一は全に適応す:個別化されたLLMアライメントのためのメタ報酬モデリング
大規模言語モデル(LLM)を個々のユーザーの多様な好みに適応させるため、メタ学習の枠組みを用いた新しい報酬モデリング手法「Meta Reward Modeling(MRM)」が提案されました。この手法は、少数のフィードバックから未知のユーザーの意図を迅速に学習する「学習のプロセス」そのものを最適化することで、従来の個別化手法が抱えていたデータの希少性や過学習、未知のユーザーへの対応といった課題を根本から解決します。さらに、学習が困難なユーザーを優先的に扱う「Robust Personalization Objective(RPO)」を導入することで、特異な価値観を持つユーザーに対しても一貫して高い精度と堅牢なパフォーマンスを保証し、公平で精緻なパーソナライズを実現しました。
TL;DR(結論)
大規模言語モデル(LLM)を個々のユーザーの多様な好みに適応させるため、メタ学習の枠組みを用いた新しい報酬モデリング手法「Meta Reward Modeling(MRM)」が提案されました。この手法は、少数のフィードバックから未知のユーザーの意図を迅速に学習する「学習のプロセス」そのものを最適化することで、従来の個別化手法が抱えていたデータの希少性や過学習、未知のユーザーへの対応といった課題を根本から解決します。さらに、学習が困難なユーザーを優先的に扱う「Robust Personalization Objective(RPO)」を導入することで、特異な価値観を持つユーザーに対しても一貫して高い精度と堅牢なパフォーマンスを保証し、公平で精緻なパーソナライズを実現しました。
なぜこの問題か
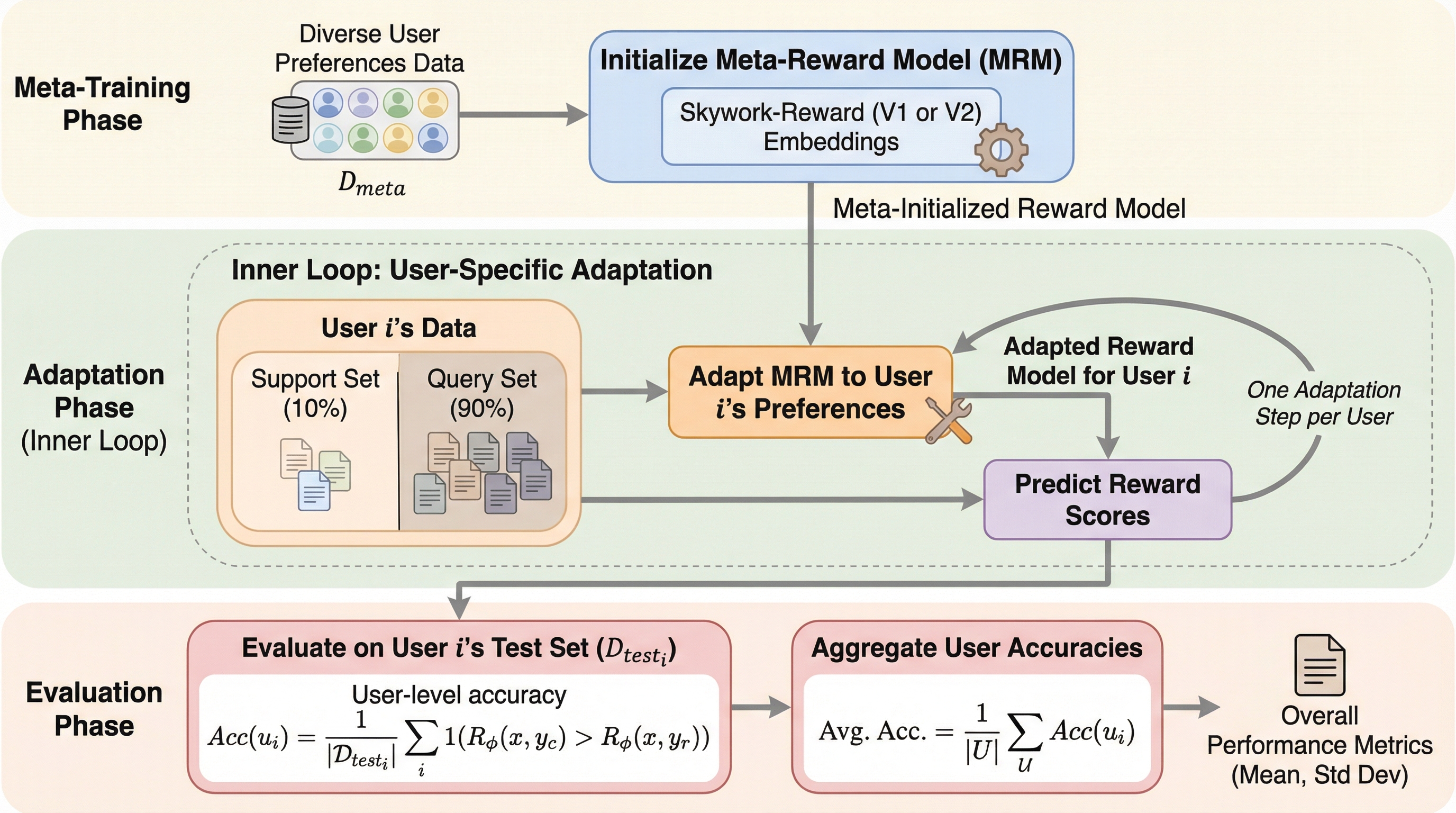
大規模言語モデル(LLM)のアライメントは、モデルの出力を人間の好みに一致させることを目的としていますが、従来のアプローチは全ユーザーに共通する一般的な基準を想定していました。しかし、人間の価値観は非常に多様であり、個人によって好みが大きく異なるため、単一の画一的な基準では不十分であるという課題があります。このため、個々のユーザーの意図や文脈を尊重する個別化されたアライメントの重要性が高まっています。個別化された報酬モデルの開発には、主に二つの大きな困難が存在します。第一に、個々のユーザーから得られるフィードバックが極めて少ないというデータの希少性です。一般的な報酬モデルは膨大なデータに依存しますが、一人のユーザーから大量のフィードバックを収集することは現実的ではありません。他者のデータを単純に統合しても、好みの衝突によってモデルが混乱するため、限られたデータから独自の意図を抽出する必要があります。 第二に、未知のユーザーへの迅速な適応です。…
核心:何を提案したのか
本研究では、個別化された報酬モデリングをメタ学習の問題として再定義する「Meta Reward Modeling(MRM)」を提案しました。これは、各ユーザーの好みに対するモデリングを独立した学習タスクと見なし、モデルが「学習の仕方を学ぶ」ことで、少数のサンプルから迅速に新しいタスクに適応できるようにする画期的なアプローチです。具体的には、モデルの初期パラメータを、あらゆるユーザーの意図に対して最小限の更新で収束できるような「適応性の高い初期状態」として学習させます。MRMの構造的な特徴は、報酬モデルを複数の「共有された基底報酬関数」の重み付き結合として表現する点にあります。各ユーザーの固有の報酬は、これらの基底関数の寄与度を決定する低次元の重みベクトルによって定義されます。この設計により、ユーザーごとの適応を軽量な重みの更新のみで行うことが可能となり、計算効率と学習の安定性を飛躍的に高めています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related