自己蒸留推論器:大規模言語モデルのためのオンポリシー自己蒸留
大規模言語モデルの推論能力を向上させるため、外部の教師モデルを必要とせず、単一のモデルが特権情報を活用して自分自身を教育する「オンポリシー自己蒸留(OPSD)」という新しい学習枠組みが提案されました。
TL;DR(結論)
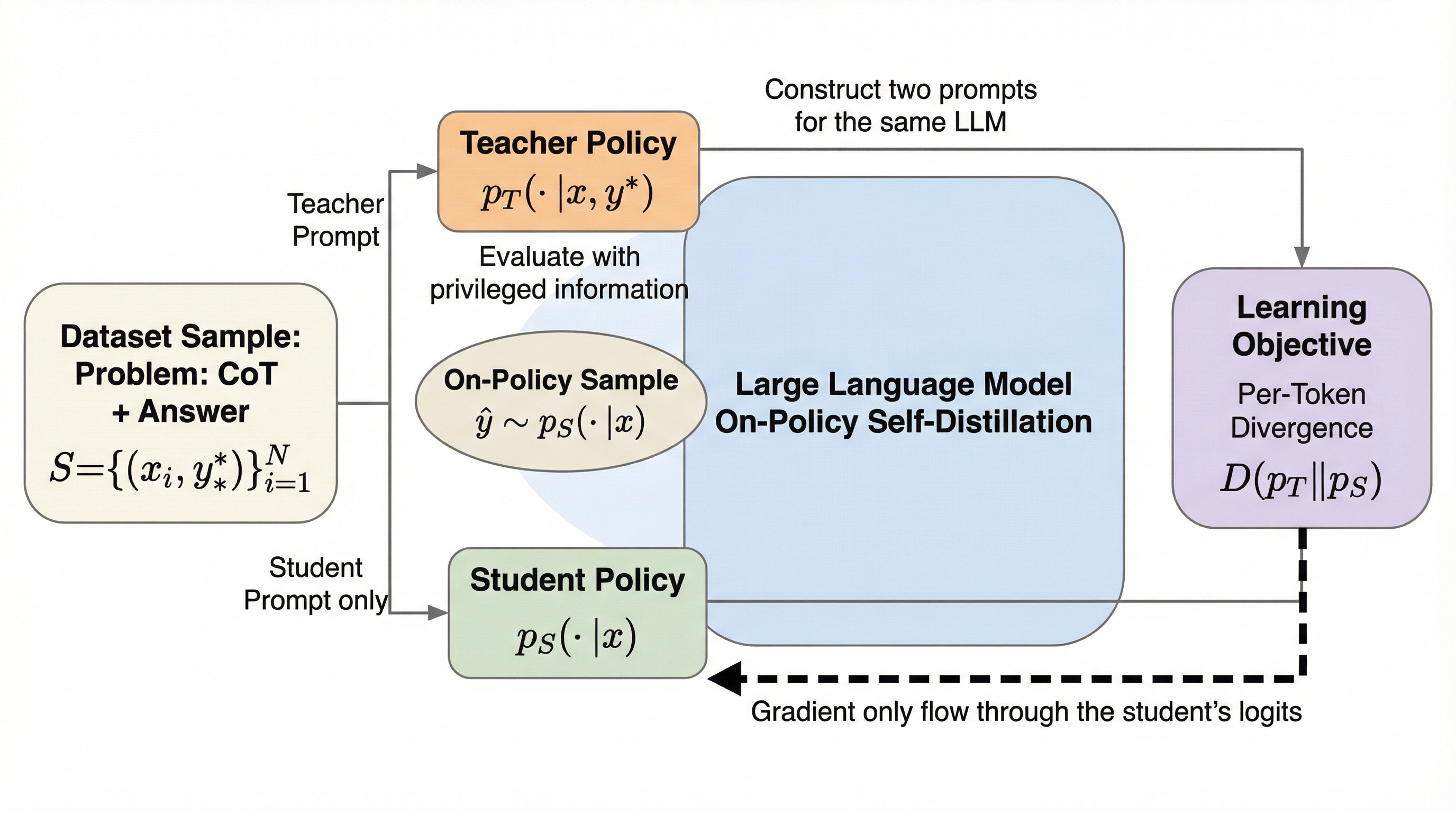
大規模言語モデルの推論能力を向上させるため、外部の教師モデルを必要とせず、単一のモデルが特権情報を活用して自分自身を教育する「オンポリシー自己蒸留(OPSD)」という新しい学習枠組みが提案されました。この手法は、正解を知っている「教師役」と問題のみを見る「生徒役」を同一モデルで演じ分け、生徒自身が生成した回答の軌跡に対してトークン単位の詳細なフィードバックを与えることで、効率的な学習を実現します。 数学的推論ベンチマークでの検証の結果、従来の強化学習手法であるGRPOと比較して4倍から8倍という極めて高いトークン効率を達成し、教師あり微調整や強化学習を上回る推論性能を示すことが確認されました。これにより、計算リソースを抑えつつモデルの潜在能力を最大限に引き出すことが可能になります。 本手法は、モデルが自ら正解を「合理化」して学習するという、人間の学習プロセスに近いアプローチを採っており、特に数学のような検証可能なタスクにおいて、従来の強化学習が抱えていた報酬の疎性や計算コストの問題を根本から解決する可能性を秘めています。
なぜこの問題か
現在の大規模言語モデル(LLM)のポストトレーニングにおいて、推論能力を強化するための主要な手法にはそれぞれ固有の課題が存在しています。まず、検証可能な報酬を用いた強化学習(RLVR)であるGRPOなどの手法は、1つのプロンプトに対して複数の回答をサンプリングする必要があるため計算コストが非常に高く、報酬信号が回答全体の正誤という「疎」な形でしか与えられないため、学習の効率が悪いという問題があります。また、サンプリングされたすべての回答が正解、あるいはすべてが不正解となった場合には勾配信号が消失してしまい、計算リソースを消費したにもかかわらずモデルが更新されないという事態も発生します。これは、モデルがどのステップで間違えたのか、あるいはどのステップが正解に寄与したのかという詳細な情報が欠落しているためです。 一方で、高品質な推論データセットを用いた教師あり微調整(SFT)は、学習時にモデルが参照するデータと推論時に自身で生成するデータの分布が異なることによる「露出バイアス」の問題を抱えており、汎化性能が低下しやすいという欠点があります。…
核心:何を提案したのか
本研究では、十分な能力を持つ言語モデルであれば、外部の特権的な推論の軌跡を合理化し、特権情報にアクセスできない状態の自分自身を教えることができるという直感に基づき、「オンポリシー自己蒸留(OPSD)」というフレームワークを提案しました。この手法の核心は、単一のモデルがコンテキストの条件付けを変えるだけで、教師ポリシーと生徒ポリシーの両方の役割を同時に担う点にあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related