Gained in Translation: Privileged Pairwise Judges Enhance Multilingual Reasoning
現在の大規模言語モデルは英語以外の言語、特に学習データが少ない低リソース言語において推論能力が著しく低下するという深刻な課題を抱えていますが、本研究は対象言語のデータを一切使わずに英語の翻訳データと強化学習のみで能力を向上させる「SP3F」という革新的な二段階フレームワークを提案しました。
TL;DR(結論)
現在の大規模言語モデルは英語以外の言語、特に学習データが少ない低リソース言語において推論能力が著しく低下するという深刻な課題を抱えていますが、本研究は対象言語のデータを一切使わずに英語の翻訳データと強化学習のみで能力を向上させる「SP3F」という革新的な二段階フレームワークを提案しました。 この手法は、第一段階で英語の推論過程を対象言語に翻訳して教師あり微調整を行い、第二段階では英語の正解を「特権情報」として参照できる判定員を用いた自己対戦型強化学習を行うことで、モデルが正解を出せない初期段階からでも質の高いフィードバックを与えることを可能にしています。 検証の結果、提案手法は従来の8分の1という極めて少ない学習データ量でありながら、膨大なデータで事後学習された既存の強力なモデルを複数の数学・非数学タスクで凌駕し、さらに学習時に含まれていない未知の言語に対しても高い汎用性と推論精度を示すことが実証されました。
なぜこの問題か
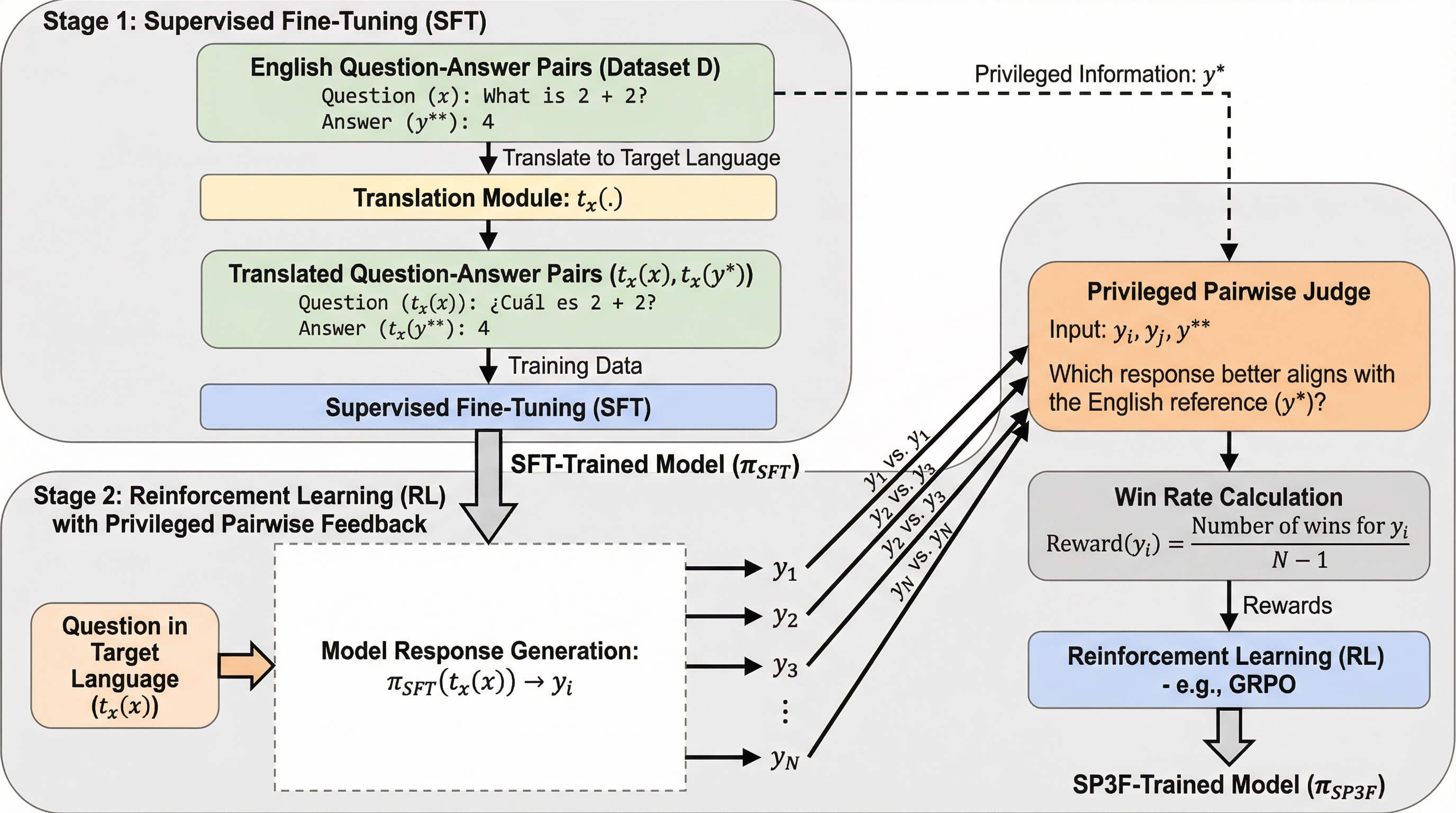
現在の大規模言語モデル(LLM)における推論能力の向上は目覚ましいものがありますが、その学習に使用される「思考の連鎖(Chain of Thought: CoT)」データの大部分は英語で構成されています。この偏りにより、英語以外の言語、特にインドネシア語、スワヒリ語、ベンガル語といった学習データが少ない低リソース言語で同じ質問を投げた場合、モデルの推論性能は英語の時と比較して大幅に低下するという深刻な問題が生じています。多言語において英語と同等の高い推論性能を実現することは、現在のAI技術における非常に困難かつ重要な課題の一つとなっています。 この問題の背景には、主に三つの技術的な障壁が存在します。第一に、教師あり微調整(SFT)を行うために必要な、対象言語での高品質な推論ステップを含むデータが圧倒的に不足している点です。英語では豊富な推論データが存在しますが、他言語で同様の質と量を確保するには膨大なコストがかかります。第二に、ベースとなるモデルが対象言語で正解を出力する確率が極めて低いため、強化学習(RL)において成功のシグナルを得ることが計算コストの面で非常に難しいという「コールドスタート」問題があります。…
核心:何を提案したのか
本研究では、学習データが少ない言語において推論性能が劇的に低下する課題に対し、対象言語のデータを一切追加で収集することなく、既存の英語資産を最大限に活用して多言語推論能力を向上させる二段階フレームワーク「SP3F(Self-Play with Privileged Pairwise Feedback:特権的ペア比較フィードバックを用いた自己対戦)」を提案しました。この手法の核心は、英語の正解情報を「特権(Privileged Information)」として活用し、モデルの自己対戦を通じて学習を加速させる点にあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related