モデルに自らを教えさせる:学習可能性の限界における推論
大規模言語モデルが正答率0%の難問に直面した際、従来の強化学習では学習信号が得られず停滞しますが、本研究はモデル自身が「踏み台」となる問題を生成して自己改善するフレームワーク「SOAR」を提案しました。
TL;DR(結論)
大規模言語モデルが正答率0%の難問に直面した際、従来の強化学習では学習信号が得られず停滞しますが、本研究はモデル自身が「踏み台」となる問題を生成して自己改善するフレームワーク「SOAR」を提案しました。 この手法は、教師役のモデルが生徒役のために合成問題を生成し、生徒が実際の難問で示した進歩を教師の報酬とする「接地された報酬」を用いたメタ強化学習により、内発的報酬に頼る従来手法よりも安定した学習を実現します。 検証の結果、数学ベンチマークにおいて正答率を最大4倍に向上させるなど、外部データに頼らずに学習の停滞を打破し、モデルが自身で解けない問題に対しても有効な教育カリキュラムを提示できる潜在能力を持つことが示されました。
なぜこの問題か
大規模言語モデル(LLM)の推論能力を向上させる手法として、検証可能な報酬を用いた強化学習(RLVR)が数学やプログラミングの分野で大きな成果を上げています。しかし、このパラダイムには「モデルがすでにある程度解ける問題からしか学習できない」という根本的な限界が存在します。強化学習は正解の軌跡を強化することで機能するため、初期の成功率が極端に低い難問セットでは、正の報酬信号が全く得られず、学習が完全に停滞してしまう「プラトー(停滞期)」に陥ります。数学のような記号推論のドメインでは、正誤がバイナリ(0か1か)で判定されるため、勾配を得るための信号が極めて希薄であり、この問題は特に深刻です。 これまでの研究では、学習データの順序を工夫するカリキュラム学習が検討されてきましたが、これらは人間が設計した中間データセットや、慎重に調整された難易度の段階を必要とすることが多く、未知の難問に対して汎用的に適用することは困難でした。また、コード生成のようにテストケースで中間的な信号を得られるドメインもありますが、数学ではそのような部分的な評価が難しいため、モデルが自律的に学習を進めるための新しいアプローチが求められています。…
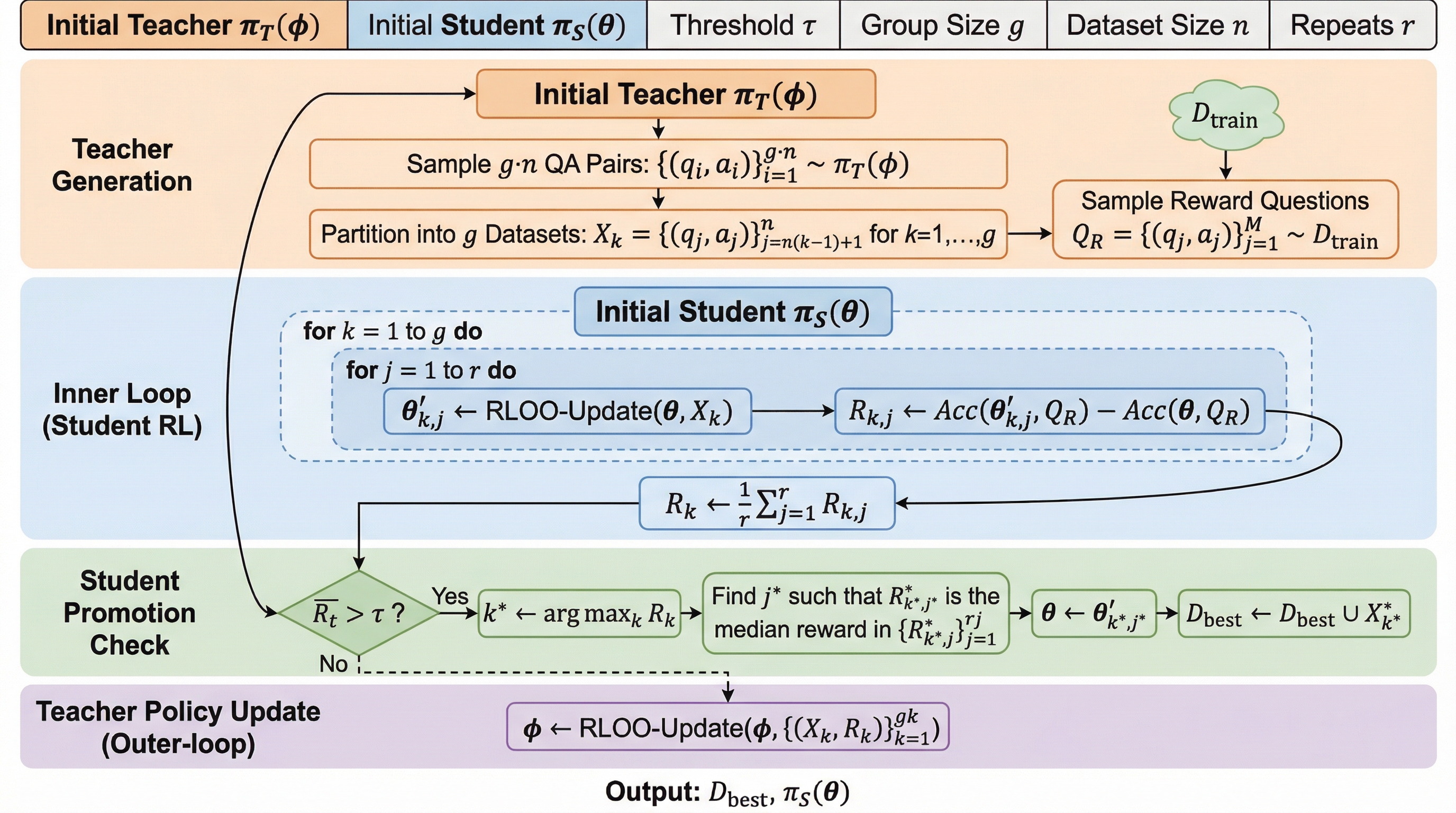
核心:何を提案したのか
本研究は、事前学習済みモデルが持つ潜在的な知識を活用して、自身が解けない問題に対する自動カリキュラムを生成するメタ強化学習フレームワーク「SOAR(Self-Optimization via Asymmetric RL)」を提案しました。このフレームワークの最大の特徴は、教師役と生徒役の二つのモデル(どちらも同じ事前学習済みモデルから初期化される)を用いた非対称なセットアップにあります。役割を分担することで、モデルの「問題を解く能力」と「問題を教える能力」を切り離して最適化することが可能になります。教師は生徒が学ぶべき問題を提示し、生徒はその問題を通じて自身の推論能力を磨くという役割を担います。 SOARの核心は、教師モデルへの報酬設計にあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related