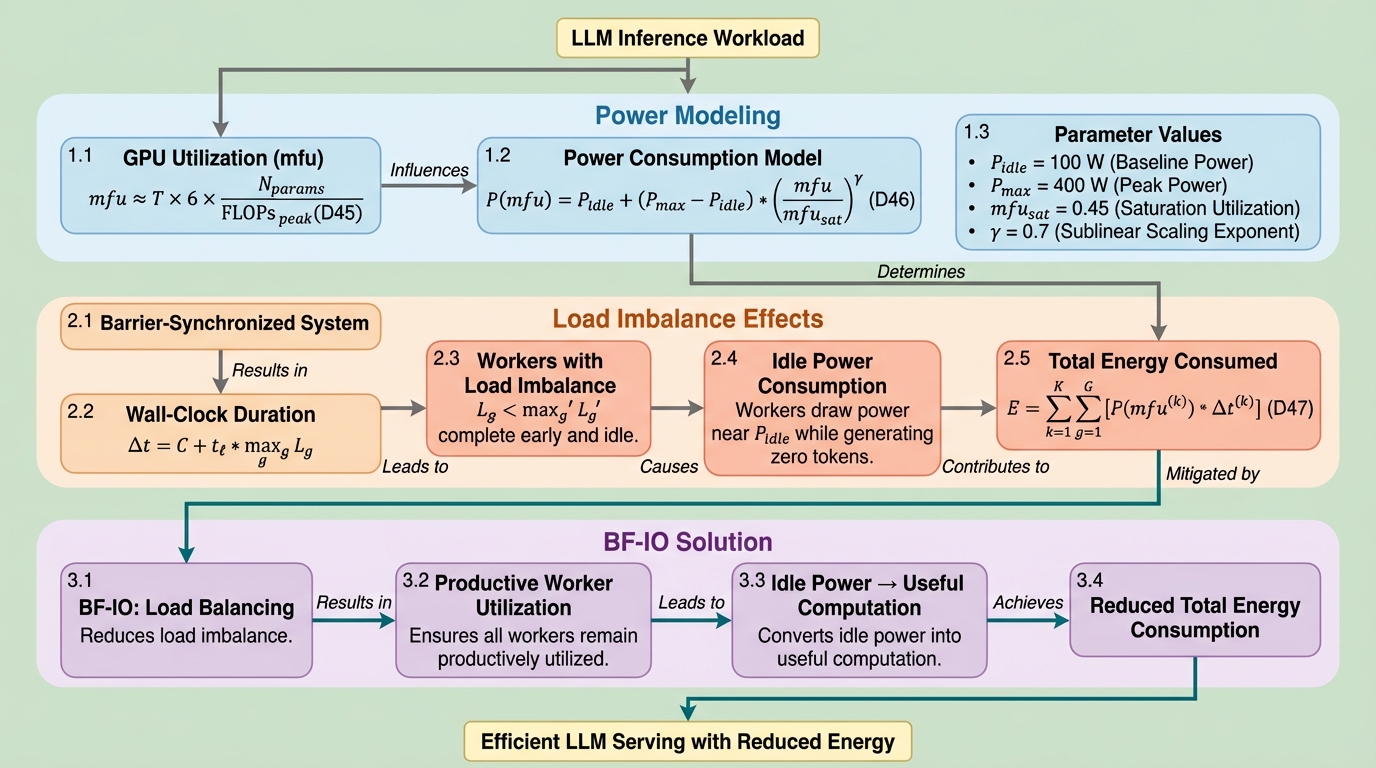
普遍的な負荷分散原理とその大規模言語モデルサービングへの応用
大規模言語モデル(LLM)の推論サービスにおいて、同期バリアによって生じる計算資源の不均衡が深刻なボトルネックとなっており、実際の運用データではデコード工程の40%以上の時間がアイドリング状態で浪費されていることが判明しました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデル(LLM)の推論サービスにおいて、同期バリアによって生じる計算資源の不均衡が深刻なボトルネックとなっており、実際の運用データではデコード工程の40%以上の時間がアイドリング状態で浪費されていることが判明しました。
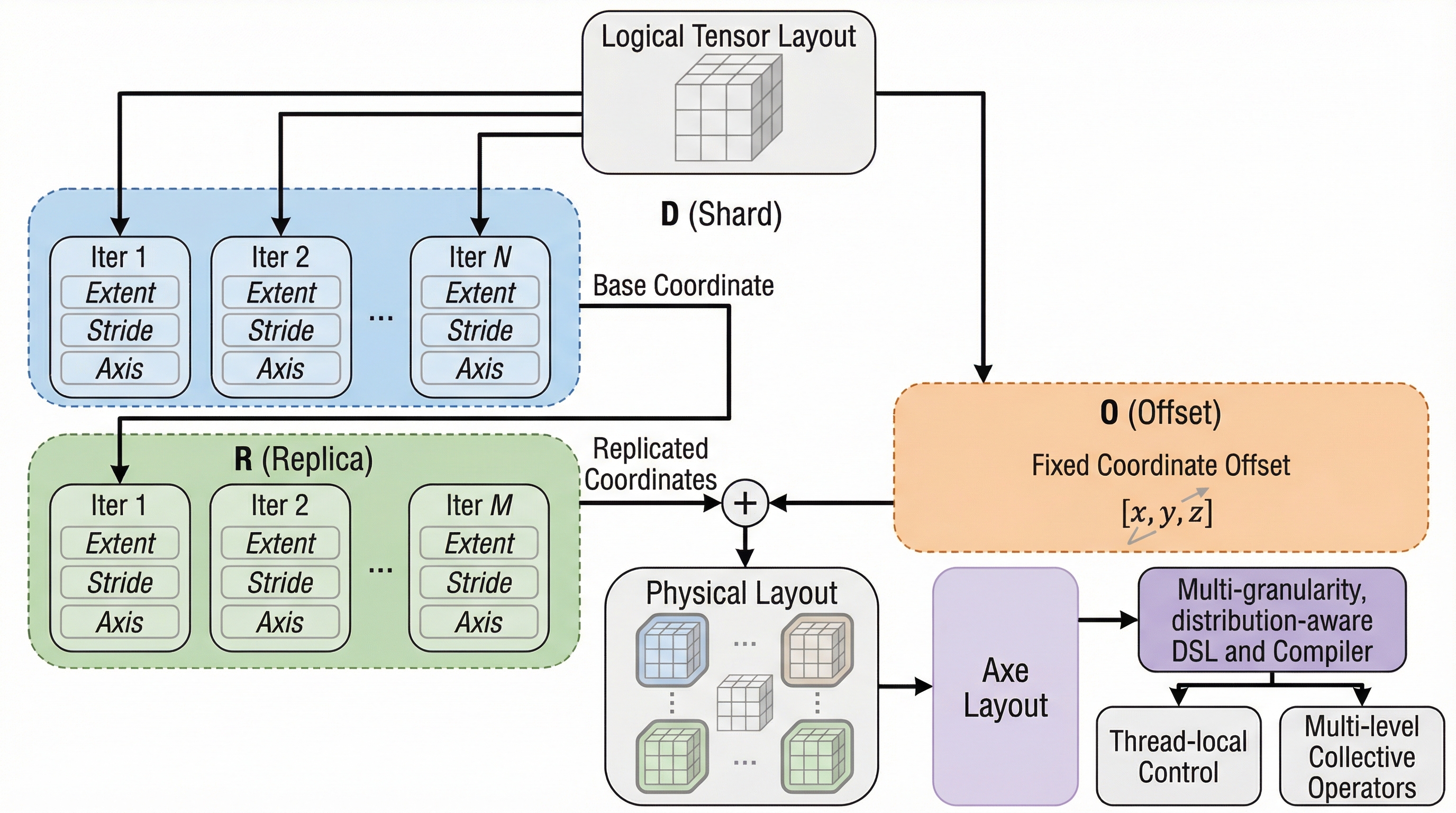
Axeは、論理的なテンソル座標をデバイス、メモリ、スレッドなどのハードウェア軸にマッピングする、ハードウェアを意識した新しい抽象化手法である。 この手法は、デバイス間のデータ分散(シャーディング、複製)とデバイス内のメモリレイアウト(タイリング、オフセット)を単一の形式で統一し、一貫した記述を可能にする。
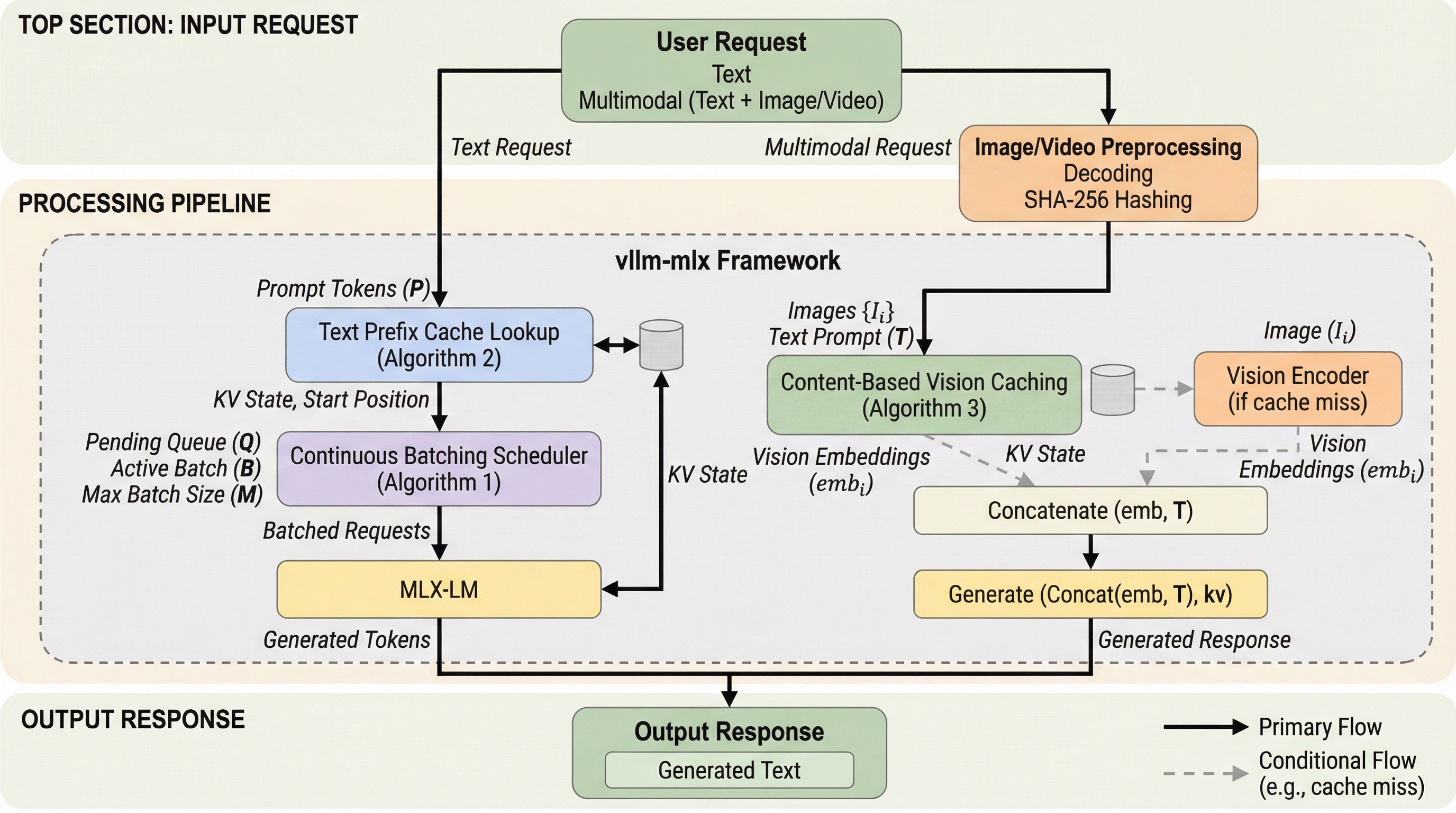
vllm-mlxはAppleシリコンの統合メモリ構造をネイティブに活用し、テキストおよびマルチモーダルLLMの推論を劇的に高速化する新しいオープンソースフレームワークである。 継続的バッチ処理によりllama.
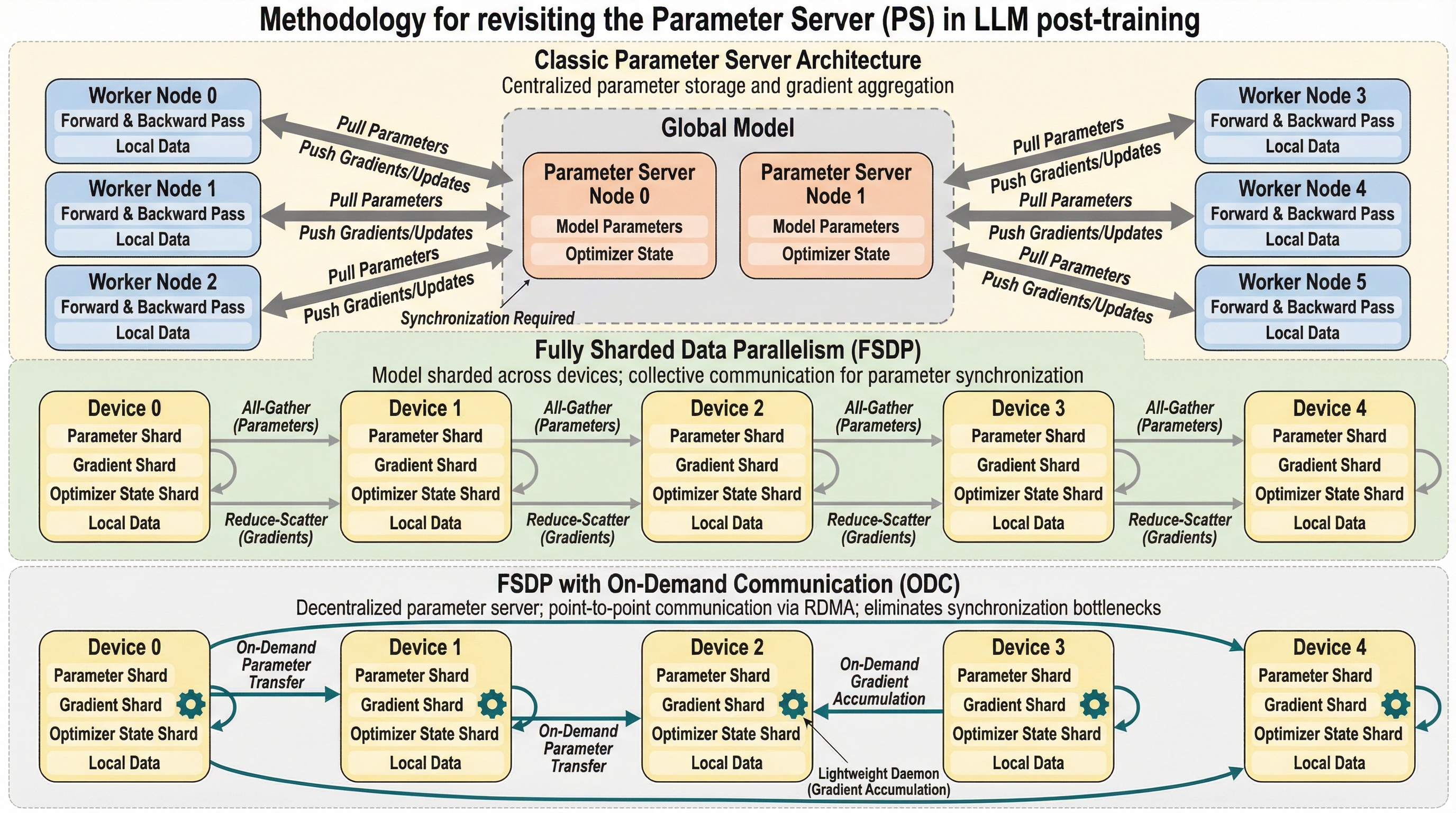
大規模言語モデル(LLM)の事後学習では、入力データのシーケンス長が大きく異なるため、従来の集合通信を用いた分散学習(FSDP)ではデバイス間に深刻な計算負荷の不均衡が生じ、最大50%もの待機時間が発生していました。
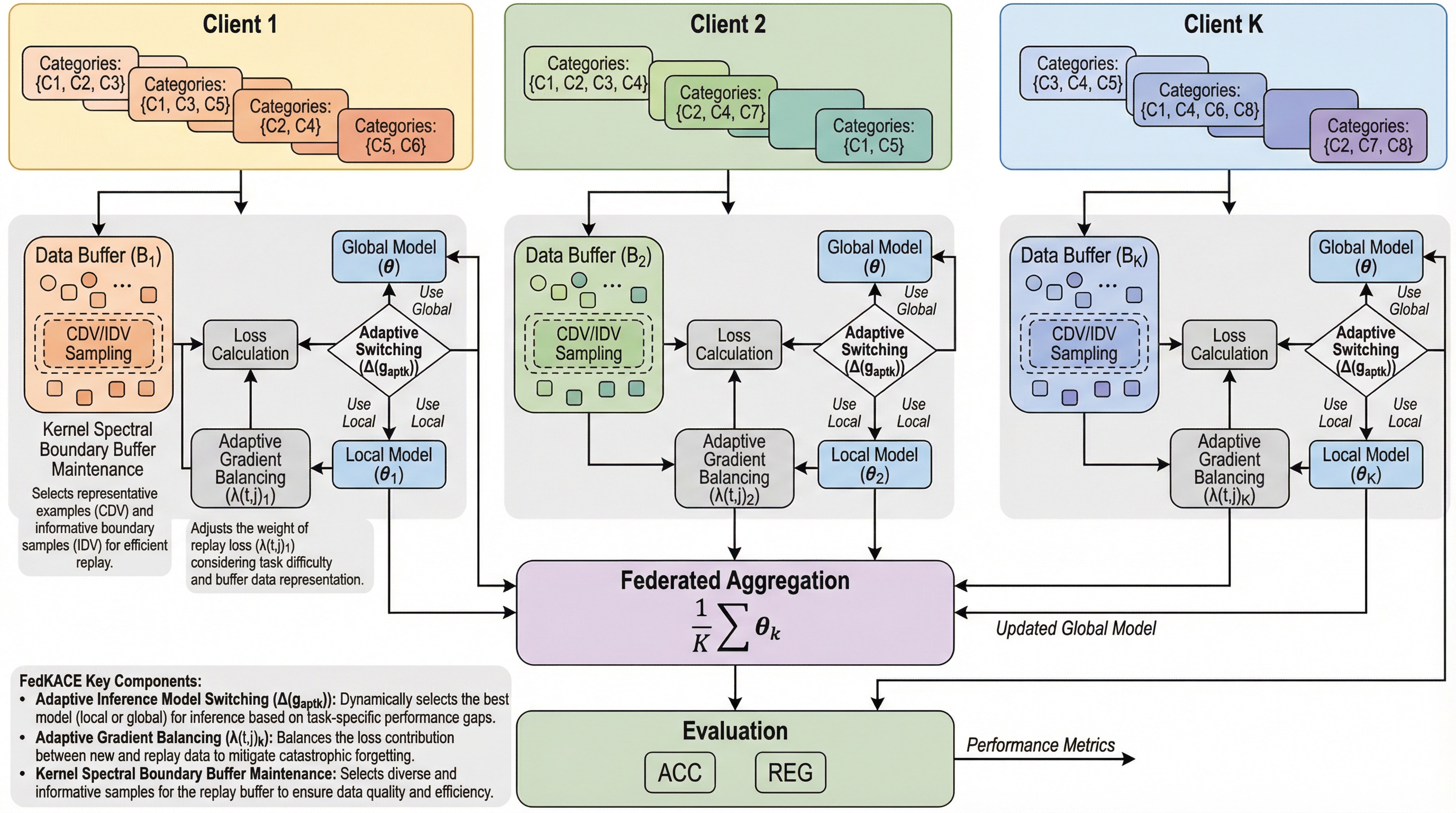
連合学習において、データが連続的に流入し、かつ新旧データ間でカテゴリが重複しながらもタスクの境界を示す識別子(タスクID)が存在しないという、極めて実世界に近い「ストリーミング連合継続学習」の設定を定義し、その特有の課題である知識の混乱や忘却の問題を明確化しました。
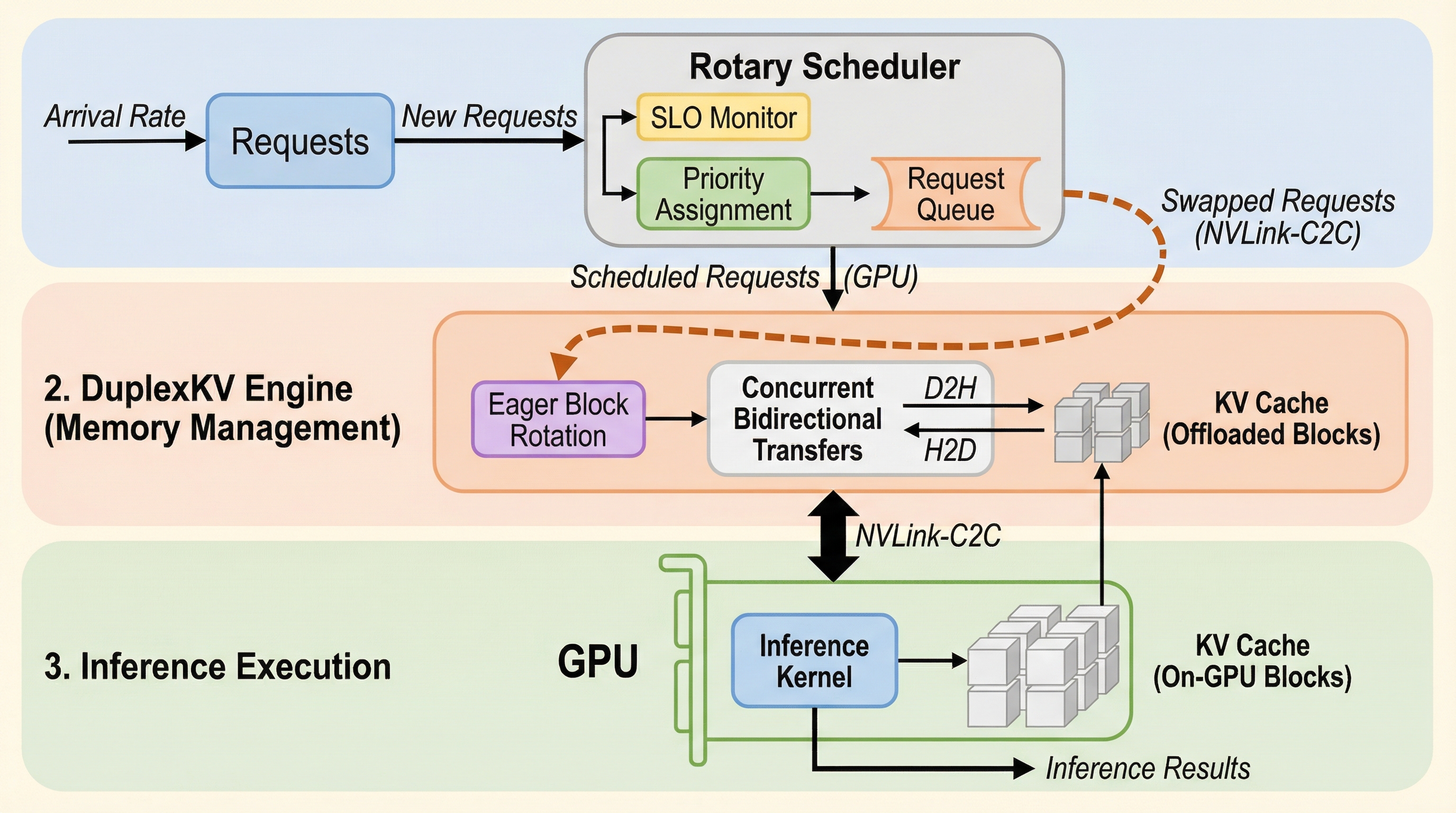
SuperInferは、NVIDIA GH200のようなスーパーチップ環境において、大規模言語モデル(LLM)推論の遅延サービスレベル目標(SLO)を達成するために設計された、新しいスケジューリングおよびメモリ管理システムである。
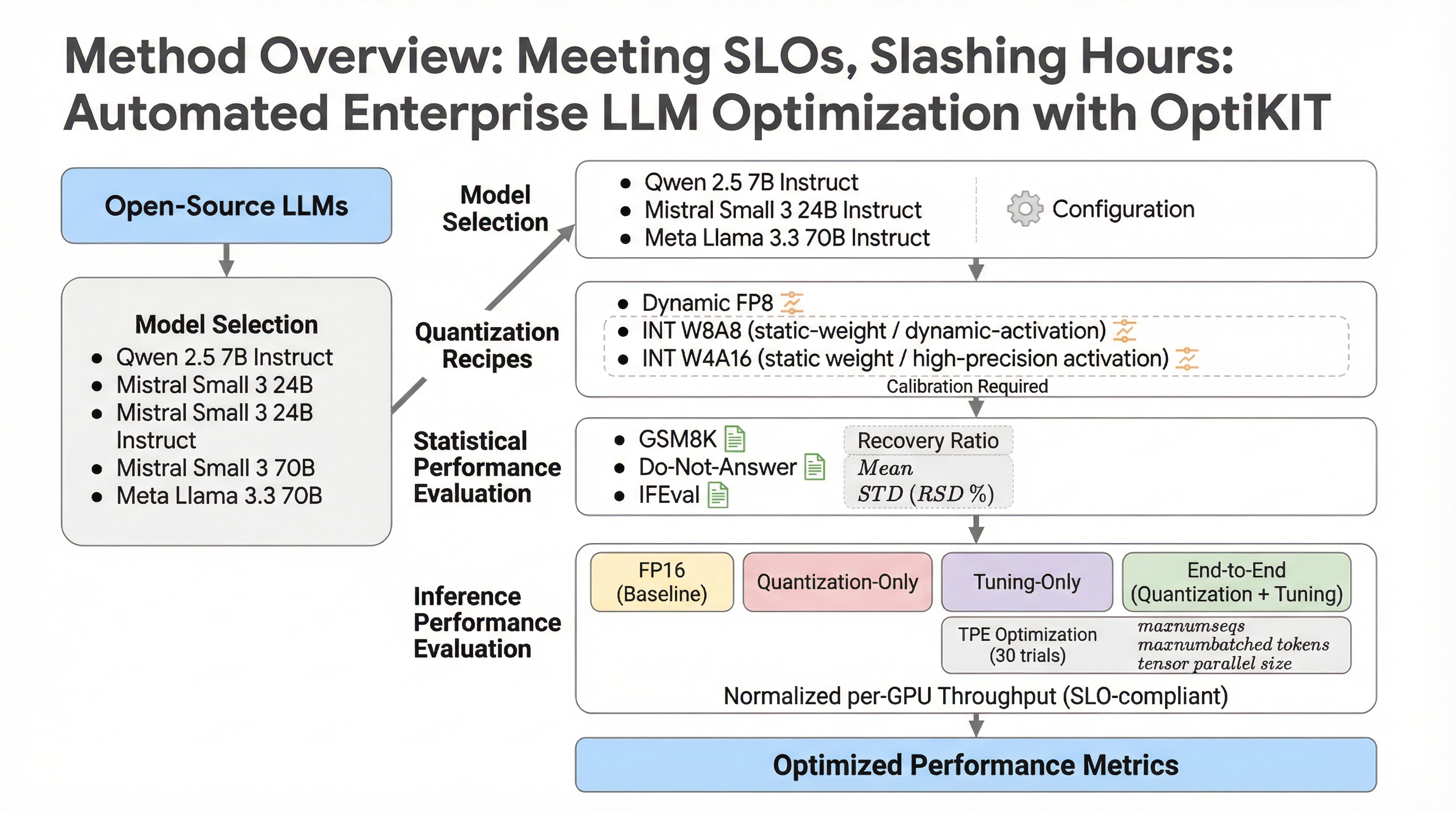
企業が直面する大規模言語モデル(LLM)導入の最大の障壁である、限られたGPU予算内での効率的なスケーリングと、高度な専門知識を要する手動最適化のボトルネックを解消するため、分散型最適化フレームワーク「OptiKIT」を開発しました。
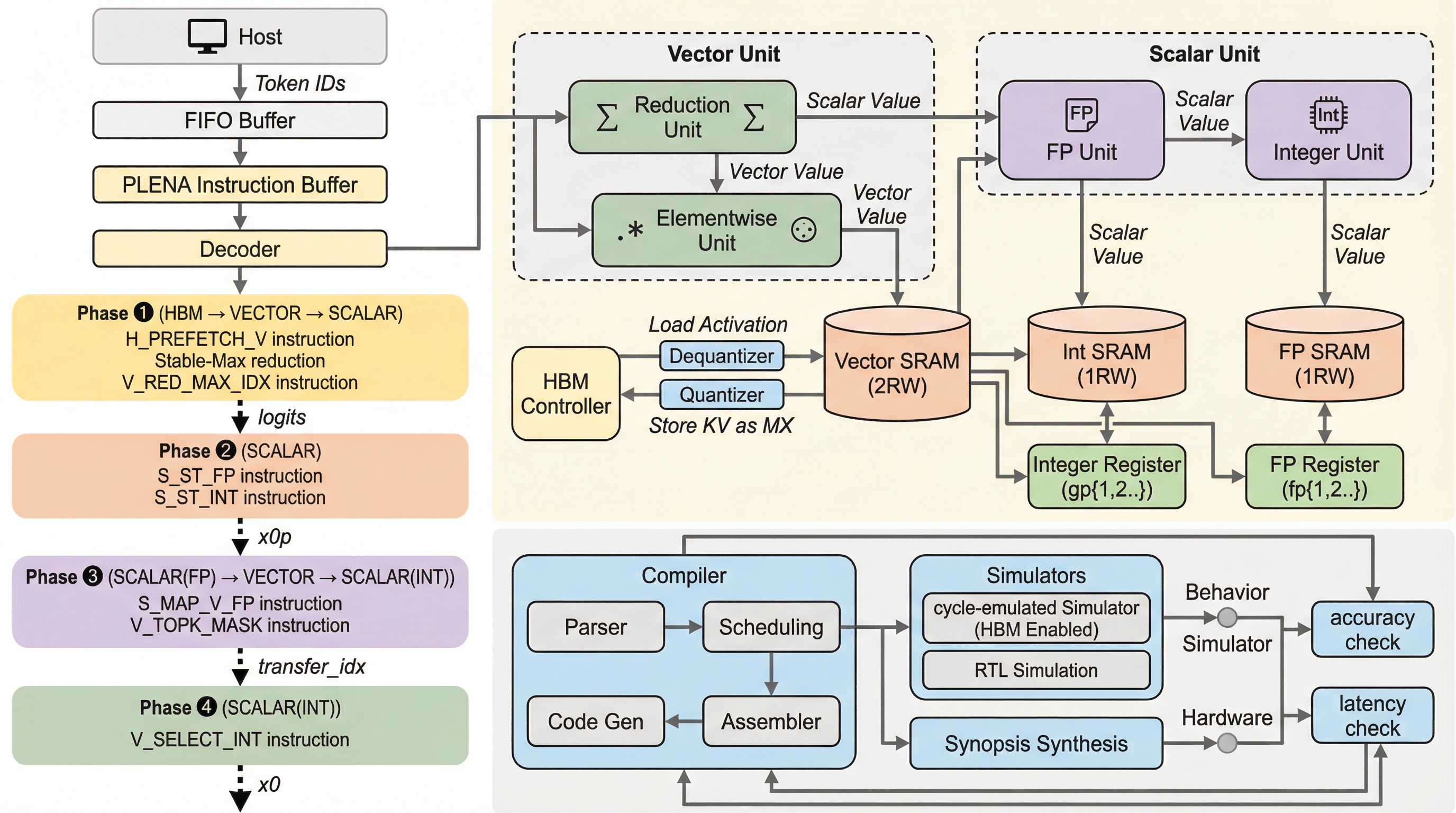
拡散型大規模言語モデル(dLLM)は並列的なトークン生成を可能にするが、語彙全体にわたるロジット処理やトークン選択を行うサンプリング工程が、推論全体の遅延の最大71%を占める深刻なボトルネックとなっている。