Reflect:大規模な憲法的アライメントのための透明な原則に基づいた推論
Reflectは、大規模言語モデルを自然言語の原則(憲法)に適合させるための、追加学習や人間による注釈を一切必要としない推論時フレームワークである。 初期回答の生成、自己評価、自己批判、最終修正という4段階のプロセスをインコンテキストで実行することで、モデルの判断を透明化し、複雑な価値観への適合性を大幅に向上させる。
TL;DR(結論)
Reflectは、大規模言語モデルを自然言語の原則(憲法)に適合させるための、追加学習や人間による注釈を一切必要としない推論時フレームワークである。 初期回答の生成、自己評価、自己批判、最終修正という4段階のプロセスをインコンテキストで実行することで、モデルの判断を透明化し、複雑な価値観への適合性を大幅に向上させる。 最新のモデルを用いた実験では、数学的推論などの基本性能を維持したまま、発生頻度は低いがリスクの大きい重大な原則違反を効果的に削減し、将来の学習用データ生成にも寄与することが示された。
なぜこの問題か
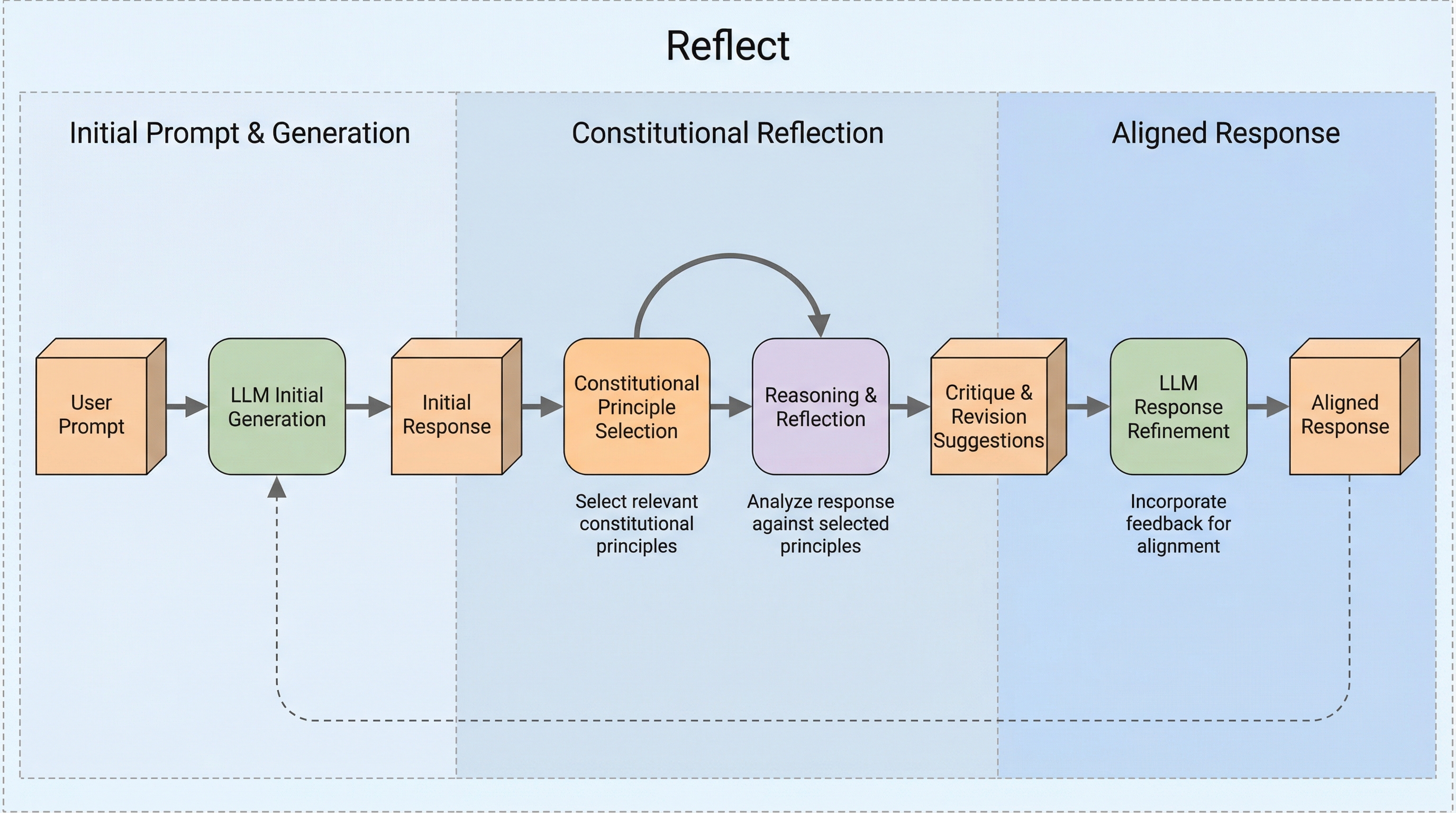
憲法的なアライメントの枠組みは、大規模言語モデル(LLM)を自然言語で記述された価値観に基づく原則(偏見のある表現の回避など)に適合させることを目的としています。従来の研究では、これらの原則を浸透させるために、人間からのフィードバックによる強化学習(RLHF)などのパラメータのファインチューニング技術に焦点が当てられてきました。しかし、これらの手法は計算負荷が高く、綿密なエンジニアリングと調整を必要とし、さらには入手が困難な人間によるアノテーションデータを必要とすることが多々あります。我々は、トレーニングやデータを一切必要としない、推論時の憲法的アライメントのための枠組みであるREFLECTを提案します。これは、指示調整済みモデルを一連の原則に適合させるためのプラグアンドプレイなアプローチを提供します。REFLECTは完全にコンテキスト内で動作し、(i) 憲法を条件とした基本回答と、生成後の (ii) 自己評価、(iii)(a) 自己批判、および (iii)(b) 最終的な修正を組み合わせます。…
核心:何を提案したのか
本研究では、推論時に動的なアライメントを実現する新しいフレームワークである「Reflect」を提案している。Reflectの最大の特徴は、モデルの追加学習や人間による新たなデータを一切必要とせず、自然言語で記述された「憲法(原則のセット)」に対して、プラグアンドプレイの形でモデルを適合させることができる点にある。これは、従来のパラメータ微調整に依存する手法とは根本的に異なるアプローチである。Reflectは、指示調整済みのモデルに対して、推論プロセスの中で明示的に原則に基づいた思考を行わせることで、モデルの重みを変更することなく、特定の価値観に沿った出力を導き出す。この手法は、憲法的アライメントの枠組みを推論時のインコンテキスト学習へと拡張したものであり、開発者は自然言語で原則を記述するだけで、即座にモデルの振る舞いを制御することが可能になる。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related