Token-Guard: 自己チェックによるトークンレベルのハルシネーション制御
大規模言語モデル(LLM)が事実に基づかない情報を生成するハルシネーション問題を解決するため、生成の各ステップでトークン単位の検証を行う新しいデコーディング手法「Token-Guard」が提案されました。
TL;DR(結論)
大規模言語モデル(LLM)が事実に基づかない情報を生成するハルシネーション問題を解決するため、生成の各ステップでトークン単位の検証を行う新しいデコーディング手法「Token-Guard」が提案されました。 この手法は、潜在空間でのトークン・スコアリング、意味的なまとまりであるセグメント単位の評価、そして局所的な修正とグローバルな反復を組み合わせることで、外部知識への依存を抑えつつ生成精度を向上させます。 実験では、Llama-3.1やQwen3などのモデルにおいて、従来の手法を上回る高い正確性と論理的一貫性を達成し、最大で16.3%の精度向上を記録したことが示されており、計算リソースを抑えた信頼性の高い出力が可能です。
なぜこの問題か
大規模言語モデルは自然言語処理において大きな成功を収めていますが、知識集約的なタスクや専門的なシナリオにおいて、入力と矛盾する内容を生成するハルシネーションという深刻な課題を抱えています。 この問題を軽減するために、外部知識を利用する検索拡張生成(RAG)や、人間のフィードバックによる強化学習(RLHF)といった手法が提案されてきましたが、これらは膨大な計算リソースや大規模な微調整を必要とするという欠点があります。 一方で、生成時のデコーディングプロセスを工夫する手法は比較的軽量ですが、既存のChain-of-Thought(CoT)やTree-of-Thought(ToT)などは、ハルシネーションを明示的に制御する仕組みが不足していました。 具体的には、第一にトークンレベルでの詳細なチェック機構が存在しないため、推論の途中で発生した小さなエラーが後の生成プロセス全体に伝播し、最終的な回答を誤らせるリスクがあります。 第二に、潜在空間におけるハルシネーションのリスクが数値として明示的に定量化されていないため、モデルがどのトークンを選択すべきかという判断が不安定になりやすいという問題がありました。…
核心:何を提案したのか
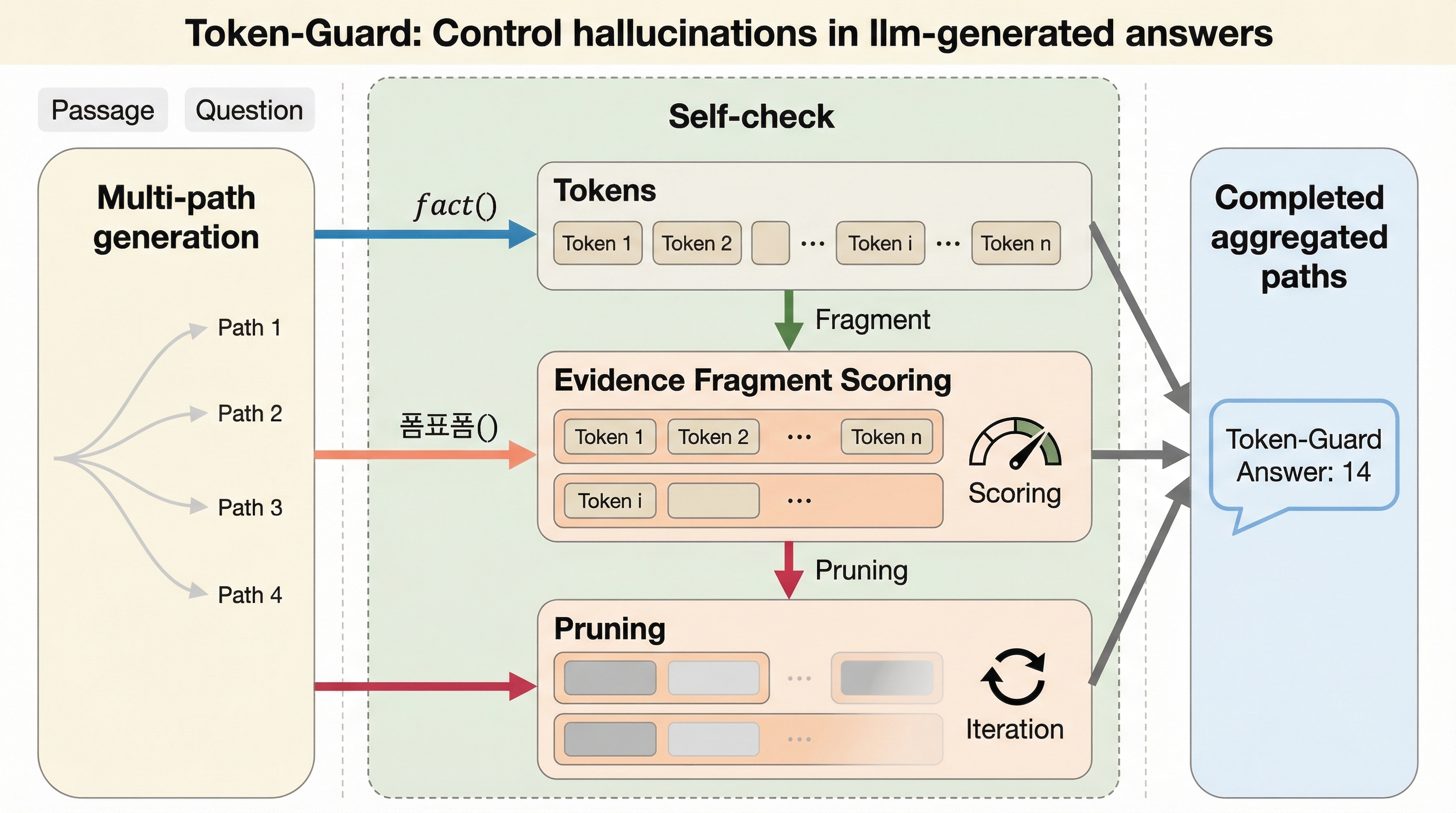
本論文では、デコーディングの過程でトークンレベルの自己チェックを行う「Token-Guard」という新しいフレームワークが提案されました。 この手法の核心は、生成の各ステップにおいてモデル内部で検証を行い、ハルシネーションを含んだトークンが伝播する前に検出して抑制することにあります。 Token-Guardは主に3つの革新的な機能を備えており、一つ目は潜在空間における候補トークンのスコアリングと、信頼性の低いトークンの枝刈りを行うトークンレベルの制御機能です。 二つ目は、関連するトークンを「セグメント」としてグループ化し、そのセグメントごとにハルシネーションのリスクを明示的にスコアリングすることで、より正確な情報の選択をガイドする機能です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related