選好を超えて:人間の理由と価値観に根ざしたアライメント原則の学習
大規模言語モデル(LLM)を人間の価値観に適合させる際、従来の「どちらの回答が好ましいか」という選好データのみに頼る手法では、ユーザーの真の意図や稀にしか発生しない倫理的懸念を十分に反映できないという課題がある。
TL;DR(結論)
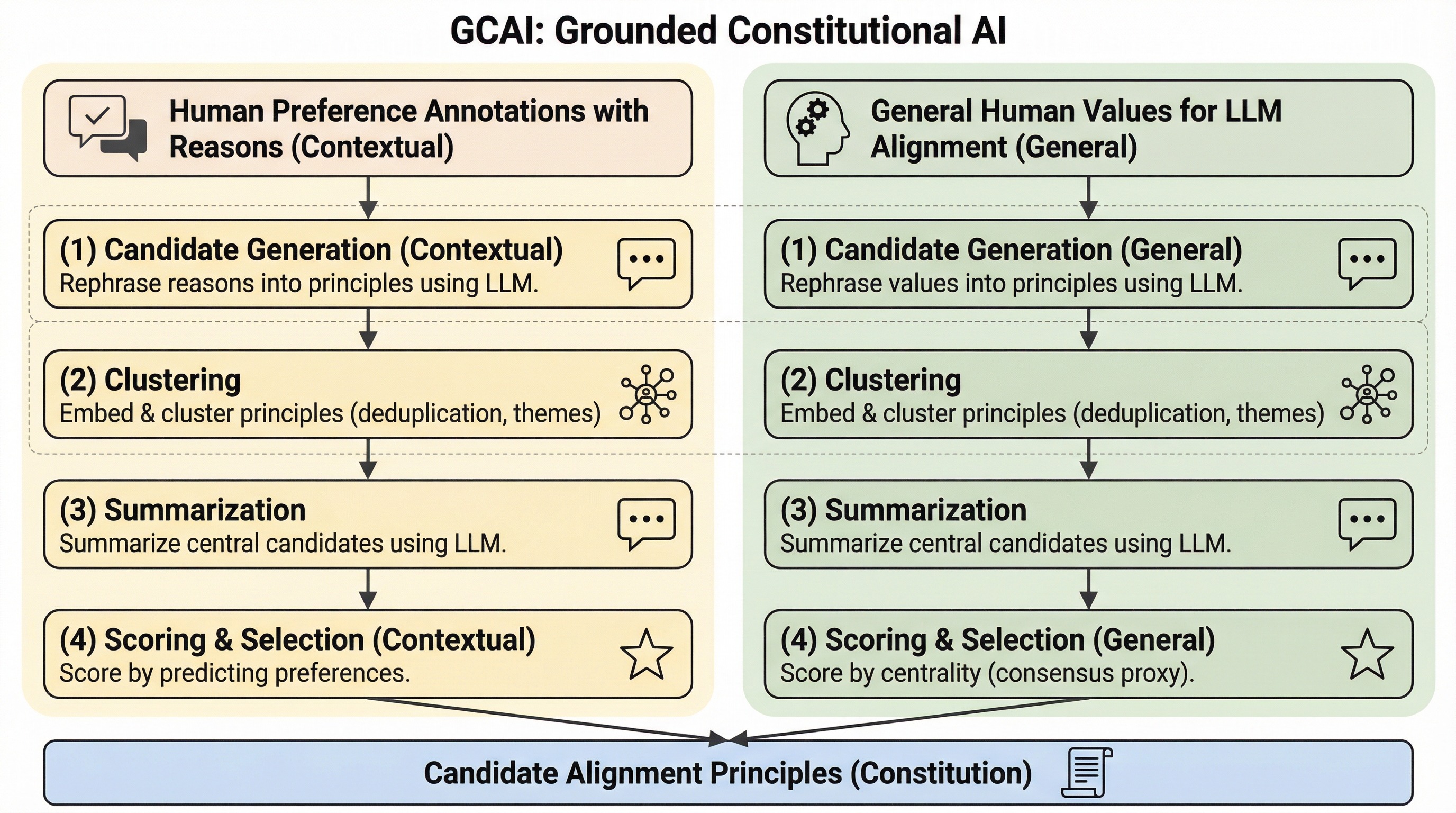
大規模言語モデル(LLM)を人間の価値観に適合させる際、従来の「どちらの回答が好ましいか」という選好データのみに頼る手法では、ユーザーの真の意図や稀にしか発生しない倫理的懸念を十分に反映できないという課題がある。 本研究が提案する「GCAI(Grounded Constitutional AI)」は、ユーザーが選好の理由として挙げた自然言語による説明(文脈的原則)と、AI全般に対して抱く期待や価値観の表明(一般的原則)を統合し、多様な意見を公平かつスケーラブルに集約して「AI憲法」を自動生成するフレームワークである。 検証の結果、GCAIが生成した憲法は、従来の選好のみに基づく手法よりも道徳的根拠や多様性の面で優れていると人間から評価され、実際のモデルにおいても倫理や安全性、非差別をより重視した振る舞いを実現することが示された。
なぜこの問題か
大規模言語モデル(LLM)を人間の価値観に合わせる「アライメント」は、現代の倫理的なAI開発において極めて重要な課題である。現在主流の憲法型アライメントと呼ばれる手法では、自然言語で記述された「原則(憲法)」に従ってモデルを調整するが、この憲法をどのように決定すべきかというプロセスには大きな課題が残されている。特に、数百万人に及ぶ可能性があるステークホルダーの多様な意見を、公平かつ効率的に集約して憲法に反映させるスケーラブルな手法が確立されていない。 従来の「Inverse Constitutional AI(ICAI)」のような手法は、人間による回答の「選好(どちらが好きか)」というラベルから統計的に原則を推論しようとする。しかし、単なる選好ラベルだけでは、なぜその回答が選ばれたのかという具体的な理由が抜け落ちてしまう。例えば、ある回答が選ばれた理由が「丁寧だから」なのか「正確だから」なのかは、ラベルだけでは判別できず、AIが誤った原則を学習するリスクがある。…
核心:何を提案したのか
本研究は、人間の「理由(Reasons)」と「価値観(Values)」を直接的な根拠として、AIの行動指針となる憲法を生成する新しい学習フレームワーク「GCAI(Grounded Constitutional AI)」を提案した。GCAIの最大の特徴は、アライメントの根拠となる原則を「文脈的原則(Contextual principles)」と「一般的原則(General principles)」の二つの側面から捉え、それらを統合して一つの憲法を構築する点にある。 文脈的原則とは、人間が実際にAIと対話した際に示した「なぜこちらの方が良い回答だと思ったのか」という具体的な正当化理由から抽出される原則である。これにより、単なる選好ラベルの背後にある「トーンの適切さ」や「説明の丁寧さ」といった、数値化しにくいニュアンスを正確に捉えることが可能になる。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related