探索経験の再利用による効率的なテスト時スケーリング:Do Not Waste Your Rollouts
大規模言語モデルの推論能力を高めるテスト時スケーリングにおいて、従来の探索手法が各試行(ロールアウト)を使い捨てにしていた非効率性を指摘し、中間的な洞察を蓄積して再利用する「Recycling Search Experience(RSE)」を提案している。
TL;DR(結論)
大規模言語モデルの推論能力を高めるテスト時スケーリングにおいて、従来の探索手法が各試行(ロールアウト)を使い捨てにしていた非効率性を指摘し、中間的な洞察を蓄積して再利用する「Recycling Search Experience(RSE)」を提案している。 RSEは、モデル自身の自己評価能力を活用して過去の試行から「肯定的な経験(検証済みの事実)」と「否定的な経験(失敗のパターン)」を抽出し、共有の経験バンクに保存することで、冗長な計算の省略と行き止まりの回避を可能にする。 数学的推論ベンチマークを用いた検証では、RSEは既存の強力なベースラインを同等の計算コストで一貫して上回り、特に小規模なモデルでも大規模モデルに匹敵する性能を引き出すなど、極めて高いスケーリング効率を実証した。
なぜこの問題か
大規模言語モデル(LLM)の性能向上において、推論時に追加の計算資源を投入して解の探索空間を広げる「テスト時スケーリング(TTS)」が重要なパラダイムとなっている。しかし、既存の探索戦略には情報の利用効率という面で共通のボトルネックが存在する。現在の主要な手法は、ロールアウト(推論の試行)を「使い捨てのサンプル」として扱っており、各試行で得られた貴重な中間的な洞察が、試行終了後に事実上破棄されている。このシステム的な「記憶の欠如」により、モデルは膨大な試行を通じて、すでに発見された結論を何度も再導出したり、既知の行き止まりを繰り返し探索したりするという、大規模な計算の冗長性を引き起こしている。 具体的に、既存のスケーリング手法は以下の3つのカテゴリに分類されるが、いずれも課題を抱えている。第一に「並列スケーリング」は、独立した多数のロールアウトによって探索の幅を広げるが、異なるブランチ間での中間的な洞察の共有がほとんど行われない。第二に「逐次スケーリング」は、単一のドラフトを繰り返し改善するが、蓄積される情報は構造化されていない文脈履歴に限られる。…
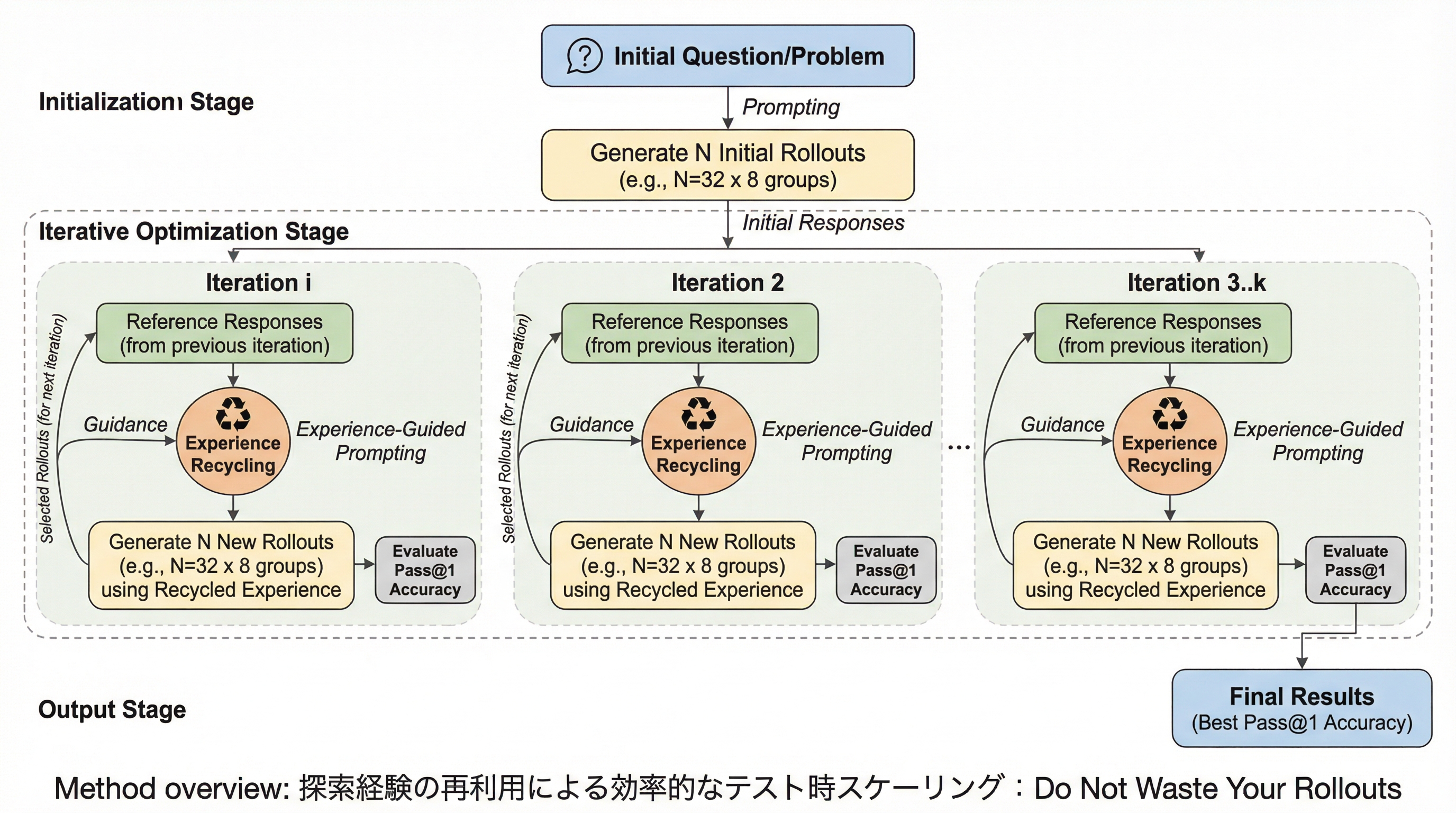
核心:何を提案したのか
本論文では、ロールアウトを使い捨てにせず、探索プロセスを導くための再利用可能な経験へと変換する、自己誘導型かつトレーニング不要の戦略「Recycling Search Experience(RSE)」を提案している。RSEの核心は、探索を累積的なプロセスとして捉え、以前の軌跡から得られた価値ある洞察を、その後の探索をガイドするためにフィードバックする仕組みにある。この手法は、外部の監視や追加の学習を必要とせず、モデルが持つ「自身の推論を批評し、価値ある経験を特定する」という本質的な自己評価能力を活用している。 RSEは、抽出された情報を「経験バンク(Experience Bank)」という共有の知識ベースに集約し、後続の探索をこのバンクの内容に条件付ける。これにより、主に2つの形態の経験再利用が実現される。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related