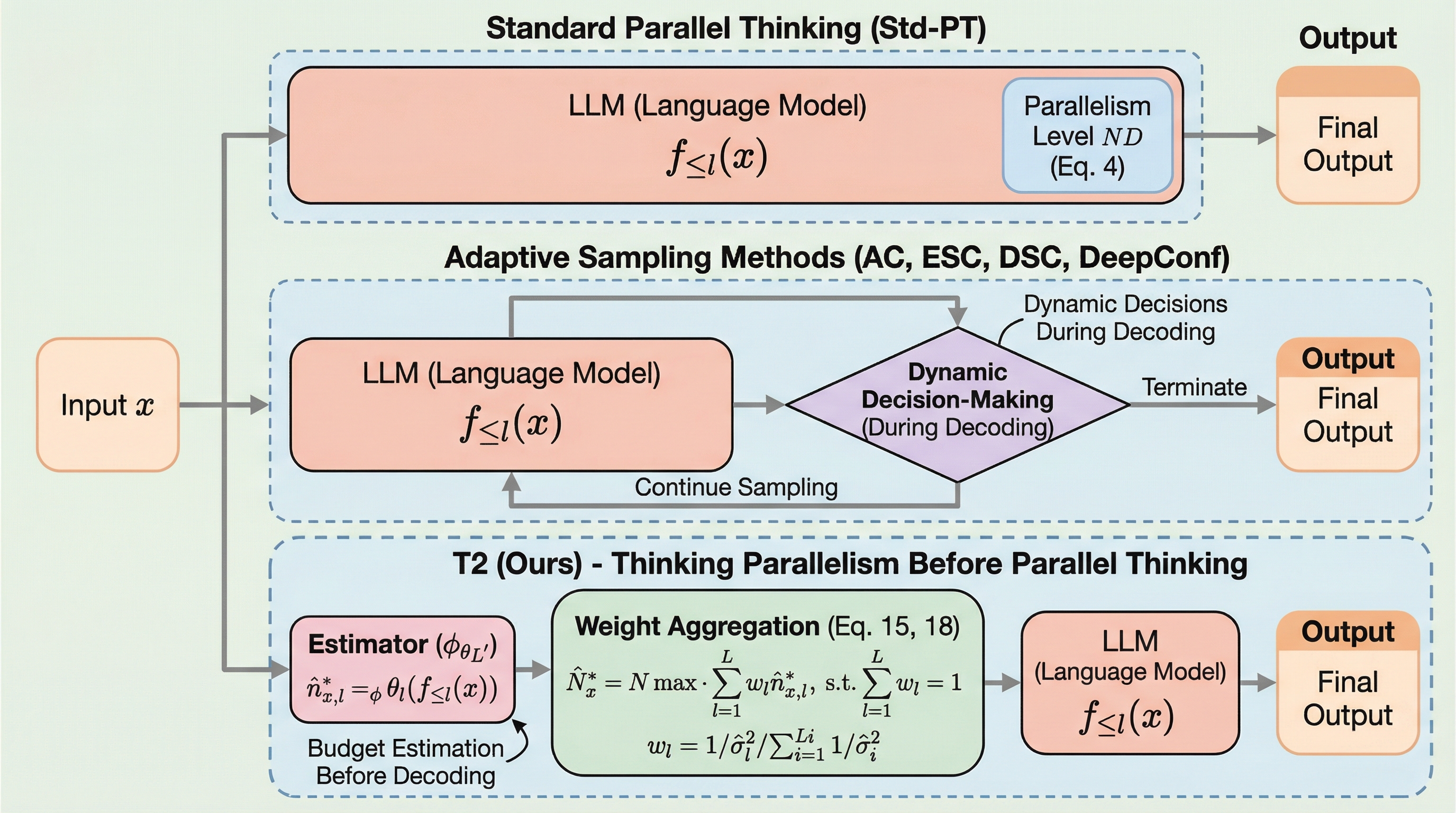
大規模言語モデル(LLM)の推論において、複数の推論パスを並列生成して多数決で統合する「並列思考」は有効ですが、全データに一律の大規模な並列数(予算)を割り当てると、多くのサンプルで計算資源が無駄になる「オーバースケーリングの呪い」が発生します。 本研究では、サンプルの性質を5つのタイプに分類し、特定の「並列数を増やすほど精度が上がるタイプ」が全体の予算を引き上げている一方で、他の多くのサンプルでは少数の並列数で十分であることを定量的に明らかにしました。 この問題を解決するため、デコーディング前にモデルの内部表現から各サンプルに最適な並列数を予測する軽量な手法「T2」を提案し、高い推論精度を維持しながら計算コストと遅延を大幅に削減することに成功しました。
なぜこの問題か
近年、大規模言語モデル(LLM)の推論能力を最大限に引き出すために、テスト時の計算量を増やす「テストタイムスケーリング(TTS)」という手法が注目を集めています。その中でも「並列思考(Parallel Thinking)」は、同じ入力に対して複数の独立した推論パスを並列に生成し、多数決などの手法で最終的な回答を選択する強力なパラダイムとして知られています。通常、システム全体の評価においては、データセット全体の精度を最大化するために、すべてのサンプルに対して一律の大きな並列数(予算)$N$が設定されます。しかし、現実のデータセットに含まれるサンプルは極めて不均一です。あるサンプルにとっては非常に簡単な問題であり、ごく少ない並列数で正解に到達できる一方で、別のサンプルは非常に難解で、膨大な並列数を費やしても正解できない場合があります。 このようにサンプルの難易度や特性が異なるにもかかわらず、システム全体の精度を追求して一律に大きな予算を投入すると、多くのサンプルにおいて「本来は少ない予算で済むはずなのに、過剰な計算資源を消費する」という状況が生まれます。…
核心:何を提案したのか
本研究の核心的な提案は、デコーディング(回答生成)を開始する前に、そのサンプルに最適な並列数を予測する「T2(Thinking Parallelism Before Parallel Thinking)」という手法です。従来の並列思考が「まず並列に考えてから結果を統合する」というアプローチだったのに対し、T2は「並列に考える前に、どの程度の並列度が必要かを考える」という一段上のメタ的な思考を導入します。具体的には、LLMの内部にある「潜在的な表現(Latent Representations)」を活用します。モデルが質問文を読み込んだ直後の内部状態には、その問題の難易度や、どの程度の試行錯誤が必要かという情報が隠されているという点に着目しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related