PRECISE:予測に基づくランキング推定を用いたLLM評価のバイアス低減
検索システムの評価において、膨大な人的コストと大規模言語モデル(LLM)固有のバイアスが課題となる中、本研究では少数の人間による注釈と大量のLLM判定を統計的に融合させる新フレームワーク「PRECISE」を提案した。
TL;DR(結論)
検索システムの評価において、膨大な人的コストと大規模言語モデル(LLM)固有のバイアスが課題となる中、本研究では少数の人間による注釈と大量のLLM判定を統計的に融合させる新フレームワーク「PRECISE」を提案した。 従来の予測駆動型推論(PPI)をクエリ・ドキュメント単位のサブインスタンス注釈へ拡張し、計算複雑性をコーパスサイズ依存からランキング数Kの指数関数へと劇的に削減することで、Precision@Kなどの主要な指標を正確かつ効率的に推定することを可能にした。 インドのEコマースにおける多言語クエリ書き換えタスクに適用した結果、わずか100件の人間による注釈でLLMのバイアスを補正し、推定値の分散を大幅に抑えつつ、実際のA/Bテストと整合するビジネス指標の改善をオフラインで正確に予測することに成功した。
なぜこの問題か
現代のEコマースにおいて、検索や推薦システムの品質を継続的に評価することは極めて重要であるが、伝統的な手法である人間による適合性判定にはスケーラビリティとコストの面で大きな課題がある。特にランキングモデルやアルゴリズムは頻繁に更新されるため、その都度大規模な評価を繰り返すことは現実的ではない。一方で、ユーザーのクリック信号などの暗黙的なフィードバックを利用する方法も存在するが、これらは提示順序や画面デザインの影響を強く受けるため、純粋な適合性を測る上ではバイアスが含まれるリスクがある。近年、高い推論能力を持つLLMを自動評価者として活用する試みが進んでいるが、LLM自体にも固有のバイアスや文脈による一貫性の欠如という問題があり、そのままでは直接的な指標推定に用いることはできない。 さらに、ランキング指標の推定には特有の困難が伴う。人間による注釈は通常、個別のクエリとドキュメントのペアという最小単位で行われるが、Precision@Kなどのランキング指標はクエリ単位で計算され、データセット全体で集計されるという階層構造を持っている。…
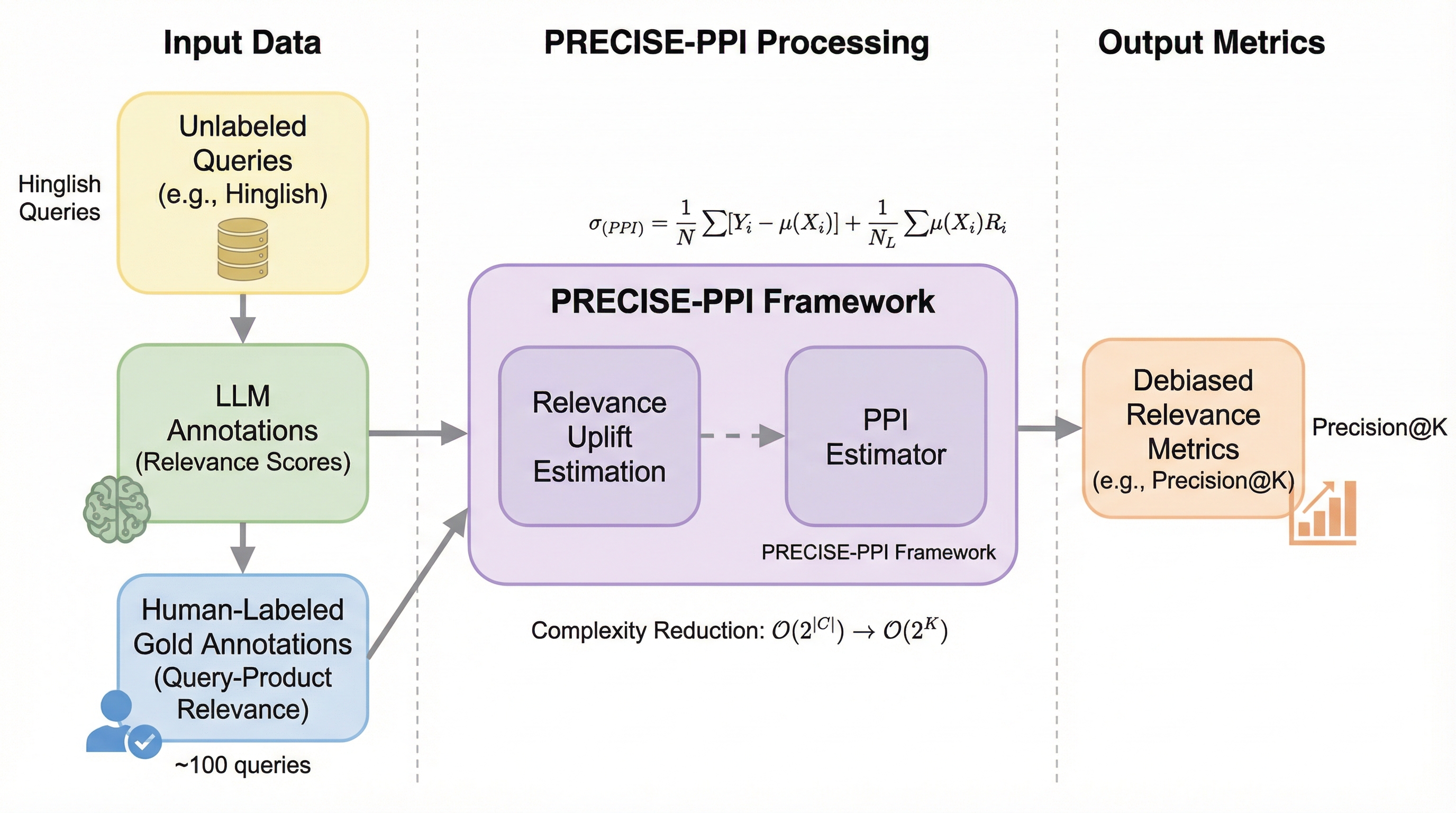
核心:何を提案したのか
本研究が提案する「PRECISE」は、予測駆動型推論(Prediction-Powered Inference: PPI)を拡張し、ランキング指標の推定に特化させた新しい統計的フレームワークである。この手法の核心は、少数の人間による「ゴールドデータ」と、大量のラベルなしデータに対してLLMが生成した「合成ラベル」を組み合わせることで、不偏かつ低分散な指標推定値を算出する点にある。従来のPPIはインスタンス単位の予測を前提としていたが、PRECISEはクエリ内の各ドキュメントというサブインスタンス単位の注釈から、クエリレベルの指標を導き出すことができる。 具体的には、Precision@Kのような指標を推定するために、指標の積分空間を再定式化するという独創的なアプローチを採用した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related