Gained in Translation: Privileged Pairwise Judges Enhance Multilingual Reasoning
現在の大規模言語モデルは英語以外の言語、特に学習データが少ない低リソース言語において推論能力が著しく低下するという深刻な課題を抱えていますが、本研究は対象言語のデータを一切使わずに英語の翻訳データと強化学習のみで能力を向上させる「SP3F」という革新的な二段階フレームワークを提案しました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
現在の大規模言語モデルは英語以外の言語、特に学習データが少ない低リソース言語において推論能力が著しく低下するという深刻な課題を抱えていますが、本研究は対象言語のデータを一切使わずに英語の翻訳データと強化学習のみで能力を向上させる「SP3F」という革新的な二段階フレームワークを提案しました。
Reflectは、大規模言語モデルを自然言語の原則(憲法)に適合させるための、追加学習や人間による注釈を一切必要としない推論時フレームワークである。 初期回答の生成、自己評価、自己批判、最終修正という4段階のプロセスをインコンテキストで実行することで、モデルの判断を透明化し、複雑な価値観への適合性を大幅に向上させる。
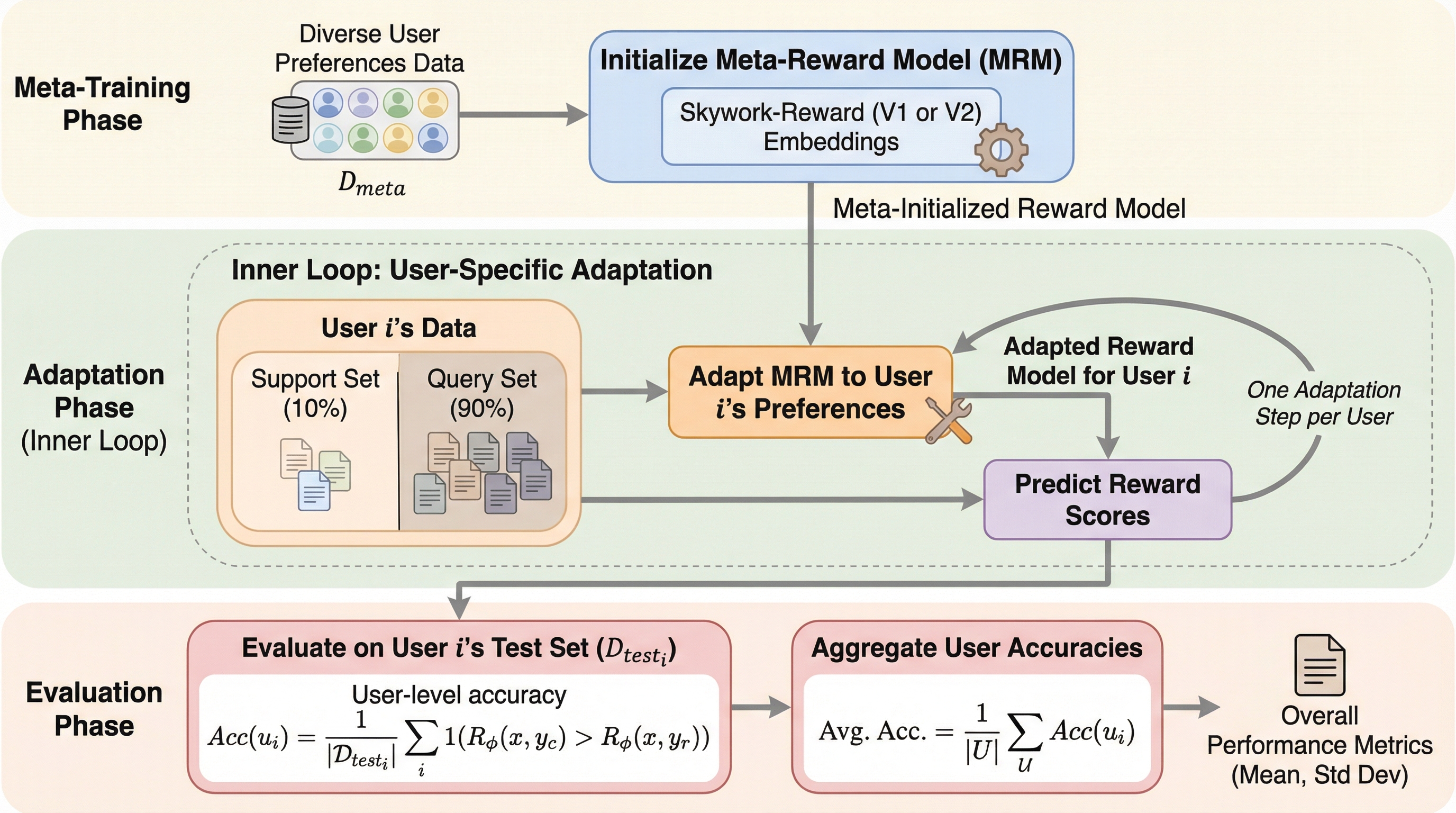
大規模言語モデル(LLM)を個々のユーザーの多様な好みに適応させるため、メタ学習の枠組みを用いた新しい報酬モデリング手法「Meta Reward Modeling(MRM)」が提案されました。この手法は、少数のフィードバックから未知のユーザーの意図を迅速に学習する「学習のプロセス」そのものを最適化することで、従来の個別化手法が抱えていたデータの希少性や過学習、未知のユーザーへの対応といった課題を根本から解決します。さらに、学習が困難なユーザーを優先的に扱う「Robust Personalization Objective(RPO)」を導入することで、特異な価値観を持つユーザーに対しても一貫して高い精度と堅牢なパフォーマンスを保証し、公平で精緻なパーソナライズを実現しました。
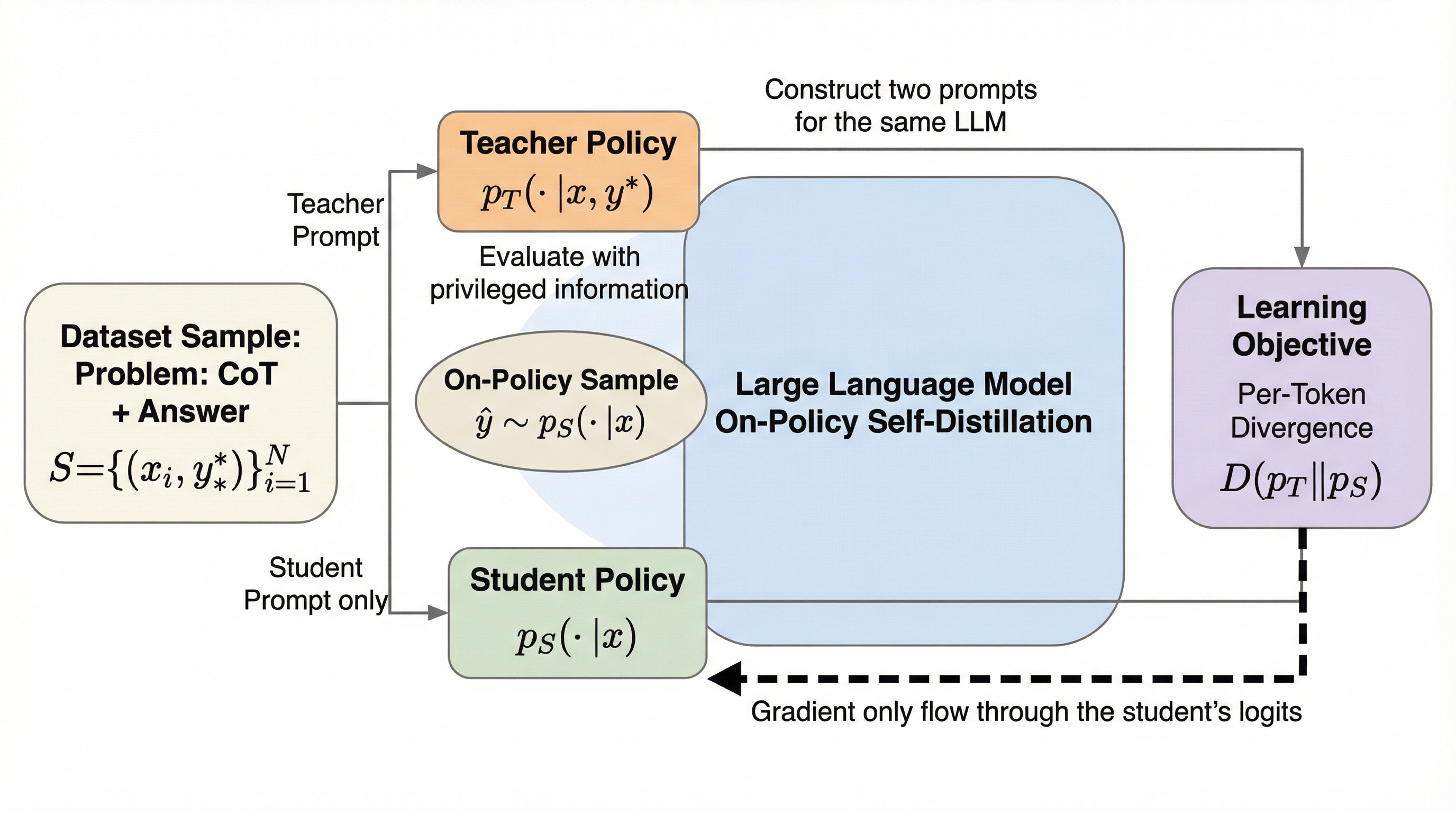
大規模言語モデルの推論能力を向上させるため、外部の教師モデルを必要とせず、単一のモデルが特権情報を活用して自分自身を教育する「オンポリシー自己蒸留(OPSD)」という新しい学習枠組みが提案されました。
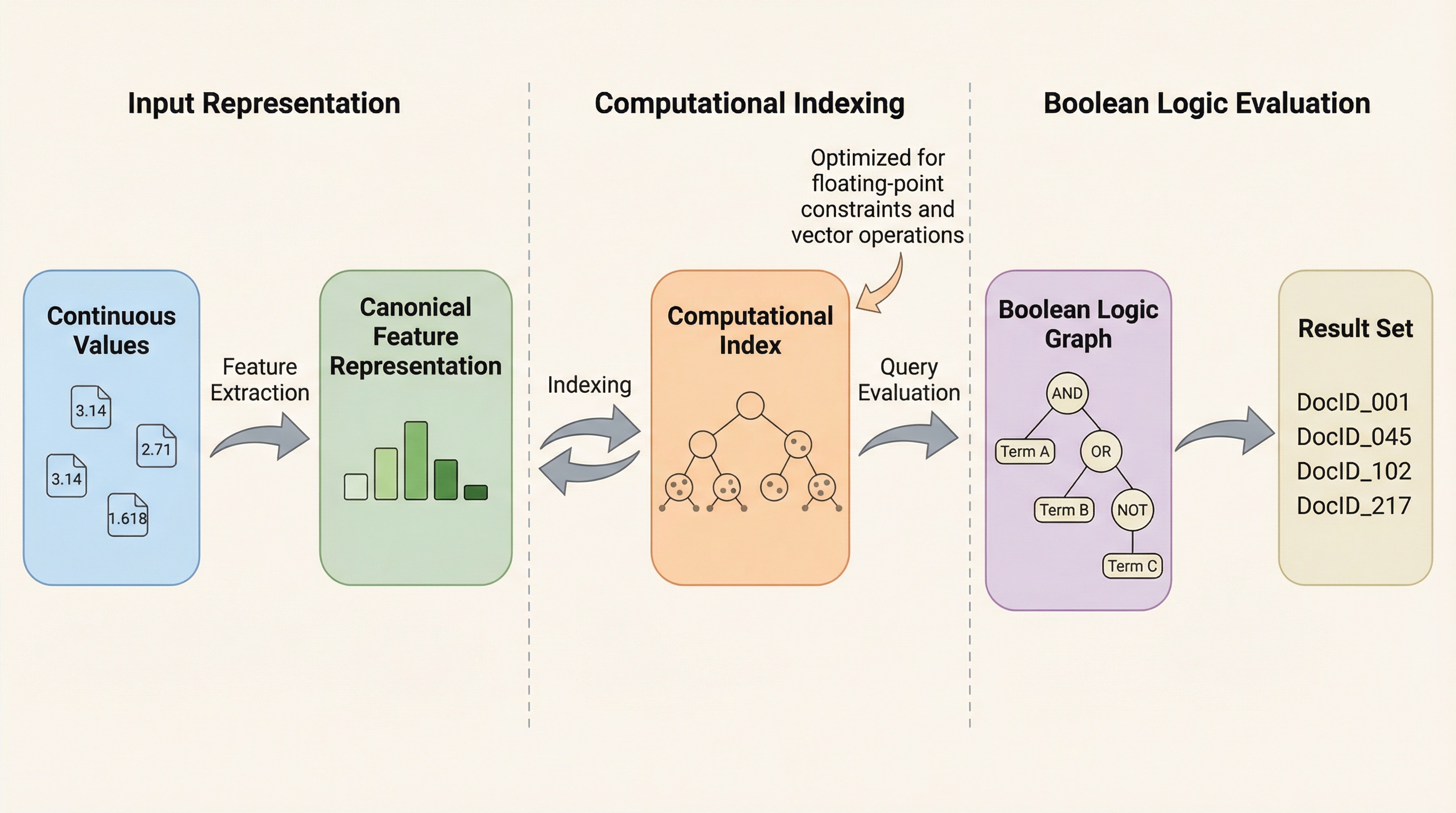
現代の情報検索は、単純なキーワード検索から大規模言語モデル(LLM)や自律型エージェントが要求する複雑な記号論理的推論へと移行していますが、既存の検索エンジンは複雑な論理構造を効率的に処理できないという深刻な課題を抱えています。
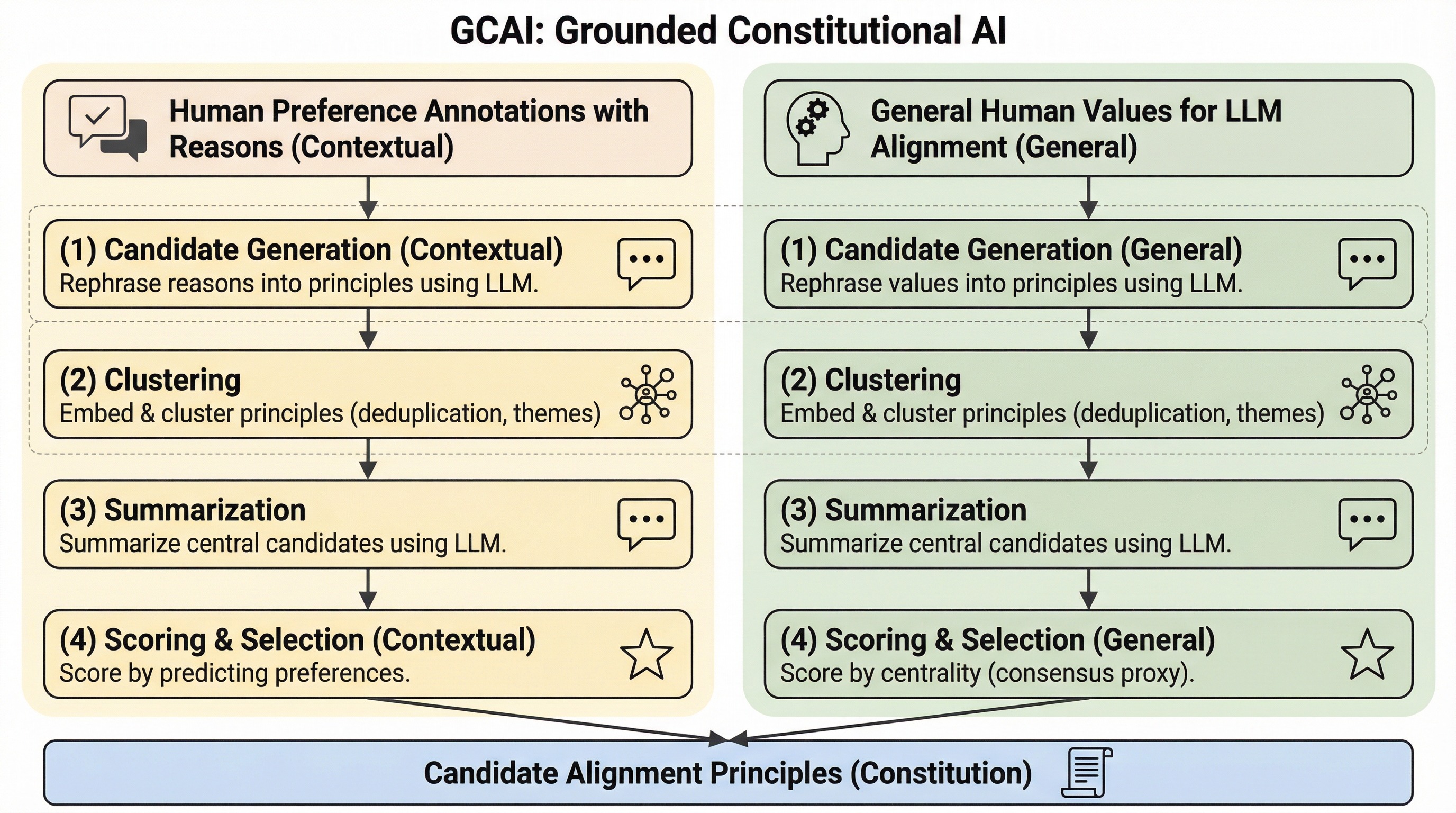
大規模言語モデル(LLM)を人間の価値観に適合させる際、従来の「どちらの回答が好ましいか」という選好データのみに頼る手法では、ユーザーの真の意図や稀にしか発生しない倫理的懸念を十分に反映できないという課題がある。
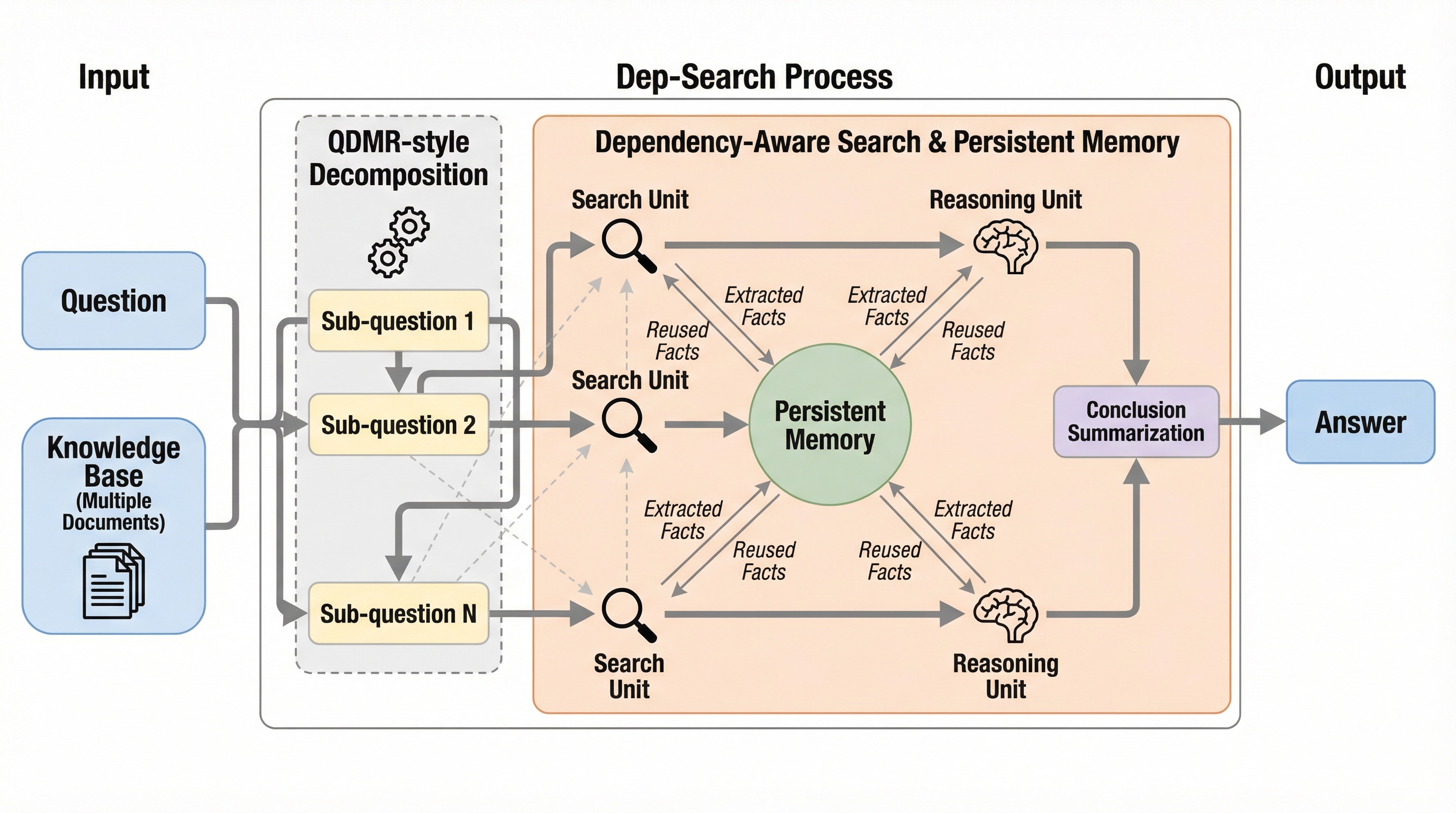
大規模言語モデルを用いた従来の検索型フレームワークは、自然言語による暗黙的な推論に依存しており、サブ質問間の依存関係の管理や過去に取得した知識の効率的な再利用が困難であるという課題を抱えていました。
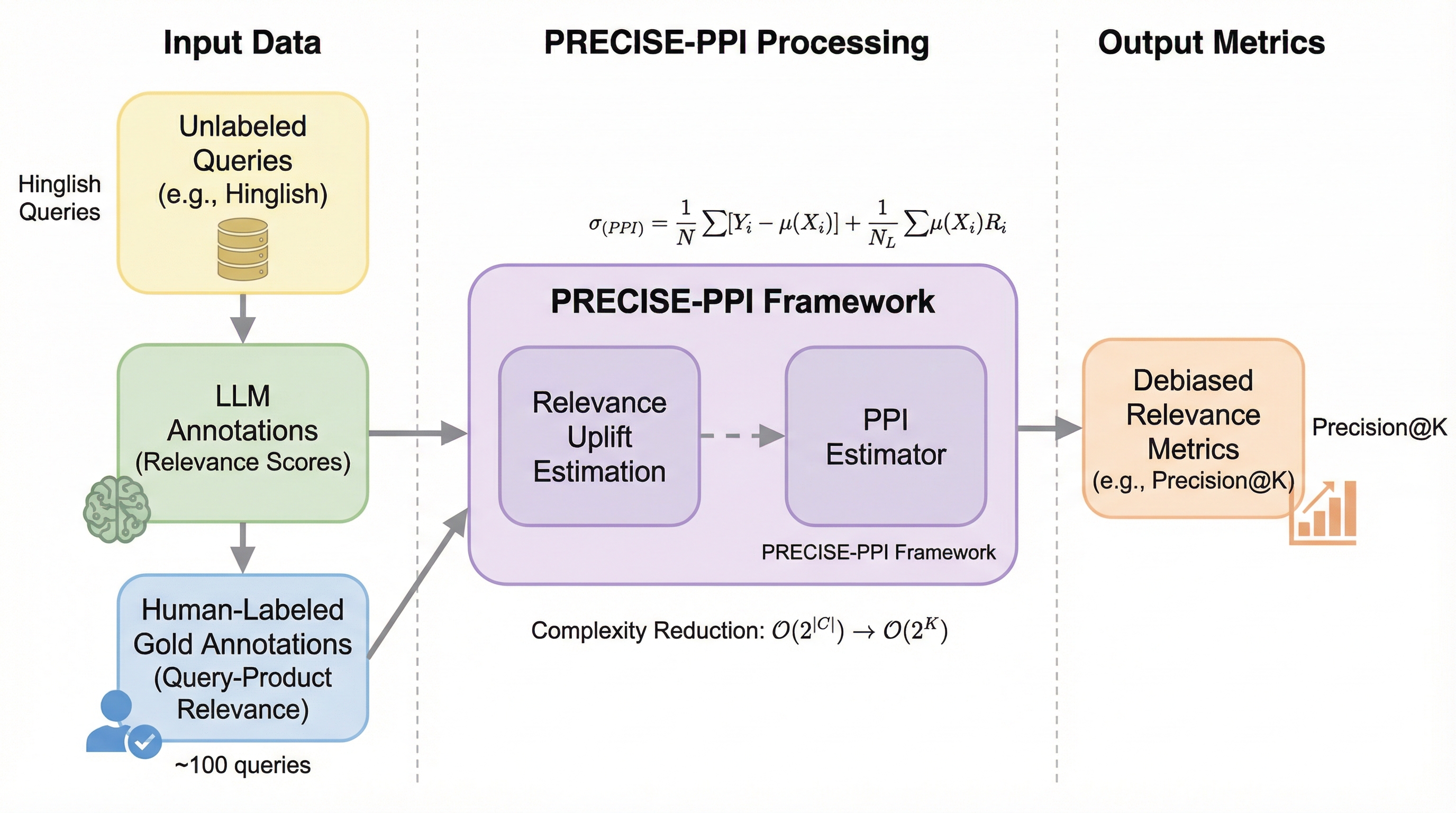
検索システムの評価において、膨大な人的コストと大規模言語モデル(LLM)固有のバイアスが課題となる中、本研究では少数の人間による注釈と大量のLLM判定を統計的に融合させる新フレームワーク「PRECISE」を提案した。
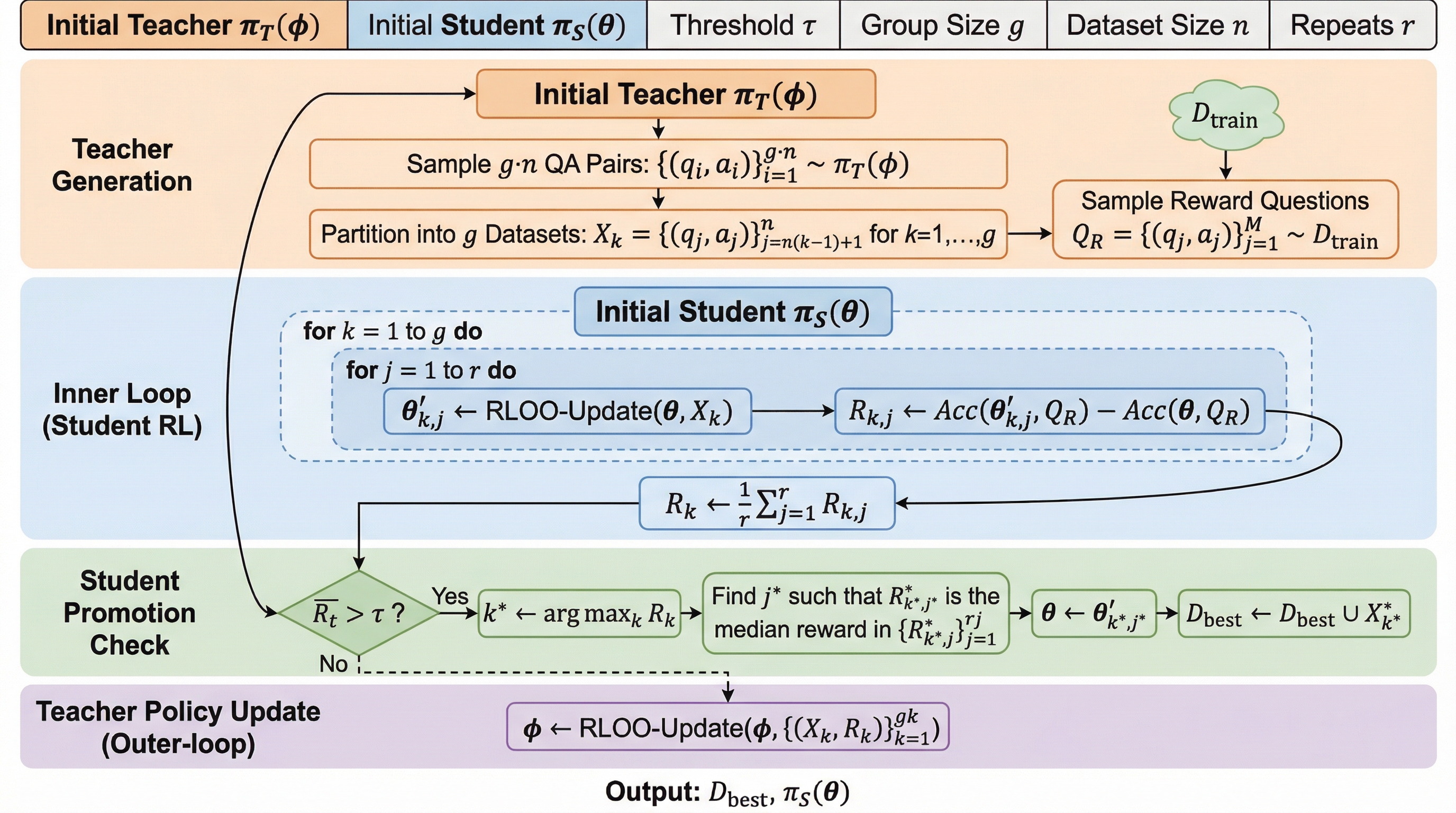
大規模言語モデルが正答率0%の難問に直面した際、従来の強化学習では学習信号が得られず停滞しますが、本研究はモデル自身が「踏み台」となる問題を生成して自己改善するフレームワーク「SOAR」を提案しました。
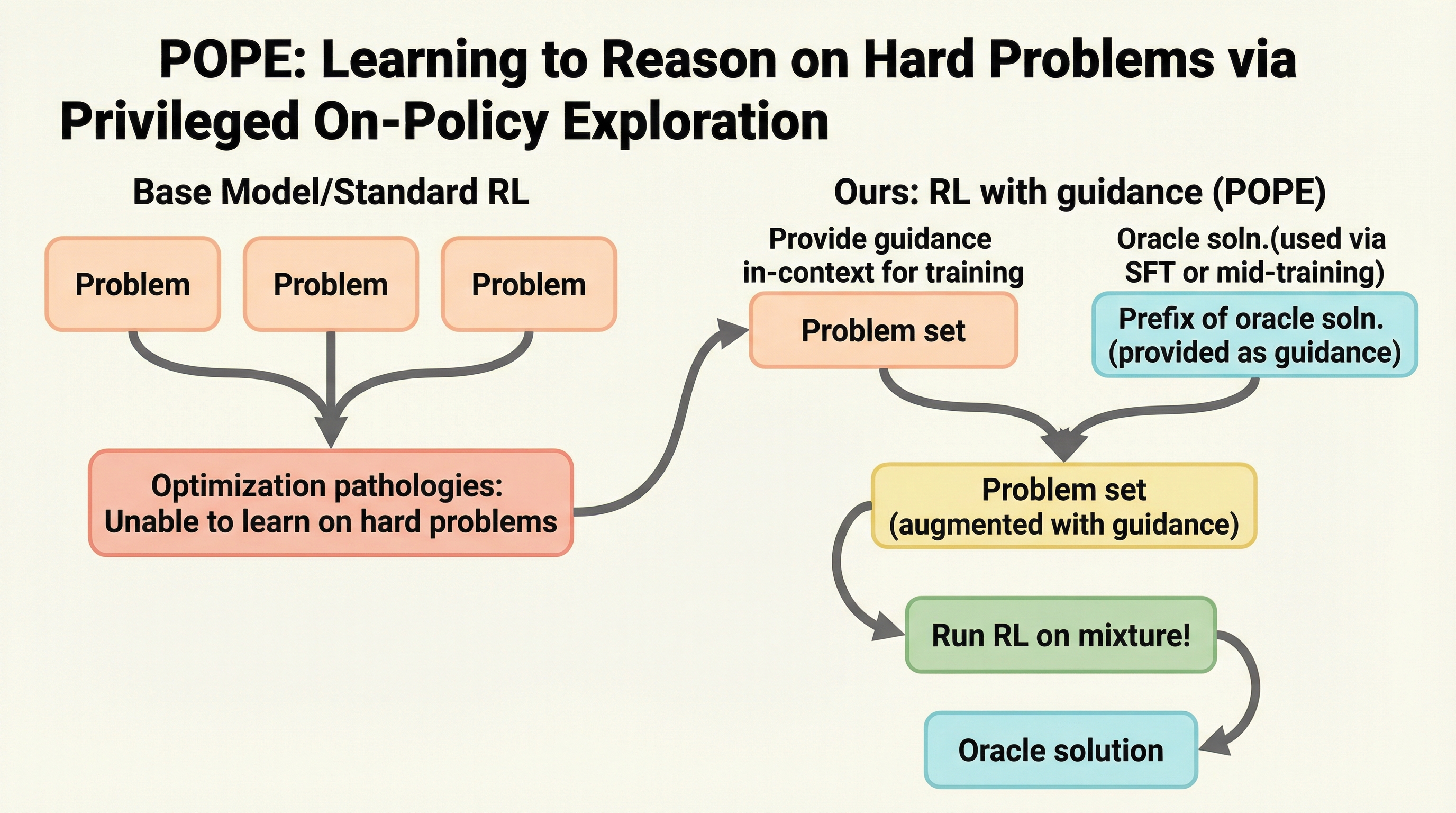
大規模言語モデルの強化において、従来のオンポリシー強化学習は困難な問題で正解を一度も生成できず、学習信号が得られないという課題に直面していました。本研究が提案するPOPEは、人間やオラクルによる正解の「接頭辞(プリフィックス)」を特権的なガイドとして与えることで、モデルが自力では到達できない正解への探索をオンポリシーで実行可能にします。 この手法は、オラクルの解を直接の学習目標とするのではなく、指示に従う能力を活用して探索を導くため、従来の蒸留やオフポリシー学習で発生していた最適化の不安定さや性能の頭打ちを回避することに成功しました。検証の結果、AIME 2025などの難関ベンチマークにおいて、標準的な強化学習では到達できなかった高い正解率を達成し、困難な問題に対する推論能力を大幅に向上させることを示しました。