POPE:特権的オンポリシー探索による困難な問題における推論の学習
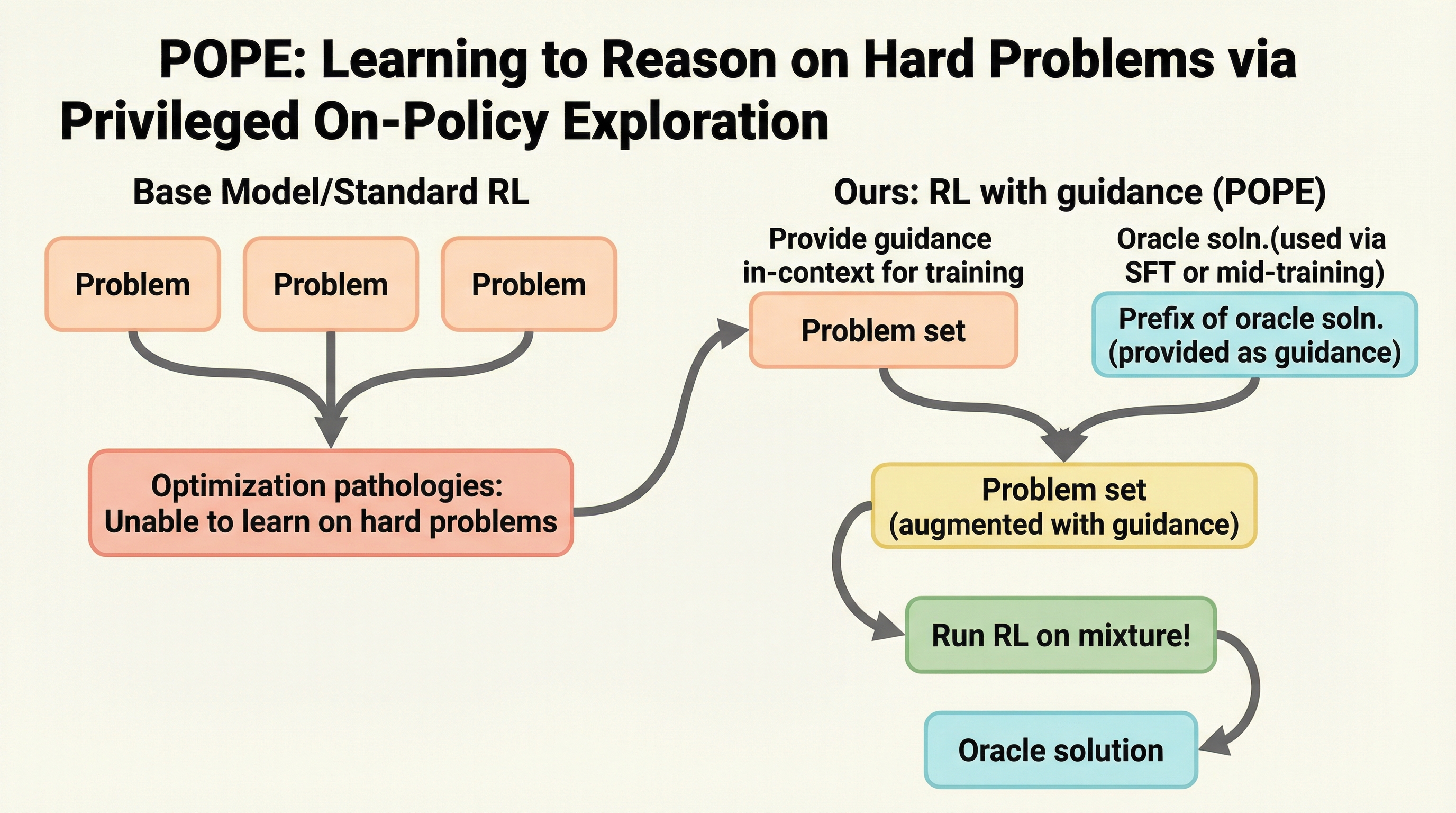
大規模言語モデルの強化において、従来のオンポリシー強化学習は困難な問題で正解を一度も生成できず、学習信号が得られないという課題に直面していました。本研究が提案するPOPEは、人間やオラクルによる正解の「接頭辞(プリフィックス)」を特権的なガイドとして与えることで、モデルが自力では到達できない正解への探索をオンポリシーで実行可能にします。 この手法は、オラクルの解を直接の学習目標とするのではなく、指示に従う能力を活用して探索を導くため、従来の蒸留やオフポリシー学習で発生していた最適化の不安定さや性能の頭打ちを回避することに成功しました。検証の結果、AIME 2025などの難関ベンチマークにおいて、標準的な強化学習では到達できなかった高い正解率を達成し、困難な問題に対する推論能力を大幅に向上させることを示しました。
TL;DR(結論)
大規模言語モデルの強化において、従来のオンポリシー強化学習は困難な問題で正解を一度も生成できず、学習信号が得られないという課題に直面していました。本研究が提案するPOPEは、人間やオラクルによる正解の「接頭辞(プリフィックス)」を特権的なガイドとして与えることで、モデルが自力では到達できない正解への探索をオンポリシーで実行可能にします。 この手法は、オラクルの解を直接の学習目標とするのではなく、指示に従う能力を活用して探索を導くため、従来の蒸留やオフポリシー学習で発生していた最適化の不安定さや性能の頭打ちを回避することに成功しました。検証の結果、AIME 2025などの難関ベンチマークにおいて、標準的な強化学習では到達できなかった高い正解率を達成し、困難な問題に対する推論能力を大幅に向上させることを示しました。
なぜこの問題か
大規模言語モデル(LLM)の推論能力を向上させるために強化学習(RL)は非常に有効な手段ですが、既存の手法には「困難な問題において学習が停滞する」という深刻な限界が存在します。特にオンポリシー強化学習においては、モデルが現在の能力で正解のロールアウト(思考プロセスと回答)を少なくとも一度は生成できなければ、報酬が得られず、モデルを更新するための勾配が発生しません。例えば、Qwen3-4B-Instructというモデルを用いて数学の問題セットであるDAPO-MATH-17Kを学習させた場合、50%以上の問題において、32回の試行を行っても一度も正解にたどり着けないという事実が確認されています。このような状況では、学習プロセスが実質的に停止してしまい、モデルが持つ潜在的な能力を引き出すことができません。 この探索の問題を解決するために、古典的な強化学習で用いられる「エントロピー・ボーナス」や、重要度サンプリングの比率を緩やかに制限する「クリッピングの調整」といった手法が検討されてきました。しかし、本研究の分析によれば、これらの手法はLLMの学習においては最適化の病理を引き起こすことが判明しました。…
核心:何を提案したのか
本研究は、困難な問題における探索を劇的に改善するための新しい枠組みとして「特権的オンポリシー探索(Privileged On-Policy Exploration:POPE)」を提案しました。POPEの核心的なアイデアは、人間やオラクルが作成した正解の一部を「特権的な情報」としてモデルに与え、それを手がかりとしてモデル自身の力で正解までたどり着かせるという点にあります。具体的には、困難な問題のプロンプトに対して、正解に至る思考プロセスの最初の数ステップ(接頭辞)を付加します。これにより、モデルはゼロから正解を探すのではなく、与えられた正しい文脈の上で推論を継続することができるようになります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related