Dep-Search:永続メモリを用いた依存関係を考慮した推論トレースの学習
大規模言語モデルを用いた従来の検索型フレームワークは、自然言語による暗黙的な推論に依存しており、サブ質問間の依存関係の管理や過去に取得した知識の効率的な再利用が困難であるという課題を抱えていました。
TL;DR(結論)
大規模言語モデルを用いた従来の検索型フレームワークは、自然言語による暗黙的な推論に依存しており、サブ質問間の依存関係の管理や過去に取得した知識の効率的な再利用が困難であるという課題を抱えていました。 本論文が提案する「Dep-Search」は、有向非巡回グラフを用いた依存関係を考慮した質問分解と、LRU方式の永続メモリ、そしてGRPOによる軌跡レベルの強化学習を統合することで、構造化された推論と効率的な知識蓄積を実現します。 複数のマルチホップ質問回答データセットを用いた検証の結果、Dep-Searchは既存の強力なベースラインを大幅に上回る性能を達成し、特に複雑な推論を必要とするタスクにおいて、冗長な検索を抑えつつ高い回答精度を示すことが確認されました。
なぜこの問題か
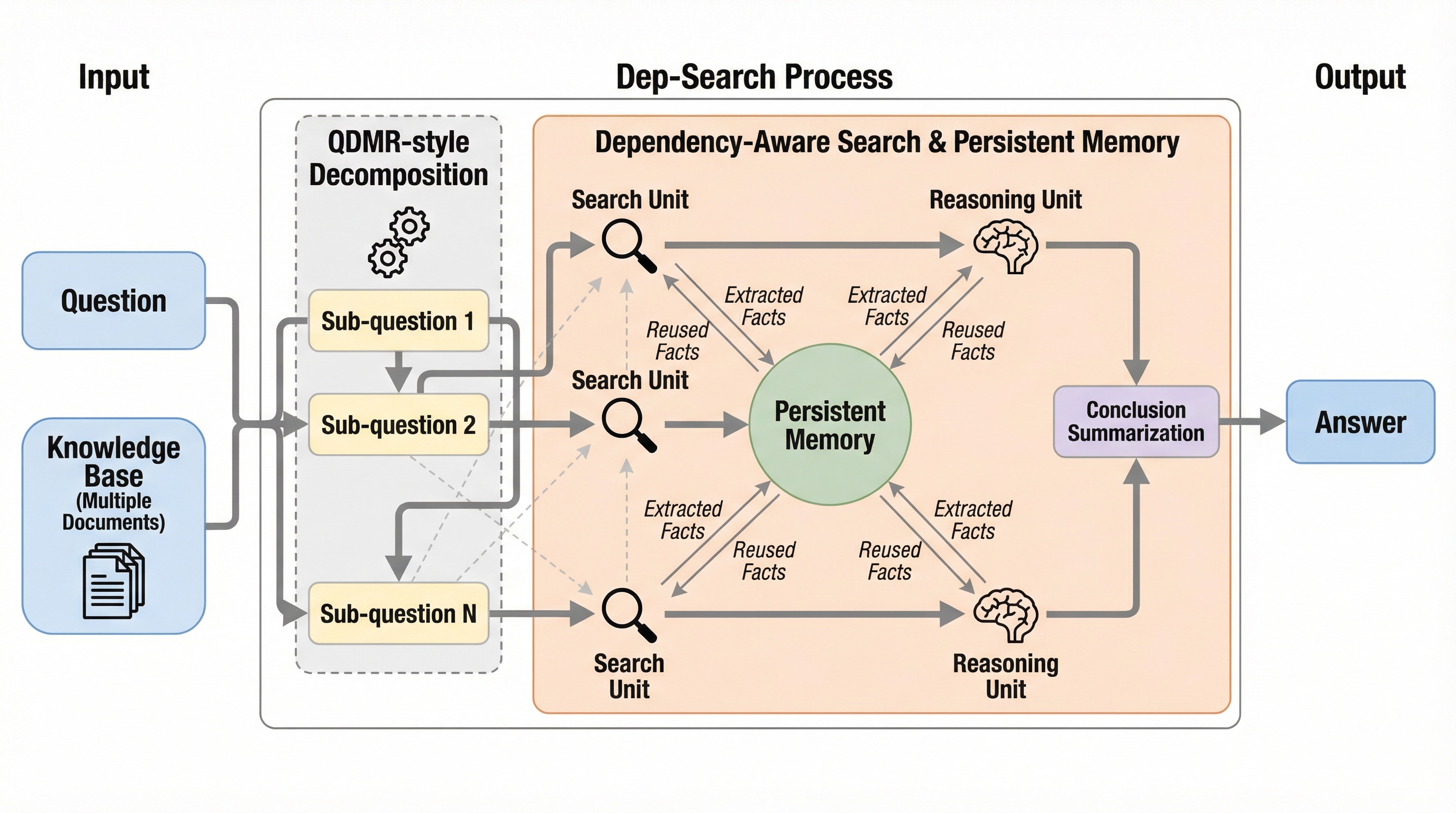
大規模言語モデル(LLM)は複雑な推論タスクにおいて優れた能力を示していますが、外部知識ベースを探索する検索メカニズムと組み合わせることで、その能力はさらに拡張されます。従来の検索拡張生成(RAG)から、明示的な検索戦略を通じて多段階の推論を構築する検索ベースのフレームワークへと進化を遂げてきました。しかし、既存のフレームワークには根本的な課題が残されています。それは、検索戦略の決定や取得した情報の活用を、モデルの暗黙的な自然言語推論に過度に依存している点です。 この暗黙的な推論への依存は、複数のサブ質問間の依存関係を管理することを困難にします。例えば、ある質問を解くために必要な情報が別のサブ質問の回答に依存している場合、既存の手法ではその順序を明示的に制御できず、非効率な検索パターンが発生しやすくなります。また、推論の過程で得られた貴重な知識が、ステップ間やエピソード間で失われてしまうという問題もあります。同じ情報を何度も検索し直すことになり、計算コストの増大と推論効率の低下を招いています。 さらに、検索ベースのLLMにおいて最適な検索戦略を学習させることは容易ではありません。…
核心:何を提案したのか
本論文は、構造化された推論、検索、および永続メモリをGRPO(Group Relative Policy Optimization)を通じて統合する、依存関係を考慮した検索フレームワーク「Dep-Search」を提案しています。このフレームワークの核心は、モデルが自律的に制御できる明示的な制御メカニズムを導入した点にあります。具体的には、質問を依存関係に基づいて分解し、必要に応じて情報を検索し、メモリから過去の知識を呼び出し、長い推論コンテキストを再利用可能なメモリ・エントリへと要約する機能を備えています。 Dep-Searchは、従来のヒューリスティックな検索戦略とは異なり、これらすべての行動をポリシー内のトークンとして一律に扱います。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related