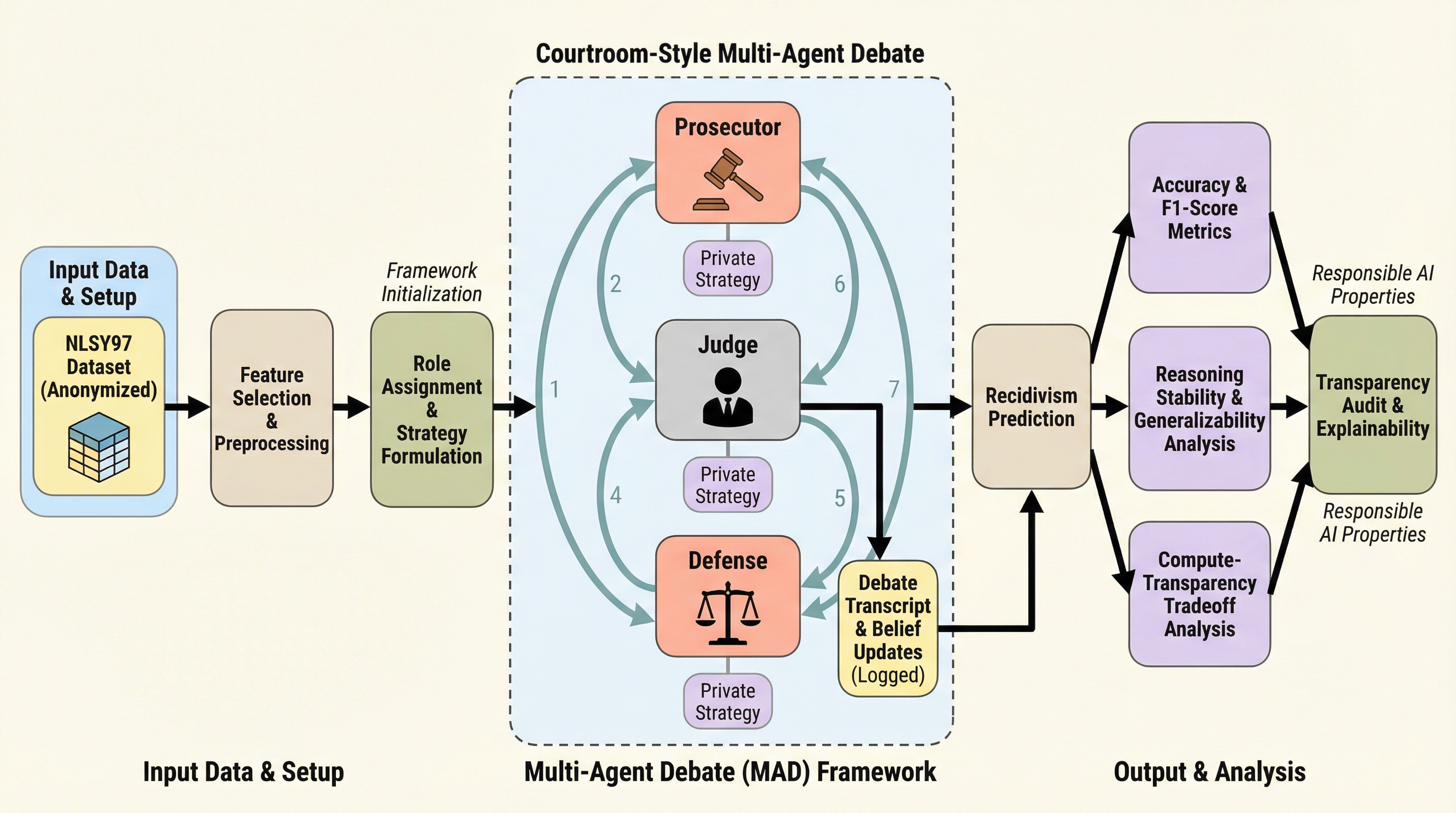
AgenticSimLaw:説明可能な意思決定のための法廷シミュレーション型マルチエージェント
AgenticSimLawは、検察官、弁護人、裁判官という明確な役割を持つエージェントが法廷形式で議論を行うマルチエージェント・フレームワークであり、ブラックボックス化しがちなAIの意思決定プロセスを透明化し、監査可能なものにすることを目指している。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
AgenticSimLawは、検察官、弁護人、裁判官という明確な役割を持つエージェントが法廷形式で議論を行うマルチエージェント・フレームワークであり、ブラックボックス化しがちなAIの意思決定プロセスを透明化し、監査可能なものにすることを目指している。
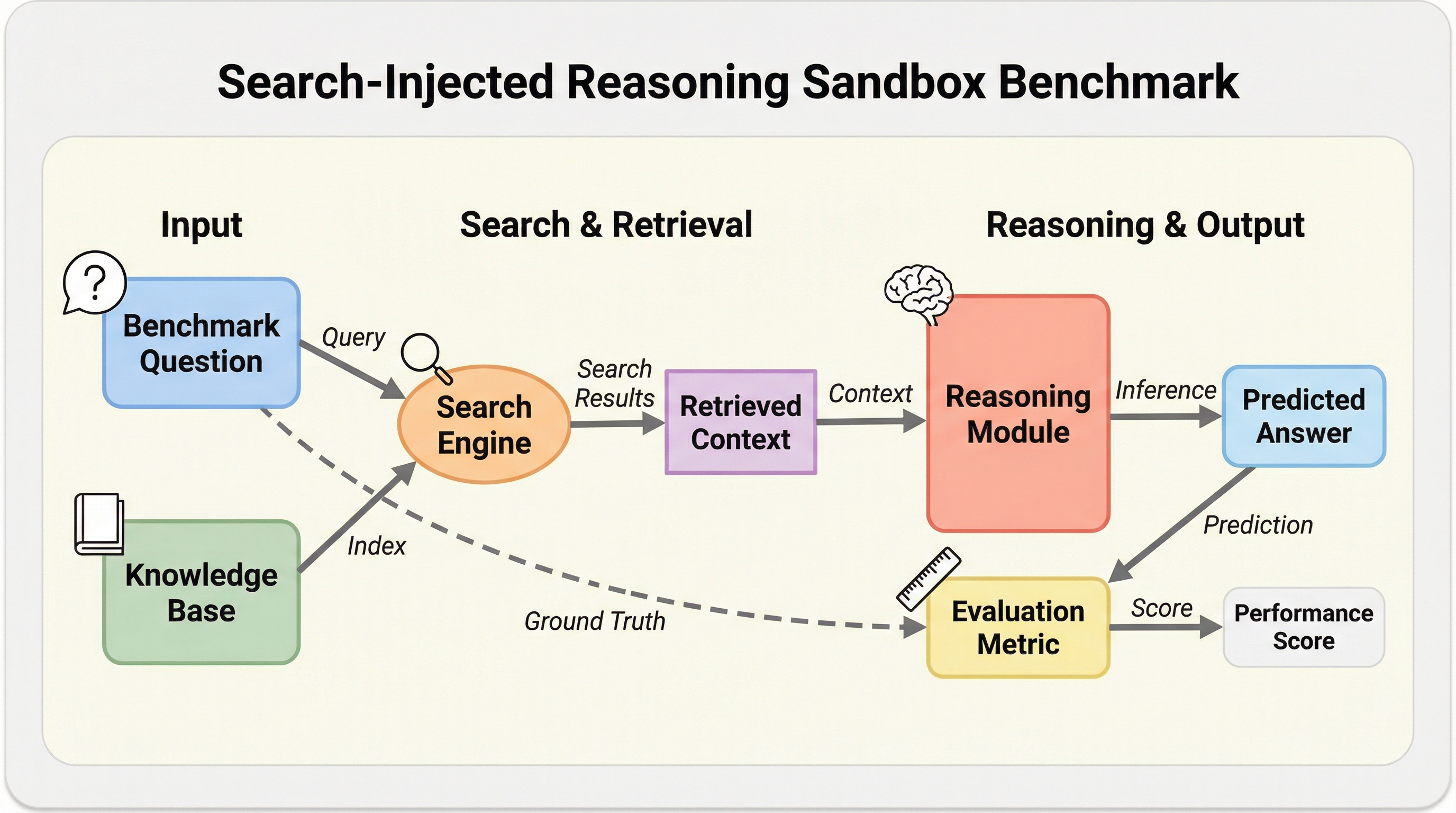
DeR2は、大規模言語モデルが未知の科学的情報に対して推論を行う能力を、検索プロセスから切り離して評価するための新しいベンチマークである。従来の評価手法では検索の失敗か推論の失敗かを判別できなかったが、本手法は2023年から2025年の最新の理論的論文に基づき、情報のアクセスレベルを4段階に分けることでエラーの原因を詳細に特定する。 評価設定として、命令のみ、概念のみ、関連文書のみ、全文書セットの4つのレジームを導入し、モデルがどの段階で性能を低下させているかを「検索損失」と「推論損失」として数値化する。これにより、モデルが学習済みの知識で解いているのか、あるいは提供された証拠を適切に処理して解いているのかを厳密に検証するプロトコルを確立している。 検証の結果、GPT-5.1やGemini-3-Proといった最新モデルでも、文書が与えられると推論モードへの切り替えに失敗する「モード切替の脆弱性」や、概念を正しく認識しても適用できない「構造的な概念の誤用」が明らかになった。このサンドボックスは、検索能力と推論能力の統合における現在の限界を可視化し、次世代AIの開発に向けた重要な指針を提供する。
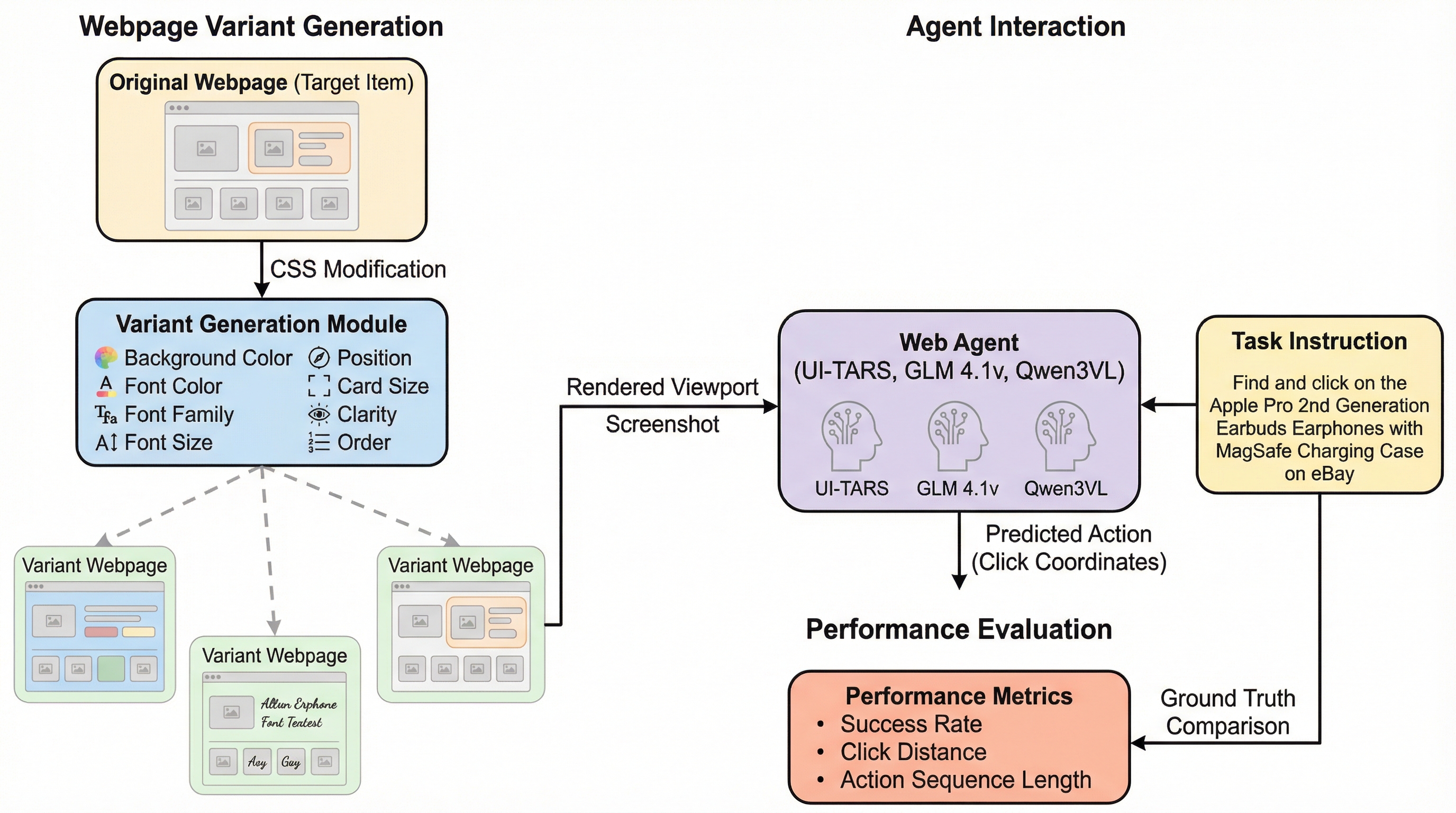
本研究は、視覚と言語を統合したVLMベースのウェブエージェントが、ウェブページ上の視覚的属性(色、サイズ、配置など)からどのような影響を受けて意思決定を行うかを定量的に評価するパイプライン「VAF」を提案しました。
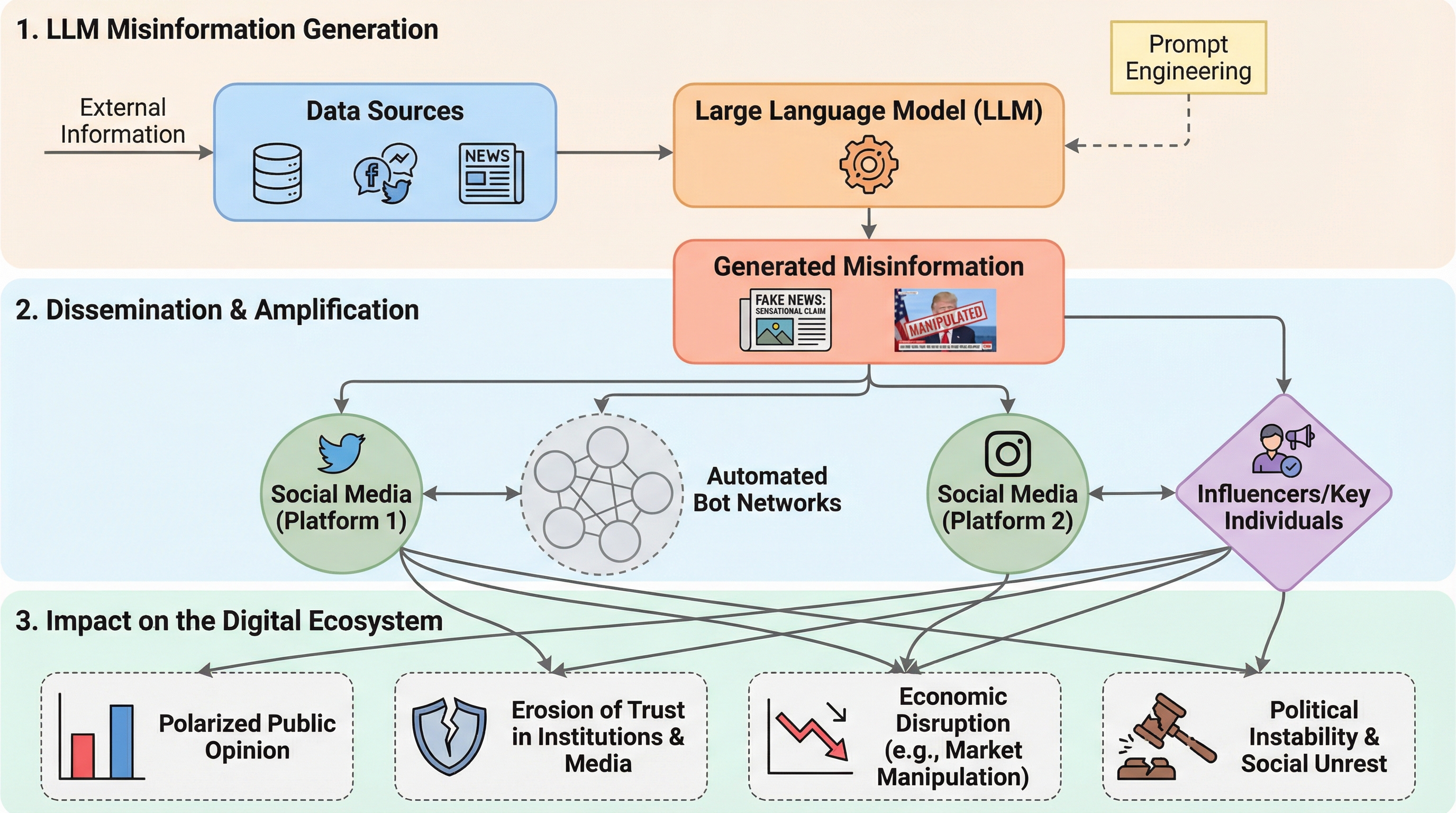
生成AIの進化により、誤情報の生成が「産業化された欺瞞」へと変貌し、デジタルエコシステムの信頼性を根本から揺るがす深刻な事態となっている。本研究では、AI生成ニュースに対する人間の認識を評価する「JudgeGPT」と、研究用の刺激生成エンジンである「RogueGPT」を提案し、実験的なパイプラインを構築した。
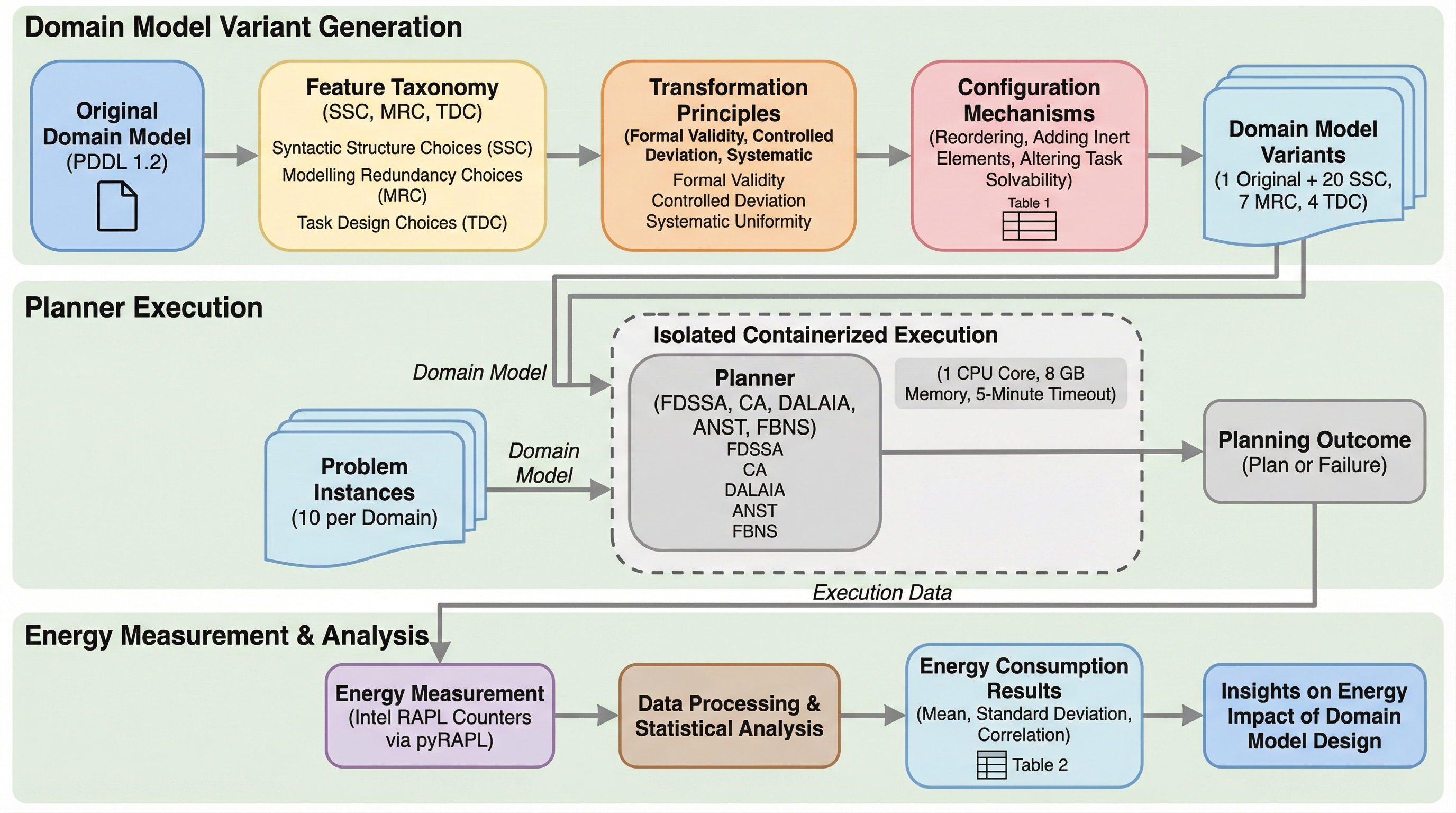
AI計画法において、アルゴリズムとは独立して定義されるドメインモデルの設計が、システムの消費エネルギーに極めて大きな影響を及ぼすことを、5つのプランナーと5つのベンチマークを用いた実験により明らかにした。
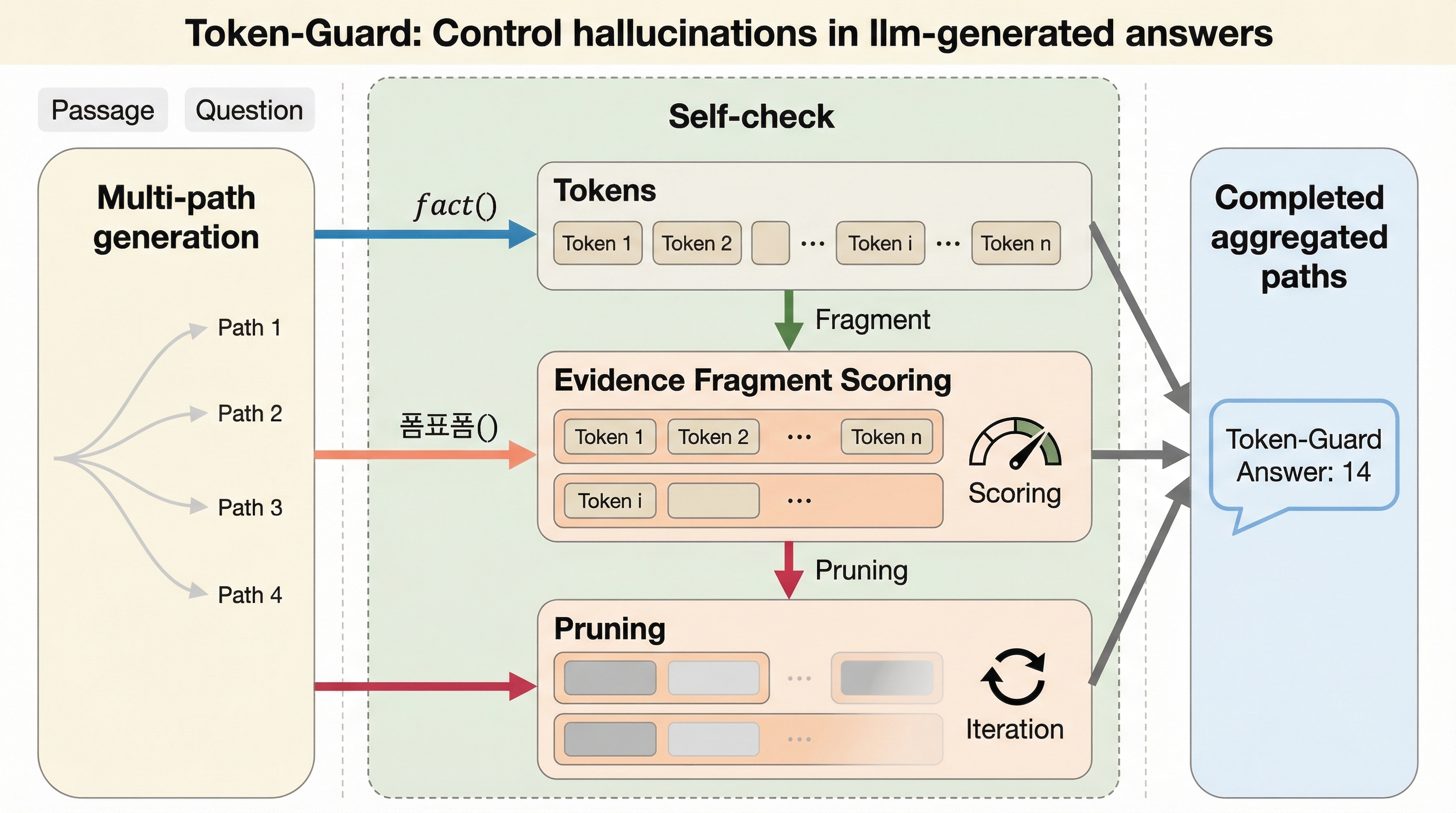
大規模言語モデル(LLM)が事実に基づかない情報を生成するハルシネーション問題を解決するため、生成の各ステップでトークン単位の検証を行う新しいデコーディング手法「Token-Guard」が提案されました。
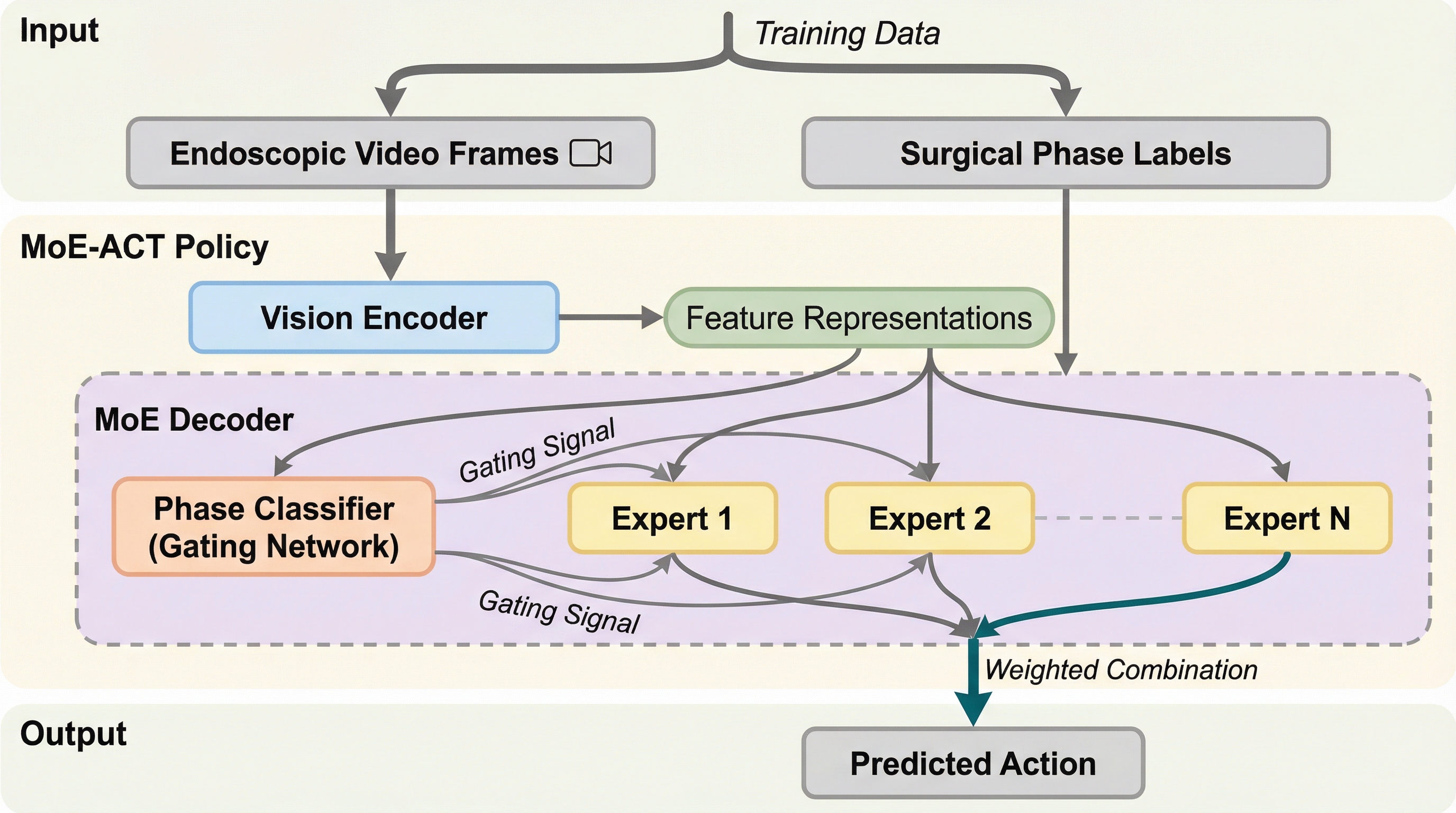
手術支援ロボットの自律操作を向上させるため、タスクを論理的なフェーズに分割して学習する「MoE-ACT」という新しいアーキテクチャを提案し、少量のデータで高度な操作を可能にした。 この手法は、専門家混合モデル(MoE)を軽量なアクションデコーダに統合し、外科医の指示に基づく腸管の把持や牽引といった複雑な共同作業において、従来手法や大規模モデルを大幅に上回る成功率を達成している。 ステレオ内視鏡画像のみを利用しながら、未知の視点や照明条件の変化、さらには生体組織へのゼロショット転移に対しても高い汎用性と頑健性を示し、実際の臨床現場への応用に向けた強力なフレームワークを提供している。
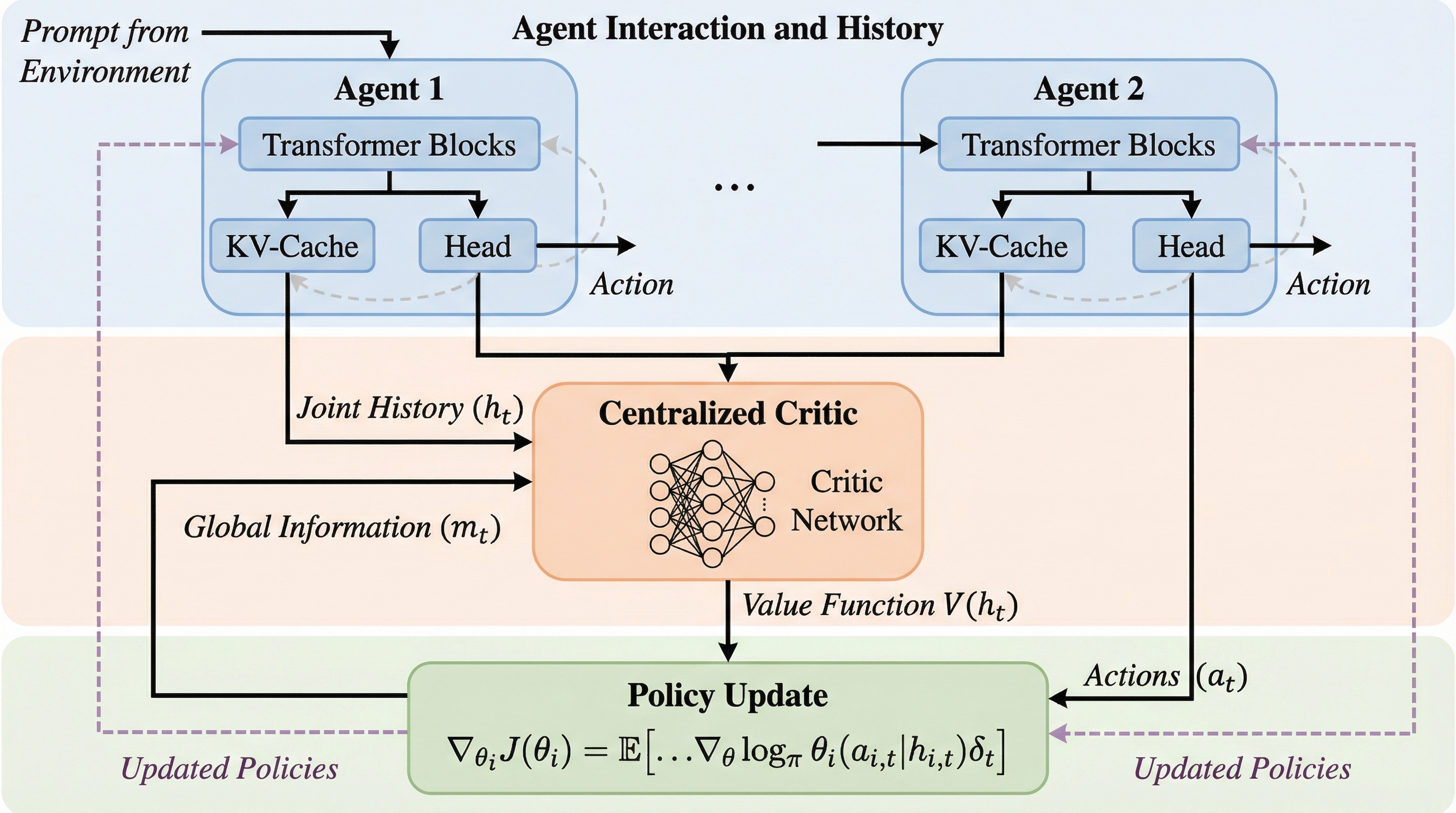
分散型の大規模言語モデル(LLM)エージェント間の協調を最適化するため、マルチエージェントActor-Critic(MAAC)手法であるCoLLM-CCとCoLLM-DCが提案されました。 従来のモンテカルロ法は、長期的なタスクや報酬が疎な設定において勾配の分散が極めて大きく、学習効率が著しく低下するという課題がありましたが、本手法は批判者(Critic)を導入することでこの問題を解決します。 執筆、コーディング、Minecraftでの建築という多様なドメインでの検証の結果、集中型批判者を用いるCoLLM-CCは、特に複雑で長期的な対話が必要なタスクにおいて、既存手法を大幅に上回る性能と収束の安定性を示しました。
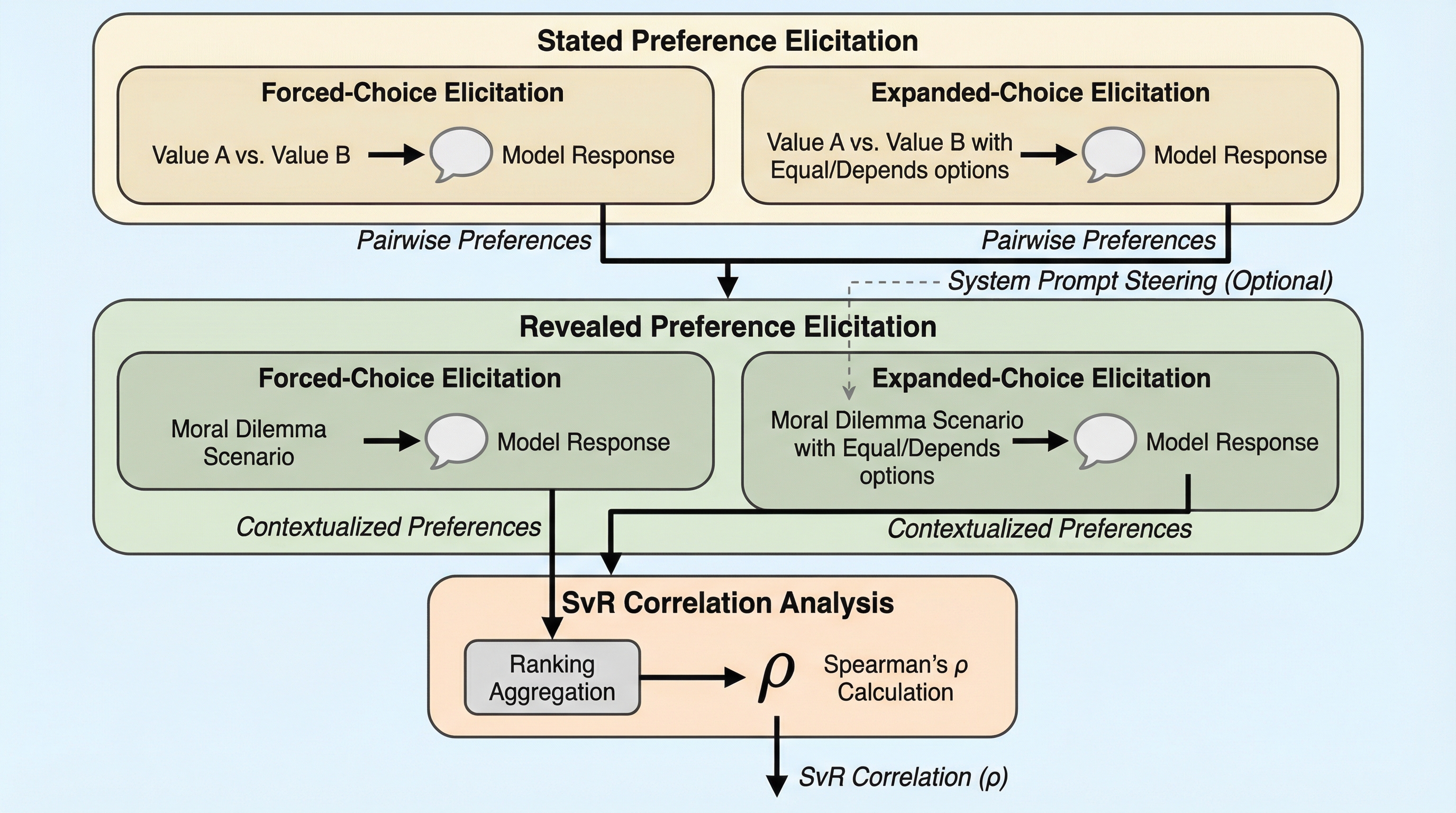
言語モデルが抽象的に掲げる価値観(表明された選好)と、具体的な状況下での行動(顕在化した選好)の間に生じる「言行不一致(SvRギャップ)」は、評価プロトコルに大きく依存することが判明しました。 表明された選好の調査において「中立」や「棄権」の選択肢を許容すると、モデルの真の価値体系が抽出されやすくなり、強制二択の場合よりも実際の行動との相関が大幅に向上することが24のモデルを用いた検証で示されました。 一方で、実際の行動選択においても中立を許容すると多くのモデルが判断を回避して相関が消失することや、自身の価値観をプロンプトで提示する介入策が多値の状況では効果が薄いことも明らかになりました。
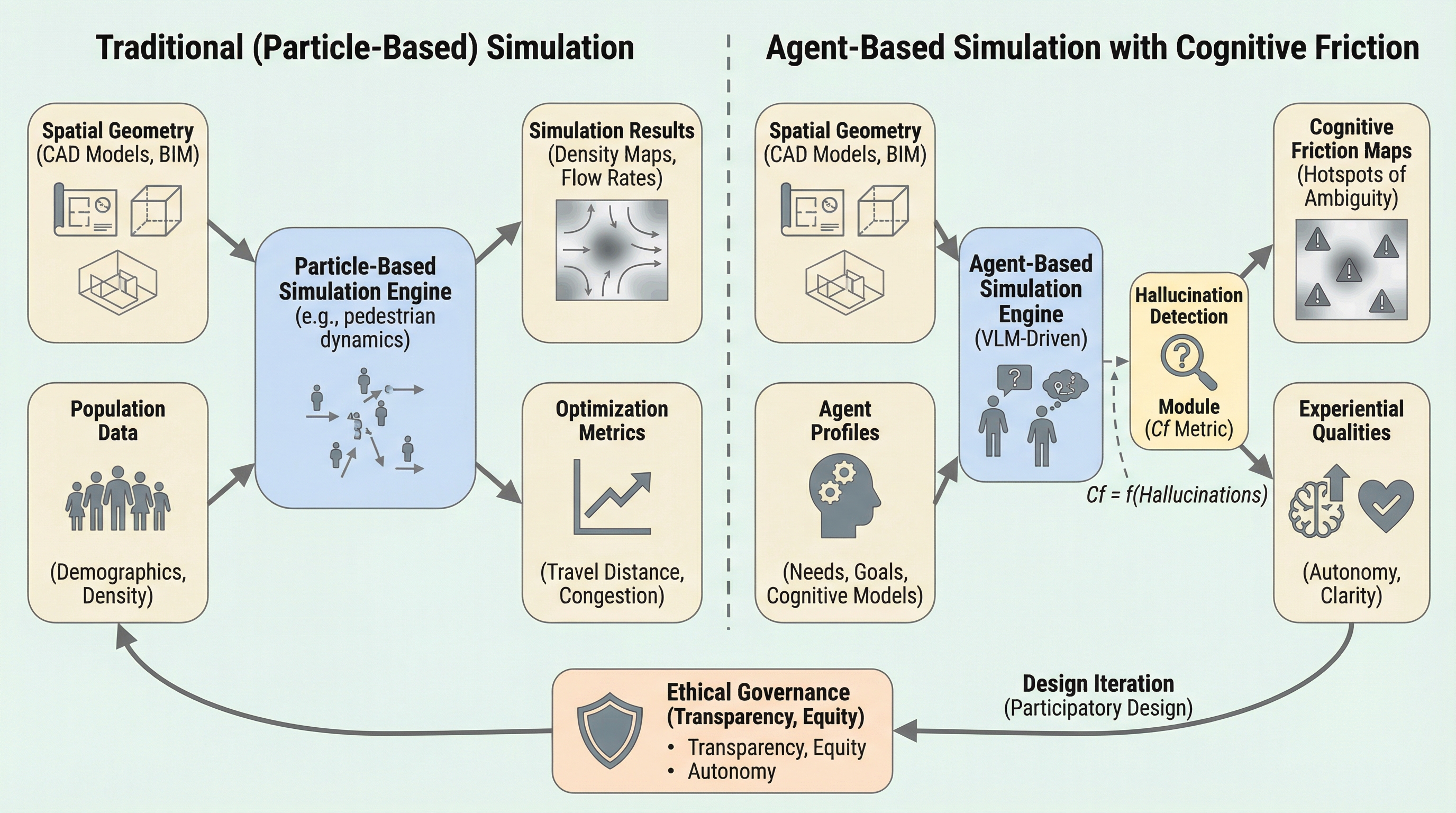
従来の建築シミュレーションが人間を物理法則に従う「粒子」として扱ってきたのに対し、本研究は大規模マルチモーダルモデルを活用し、人間を意味を理解し推論を行う「エージェント」としてモデル化する「エージェント的環境シミュレーション」を提案している。