ILRR: マスク型拡散言語モデルのための推論時ステアリング手法
離散拡散言語モデル(DLM)の生成プロセスを推論時に制御するための、学習を必要としない新しいフレームワーク「反復的潜在表現洗練(ILRR)」が提案されました。この手法は、生成中のシーケンスの内部活性化状態を、単一の参照シーケンスの活性化状態と動的に位置合わせすることで、特定の属性やスタイルを効果的に転送します。
TL;DR(結論)
離散拡散言語モデル(DLM)の生成プロセスを推論時に制御するための、学習を必要としない新しいフレームワーク「反復的潜在表現洗練(ILRR)」が提案されました。この手法は、生成中のシーケンスの内部活性化状態を、単一の参照シーケンスの活性化状態と動的に位置合わせすることで、特定の属性やスタイルを効果的に転送します。 既存のサンプリング手法と比較して計算オーバーヘッドを最小限に抑えつつ、属性の正確性を10%から60%向上させ、長いテキスト生成にも対応する空間変調ステアリング機能を備えています。モデルの重みを変更することなく、ポジティブな感情や特定の文体を生成結果に自然に反映させることが可能であり、LLaDAやMDLMといった最新のアーキテクチャにおいてその有効性が実証されました。 本手法は、デノイジングの各ステップにおいて追加のフォワードパスを1回行うだけで動作するため、非常に効率的であり、リアルタイム性が求められる環境でも高度なテキスト制御が可能になります。これにより、計算リソースが限られた状況下でも、安全性の制約や多様なスタイルの適用を柔軟に行うことができるようになり、離散拡散モデルの実用性が大幅に高まりました。
なぜこの問題か
離散拡散言語モデル(DLM)は、テキスト生成における非自己回帰的な代替案として近年大きな注目を集めています。モデルのスケーリングやトレーニング方法の進歩により、LLaDAやMDLMといったアーキテクチャは、数学的推論やコード合成などの複雑なタスクにおいて、従来の自己回帰型モデルに匹敵する能力を示しています。しかし、自己回帰型モデルでは生成の制御手法が確立されている一方で、DLMにおける推論時の効果的な制御メカニズムはまだ十分に探索されていません。既存のDLM向け制御手法には、サンプリングレベルでのガイダンス手順や軌道最適化メカニズムが含まれますが、これらは計算コストが高いという課題があります。 具体的には、複数の候補シーケンスを並列に保持したり、反復的な再サンプリングを行ったりする必要があり、効果的な制御を実現するために多大な計算リソースを消費します。パラメータの微調整(ファインチューニング)を行わずに、安全性の制約やスタイルの属性を柔軟に変調できる、低コストで動的なステアリング手法が求められていました。特に、モデルの内部表現を直接操作する潜在空間でのステアリングは、計算効率と適応性の両立において大きな可能性を秘めています。…
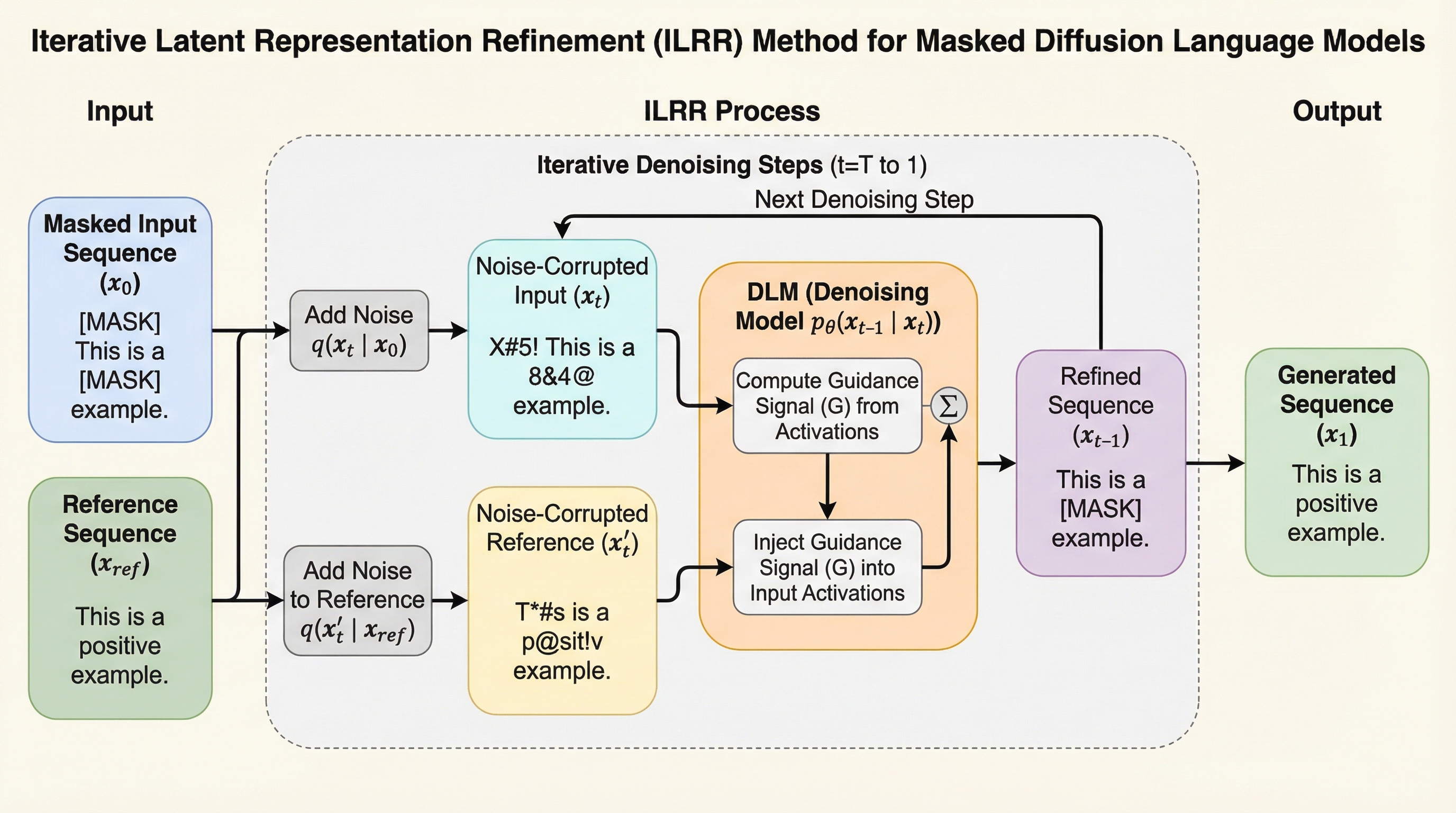
核心:何を提案したのか
本研究では、単一の参照シーケンスを使用してDLMを制御する、学習不要のフレームワーク「反復的潜在表現洗練(ILRR)」を提案しています。ILRRは、画像生成などの連続拡散モデルで用いられる手法(ILVR)から着想を得ており、これを離散的なテキストドメインに適応させたものです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related