オーバースケーリングの呪いを打破する:並列的思考の前に並列性を考える
大規模言語モデルの推論において、複数の回答を生成して統合する「並列的思考」は精度を向上させますが、全問題に一律の大きな並列度を割り当てると、簡単な問題などで計算資源が無駄になる「オーバースケーリングの呪い」が発生することを明らかにしました。
TL;DR(結論)
大規模言語モデルの推論において、複数の回答を生成して統合する「並列的思考」は精度を向上させますが、全問題に一律の大きな並列度を割り当てると、簡単な問題などで計算資源が無駄になる「オーバースケーリングの呪い」が発生することを明らかにしました。 この呪いを定量化した結果、データセット全体の精度を最大化しようとすると、個別のサンプルレベルでは計算予算の50%から80%以上が冗長になっているという深刻な実態が判明し、システム全体の効率を著しく低下させていることが示されました。 解決策として提案された「T2」は、デコーディング前にモデル内部の潜在表現から各問題に最適な並列度を予測する軽量な推定器を導入し、精度を維持したまま推論コスト、遅延、メモリ使用量を大幅に削減することに成功した革新的な手法です。
なぜこの問題か
近年、大規模言語モデル(LLM)の推論能力をさらに引き出すための手法として、テスト時の計算量を増加させる「テストタイム・スケーリング(TTS)」が大きな注目を集めています。その代表的なアプローチの一つが「並列的思考(Parallel Thinking)」であり、これはモデルに複数の独立した推論パスを並列に生成させ、多数決(Majority Voting)などの手法で最終的な回答を選択するものです。通常、システム全体の精度を最大化するために、データセット内のすべてのサンプルに対して一律に大きな並列度(N)が割り当てられることが一般的です。しかし、実際にはサンプルごとに難易度や特性が異なる「サンプルの不均一性」が存在しており、これが大きな問題を引き起こします。一部の問題は非常に小さな並列度で十分に正解に到達できる一方で、他の複雑な問題は大きな並列度を必要とします。システム全体の精度を優先して大きなNを設定すると、小さなNで済むはずの簡単なサンプルに対しても過剰な計算資源が投入されることになり、これが「予算の冗長性」を招きます。…
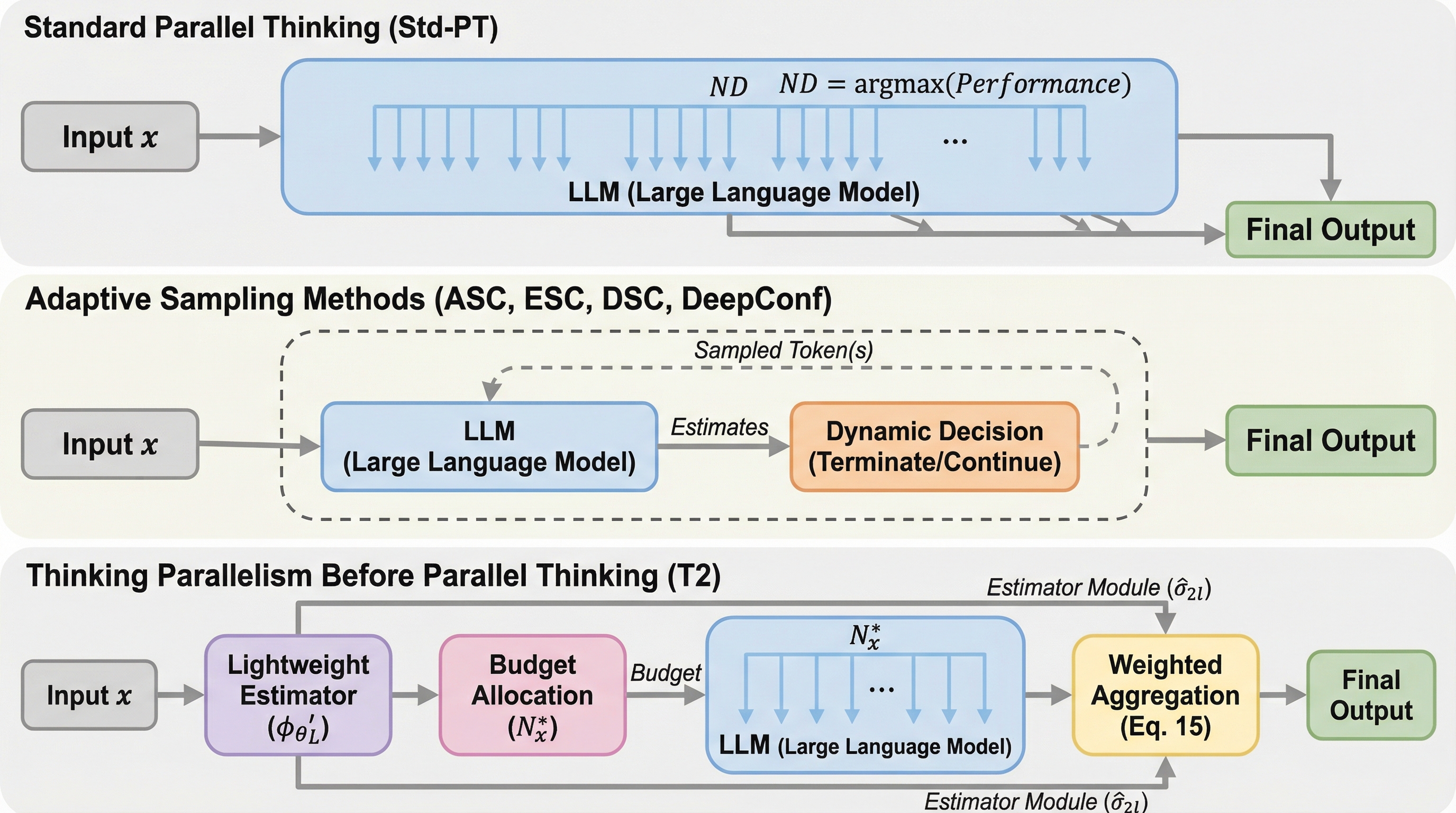
核心:何を提案したのか
本研究の核心は、オーバースケーリングの呪いを打破するために提案された「T2(Thinking Parallelism Before Parallel Thinking)」という革新的な手法にあります。T2の基本的なアイデアは、実際にテキストを生成(デコーディング)し始める前に、入力された問題の難易度や特性をモデル自身が「思考」し、その問題に最適な並列度を事前に予測することにあります。従来のようにデータセット全体に対して固定されたグローバルな並列度を適用するのではなく、サンプルごとに最適化された並列度を適応的に割り当てることで、計算資源の無駄を最小限に抑えることが可能になります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related