長文文脈を一発で LoRA 化する Doc-to-LoRA 入門
- 2602.15902 は、長い文書を毎回コンテキストに入れ直す代わりに、その文書を読んで即座に LoRA アダプタへ変換し、以後の質問では元文書を再投入せずに答えられるようにする Doc-to-LoRA (D2L) を提案した研究です。 - 核心は、従来の context distillation をその都度最適化で回すのではなく、「文脈から LoRA を生成する処理そのもの」をハイパーネットワークとしてメタ学習し、1回の forward pass で近似する点にあります。 - Needle-in-a-Haystack では学習時より 4 倍超長い文脈でほぼ完全な検索性能を維持し、実 QA でも標準的な context distillation より速く・省メモリに内部化できる一方、学習自体は 8 台の H200 を 5 日使う重い前処理が必要です。
TL;DR(結論)
2602.15902は、長い文書を毎回コンテキストに入れ直す代わりに、その文書を読んで即座に LoRA アダプタへ変換し、以後の質問では元文書を再投入せずに答えられるようにするDoc-to-LoRA (D2L)を提案した研究です。- 核心は、従来の context distillation をその都度最適化で回すのではなく、「文脈から LoRA を生成する処理そのもの」をハイパーネットワークとしてメタ学習し、1回の forward pass で近似する点にあります。
- Needle-in-a-Haystack では学習時より 4 倍超長い文脈でほぼ完全な検索性能を維持し、実 QA でも標準的な context distillation より速く・省メモリに内部化できる一方、学習自体は 8 台の H200 を 5 日使う重い前処理が必要です。
なぜこの問題か
長い文脈をそのまま LLM に読ませる運用は、いまの実務ではかなり重いです。文書 QA、長い仕様書の理解、ユーザー固有の設定や履歴の反映、エージェントの長期メモリなど、どれも「同じ文脈を何度も読み直す」構造を持っています。しかし Transformer は注意計算が二次的に重くなり、推論時の KV キャッシュも膨らみます。そのため、長い文脈ほどレイテンシとメモリ消費が急増し、しかも長くなるほど応答品質まで落ちやすいという問題があります。
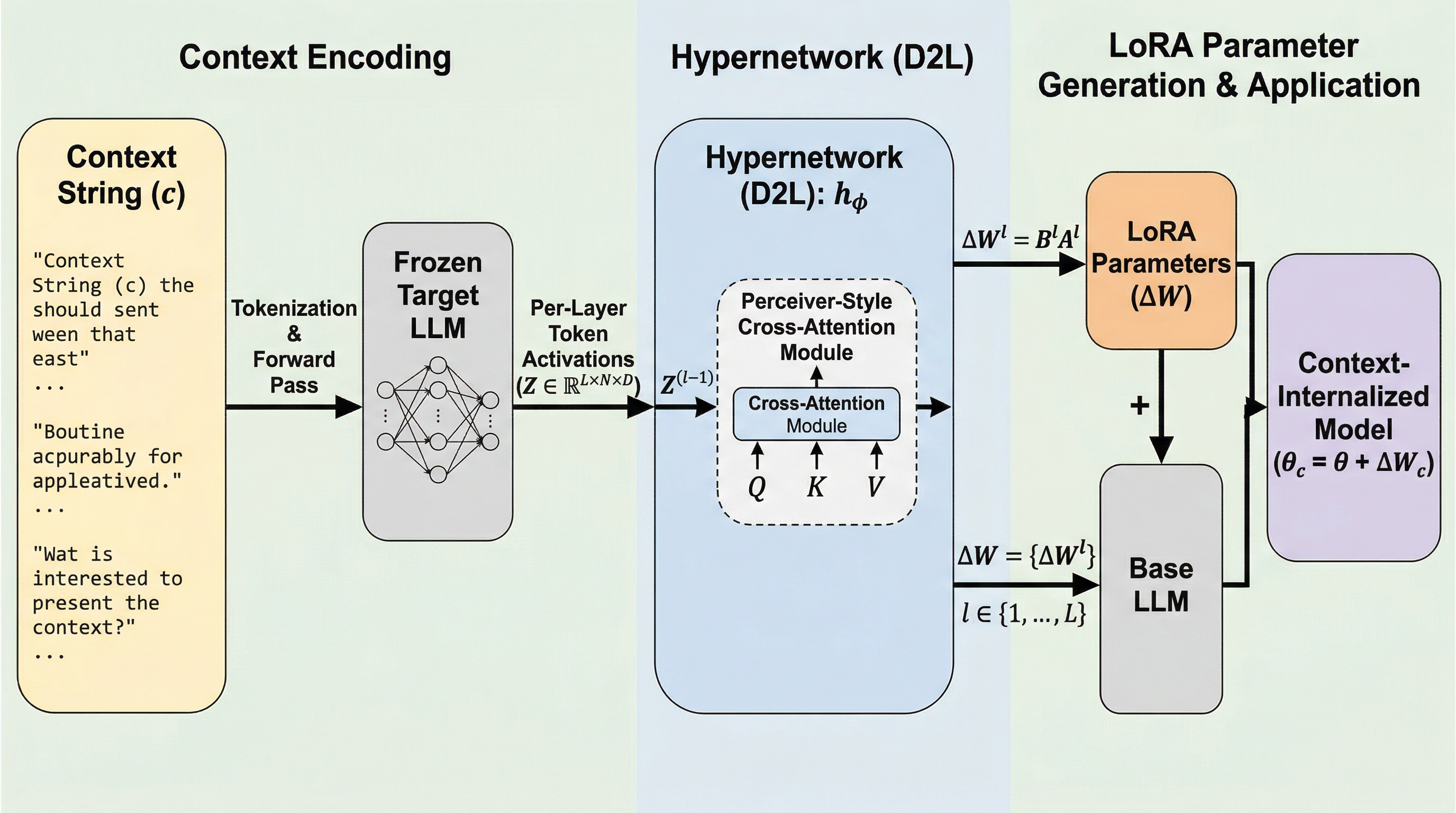
核心:何を提案したのか
提案手法 Doc-to-LoRA (D2L) の核心は、context distillation の結果として得られる重み更新を、毎回 SGD で求めるのではなく、ハイパーネットワークが近似的に一発生成する点です。入力は文書や長いプロンプトなどの文脈で、出力は対象 LLM に差し込む LoRA アダプタです。これにより、最初に一度だけ文脈を読ませて LoRA を作れば、その後の質問では元文脈を再読込みせずに回答できます。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related