MoE-ACT: 教師あり混合エキスパートによる手術模倣学習方策の向上
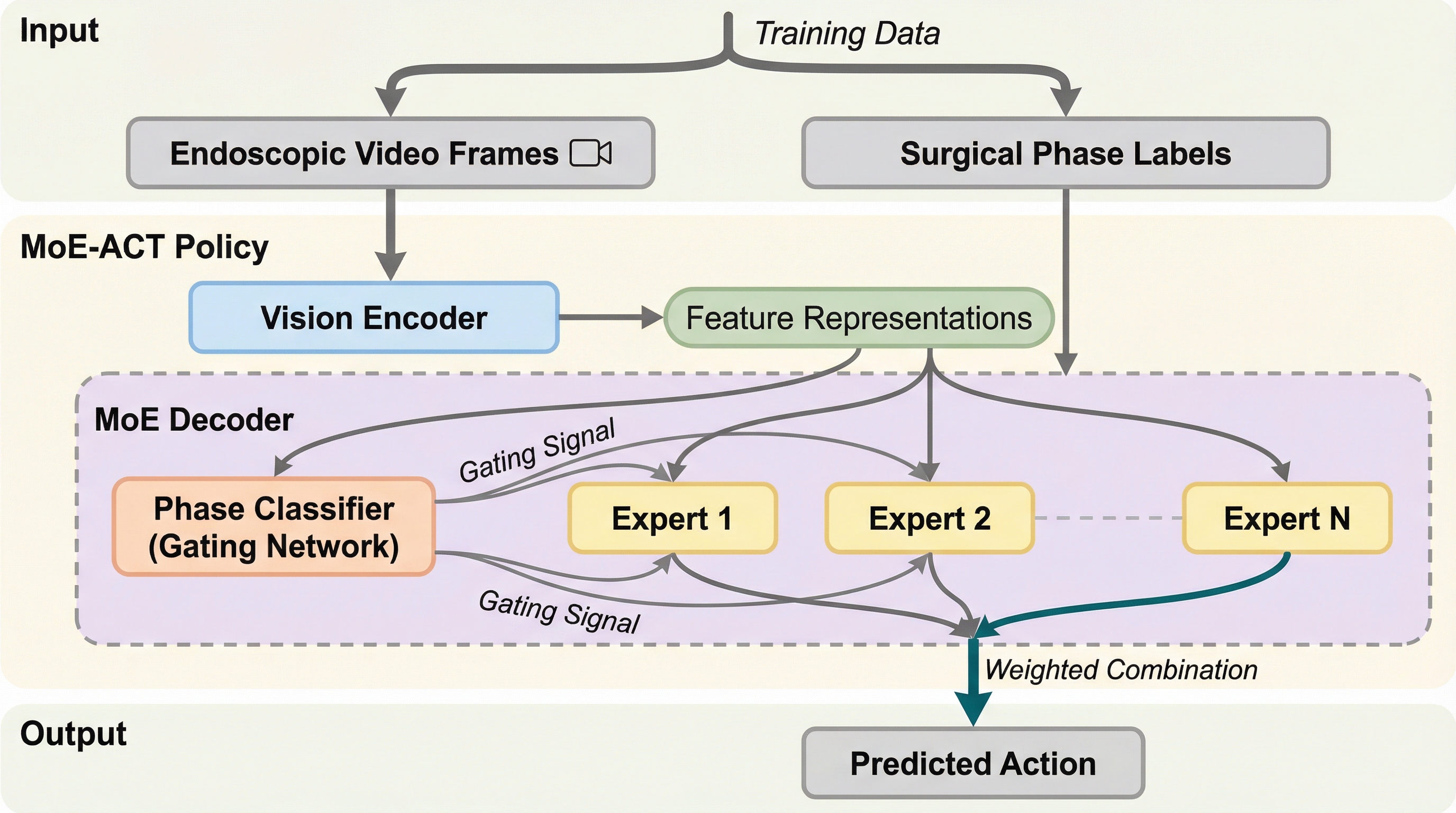
手術支援ロボットの自律操作を向上させるため、タスクを論理的なフェーズに分割して学習する「MoE-ACT」という新しいアーキテクチャを提案し、少量のデータで高度な操作を可能にした。 この手法は、専門家混合モデル(MoE)を軽量なアクションデコーダに統合し、外科医の指示に基づく腸管の把持や牽引といった複雑な共同作業において、従来手法や大規模モデルを大幅に上回る成功率を達成している。 ステレオ内視鏡画像のみを利用しながら、未知の視点や照明条件の変化、さらには生体組織へのゼロショット転移に対しても高い汎用性と頑健性を示し、実際の臨床現場への応用に向けた強力なフレームワークを提供している。
TL;DR(結論)
手術支援ロボットの自律操作を向上させるため、タスクを論理的なフェーズに分割して学習する「MoE-ACT」という新しいアーキテクチャを提案し、少量のデータで高度な操作を可能にした。 この手法は、専門家混合モデル(MoE)を軽量なアクションデコーダに統合し、外科医の指示に基づく腸管の把持や牽引といった複雑な共同作業において、従来手法や大規模モデルを大幅に上回る成功率を達成している。 ステレオ内視鏡画像のみを利用しながら、未知の視点や照明条件の変化、さらには生体組織へのゼロショット転移に対しても高い汎用性と頑健性を示し、実際の臨床現場への応用に向けた強力なフレームワークを提供している。
なぜこの問題か
現代の医療現場では、人口の高齢化に伴って手術の需要が急速に高まっている一方で、外科医や医療スタッフの不足が世界的な深刻な課題となっている。この問題を解決する手段として、手術支援ロボットによる術中操作の自律化が強く期待されているが、外科手術の領域には特有の困難が数多く存在する。まず、倫理的および規制上の厳しい制約があるため、ロボットの学習に不可欠なデモンストレーションデータを大量に収集することが極めて困難である。一般的なロボット学習では数千から数万のデータを必要とする場合が多いが、手術室の時間コストや専門医の関与を考慮すると、そのような大規模なデータセットを構築することは現実的ではない。また、手術現場は視覚的なノイズが非常に多く、臓器の複雑な変形や出血による閉塞、照明条件の不安定さなど、動的な環境変化に対応しなければならない。既存の汎用的な模倣学習手法や、大規模なデータセットで訓練された視覚言語アクションモデル(VLA)は、一般的な物体操作には優れているものの、外科手術のような極めて高い精度と安全性が求められる領域では十分な性能を発揮できないことが判明している。…
核心:何を提案したのか
本研究では、タスクのフェーズ構造を明示的に活用する「教師あり専門家混合モデル(Supervised Mixture-of-Experts: MoE)」を統合した、新しいアクションデコーダポリシーである「MoE-ACT」を提案している。この手法の核心は、複雑な手術タスクを論理的な複数のフェーズに分解し、それぞれのフェーズに特化した専門のネットワーク(エキスパート)を割り当てることで、学習の効率と操作の精度を劇的に向上させた点にある。具体的には、軽量で高性能な「Action Chunking Transformer (ACT)」をベースアーキテクチャとして採用し、その上にフェーズごとの動作を司る複数のエキスパートと、それらを適切に切り替えるゲーティングネットワークを構築している。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related