プロトコルの破壊:ツール統合型LLMエージェントにおけるモデルコンテキストプロトコル仕様のセキュリティ分析とプロンプトインジェクションの脆弱性
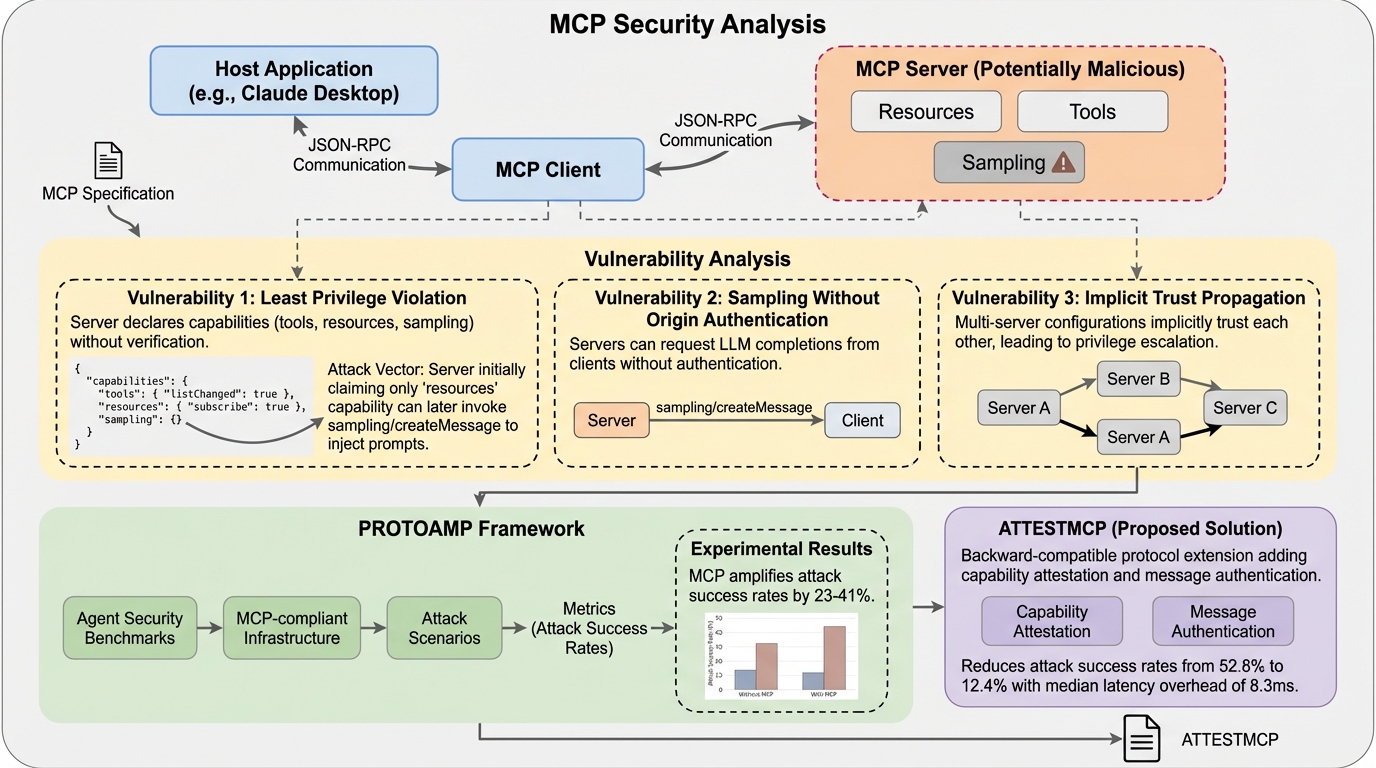
Anthropicが2024年11月に発表したModel Context Protocol(MCP)は、AIエージェントと外部ツールを統合する標準規格として急速に普及していますが、権限証明の欠如、送信元認証のないサンプリング機能、および複数サーバー間での暗黙的な信頼伝播という3つの根本的な設計上の脆弱性が存在することが本研究の分析によって明らかになりました。 研究チームは、既存のセキュリティベンチマークをMCP環境に適応させた評価フレームワーク「PROTOAMP」を開発し、847件の攻撃シナリオを用いて実験を行った結果、MCPのアーキテクチャ自体が攻撃の成功率を非MCP環境と比較して23%から41%も増幅させていることを定量的に示し、その危険性を証明しました。 これらの深刻な脆弱性への対策として、後方互換性を持つプロトコル拡張案「ATTESTMCP」が提案され、暗号化による権限証明やメッセージ認証、送信元のタグ付けを導入することで、攻撃成功率を52.8%から12.4%へと大幅に低減しつつ、追加される遅延を実用的な範囲内に抑えられることが実証されました。
TL;DR(結論)
Anthropicが2024年11月に発表したModel Context Protocol(MCP)は、AIエージェントと外部ツールを統合する標準規格として急速に普及していますが、権限証明の欠如、送信元認証のないサンプリング機能、および複数サーバー間での暗黙的な信頼伝播という3つの根本的な設計上の脆弱性が存在することが本研究の分析によって明らかになりました。 研究チームは、既存のセキュリティベンチマークをMCP環境に適応させた評価フレームワーク「PROTOAMP」を開発し、847件の攻撃シナリオを用いて実験を行った結果、MCPのアーキテクチャ自体が攻撃の成功率を非MCP環境と比較して23%から41%も増幅させていることを定量的に示し、その危険性を証明しました。 これらの深刻な脆弱性への対策として、後方互換性を持つプロトコル拡張案「ATTESTMCP」が提案され、暗号化による権限証明やメッセージ認証、送信元のタグ付けを導入することで、攻撃成功率を52.8%から12.4%へと大幅に低減しつつ、追加される遅延を実用的な範囲内に抑えられることが実証されました。
なぜこの問題か
大規模言語モデル(LLM)を外部ツールやデータソースと連携させ、自律的に複雑なタスクを実行させるAIエージェントの開発は、現在の人工知能研究における最も重要な進展の一つとなっています。2024年11月にAnthropic社が発表したModel Context Protocol(MCP)は、こうしたAIエージェントと外部ツールの統合を簡素化するためのオープンな標準規格として登場し、わずか数ヶ月の間にClaude DesktopやCursorといった主要なプラットフォームに採用されました。現在、コミュニティによって開発されたMCPサーバーは5,000を超えており、エコシステムは爆発的に拡大していますが、その急速な普及の一方で、プロトコルの設計自体が抱えるセキュリティ上のリスクについては、これまで厳密な分析が行われてきませんでした。 既存のセキュリティ研究の多くは、個別の実装におけるバグや、一般的なプロンプトインジェクション攻撃に焦点を当ててきましたが、MCPのような「プロトコルの仕様そのもの」が攻撃をどのように助長し、増幅させるかという視点は欠落していました。…
核心:何を提案したのか
本研究の核心的な貢献は、大きく分けて三つの要素で構成されています。第一に、MCP仕様(v1.0)に対する世界初の体系的なセキュリティ分析を実施し、実装に依存しないプロトコルレベルの脆弱性を三つのクラスに分類して特定したことです。具体的には、サーバーが自己申告のみで任意の権限を主張できてしまう「権限証明の欠如」、サーバーがユーザーになりすましてプロンプトを注入できる「送信元認証のないサンプリング」、そして複数のサーバーが接続された際に一つのサーバーの侵害が他へ…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related