FIT: 継続的なLLMアンラーニングにおける破滅的忘却の克服
FITは、大規模言語モデル(LLM)が連続的なデータ削除要求を受けた際に発生する「破滅的忘却」を防ぐための新しい学習フレームワークである。 この手法は、重複情報のフィルタリング、重要度に応じたアルゴリズムの適応的選択、そして影響の大きい層に限定した更新という3つの戦略を統合することで、モデルの性能維持と確実な情報消去を両立させている。 また、個人情報や著作権、有害コンテンツを網羅した評価ベンチマーク「PCH」と、消去の度合いと性能維持を統合的に測る新指標を提案し、300件もの連続的な要求に対しても既存手法を凌駕する堅牢性を実証した。
TL;DR(結論)
FITは、大規模言語モデル(LLM)が連続的なデータ削除要求を受けた際に発生する「破滅的忘却」を防ぐための新しい学習フレームワークである。 この手法は、重複情報のフィルタリング、重要度に応じたアルゴリズムの適応的選択、そして影響の大きい層に限定した更新という3つの戦略を統合することで、モデルの性能維持と確実な情報消去を両立させている。 また、個人情報や著作権、有害コンテンツを網羅した評価ベンチマーク「PCH」と、消去の度合いと性能維持を統合的に測る新指標を提案し、300件もの連続的な要求に対しても既存手法を凌駕する堅牢性を実証した。
なぜこの問題か
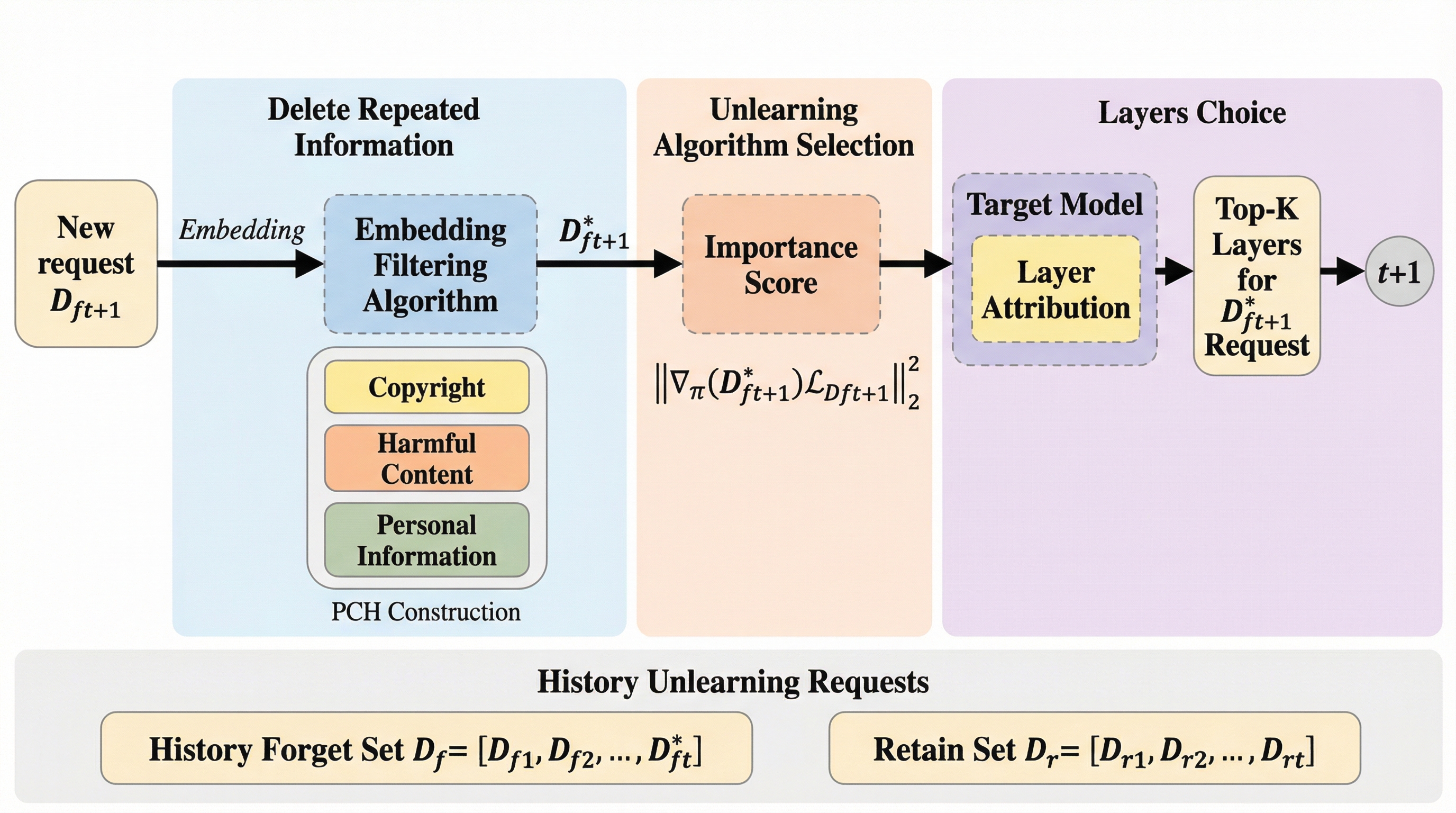
大規模言語モデル(LLM)は、インターネット上の膨大なデータを学習することで高度な能力を獲得しているが、その一方でプライバシーの侵害や著作権の抵触、有害な情報の生成といった深刻なリスクを抱えている。これに対応するため、欧州のGDPR(一般データ保護規則)やカリフォルニア州のCCPA(カリフォルニア州消費者プライバシー法)などの法規制では、特定のデータをモデルから消去する「忘れられる権利」の行使が求められている。しかし、モデルを最初から再学習させることは計算コストの面で現実的ではなく、学習済みのモデルから特定の知識のみを効率的に取り除く「マシンアンラーニング(機械的な忘却)」の技術が不可欠となっている。 従来のアンラーニング研究の多くは、一度にすべての消去対象を処理する「シングルショット」の設定に焦点を当てていた。しかし、現実の運用環境では、削除要求は時間の経過とともに逐次的に、かつ大量に発生する。このような「継続的なアンラーニング」の状況下で既存の手法をそのまま適用すると、要求が蓄積するにつれてモデルの汎用的な能力が急激に低下する「破滅的忘却」という現象が引き起こされることが明らかになった。…
核心:何を提案したのか
本研究では、継続的なアンラーニングにおけるモデルの崩壊を防ぎ、長期的な安定性を確保するためのフレームワーク「FIT」を提案している。FITという名称は、その中核をなす3つの主要コンポーネントである「フィルタリング(Filtering)」、「重要度を考慮した更新(Importance-aware updates)」、「ターゲットを絞った層の特定(Targeted layer attribution)」の頭文字に由来している。このフレームワークは、削除要求が次々と届く状況下で、モデルのパラメータが過度に変動することを抑制し、必要な情報だけを精密に削ぎ落とすことを目的としている。 第一の柱である「フィルタリング」では、意味的に重複する削除要求を事前に排除する。これにより、似たような勾配更新が何度も繰り返されることで生じる、特定の語彙や概念に対する過剰な抑制を防ぐ。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related