タスクIDなし・カテゴリ重複ありのストリーミング環境に対応する連合継続学習「FedKACE」
連合学習において、データが連続的に流入し、かつ新旧データ間でカテゴリが重複しながらもタスクの境界を示す識別子(タスクID)が存在しないという、極めて実世界に近い「ストリーミング連合継続学習」の設定を定義し、その特有の課題である知識の混乱や忘却の問題を明確化しました。
TL;DR(結論)
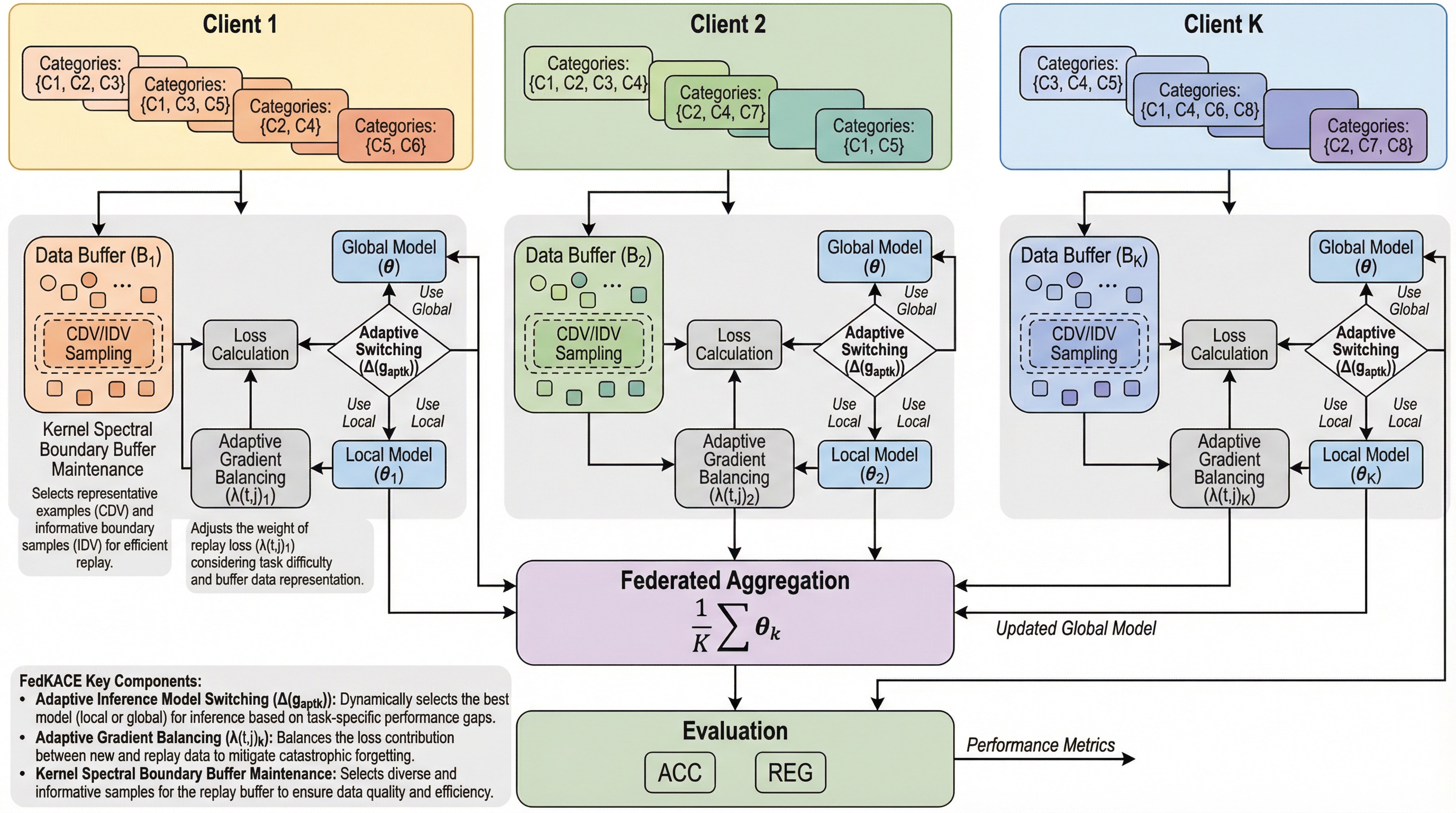
連合学習において、データが連続的に流入し、かつ新旧データ間でカテゴリが重複しながらもタスクの境界を示す識別子(タスクID)が存在しないという、極めて実世界に近い「ストリーミング連合継続学習」の設定を定義し、その特有の課題である知識の混乱や忘却の問題を明確化しました。 この困難な課題を解決するため、推論モデルをローカルからグローバルへ適応的に切り替える仕組み、出力層の勾配比率に基づき新旧知識の学習バランスを自動調整するリプレイ手法、およびカーネルスペクトル境界理論を用いて重要なサンプルを厳選するバッファ維持法の3要素からなる「FedKACE」フレームワークを提案しました。 理論的な後悔(リグレット)分析と広範な実験により、提案手法が理論的な収束性と優れた汎用性能を両立し、通信や計算の負荷を最小限に抑えつつ、データの異質性が高い環境でも過去の知識を保持しながら新しい知識を効率的に獲得できることを実証しました。
なぜこの問題か
従来の連合学習(FL)は、各クライアントが保持するデータが静的であることを前提として設計されていますが、現実世界のアプリケーションではデータは時間とともに絶えず変化し続けるため、新しい知識を学びつつ過去の知識を忘れない継続学習の能力が不可欠です。これに対応する連合継続学習(FCL)の研究が近年進んでいますが、既存手法の多くは、データがバッチ形式で提供され、同じデータを何度も繰り返し学習できることや、タスクの境界を示す識別子が明示されていることを前提としています。しかし、現実のストリーミング環境では、データは一度しかアクセスできない連続的な流れとして現れ、さらに過去に登場したカテゴリが新しいデータの中に再び現れる「カテゴリの重複」が頻繁に発生します。タスク識別子がない状況でカテゴリが重複すると、モデルはどの知識が新しく、どの知識が古いものかを区別できなくなり、同じカテゴリのサンプルが異なるタスクに誤って割り当てられるなど、知識の混乱が生じて学習の精度が著しく低下するという深刻な問題があります。…
核心:何を提案したのか
本論文では、ストリーミング連合継続学習の課題を包括的に解決するための新しいフレームワークとして「FedKACE(Federated Knowledge-Aware Continual Evolution)」を提案しました。FedKACEの核心は、クライアントが直面する知識の混乱とリソースの制約を、3つの適応的なメカニズムによって解消することにあります。第一に、推論に使用するモデルをローカルからグローバルへと適切なタイミングで切り替える「適応的推論モデル切り替えメカニズム」を導入しました。これは、学習の進展に伴ってグローバルモデルの汎化性能がローカルモデルを上回るタイミングを、バッファデータを用いた統計的な指標で自動的に検知する画期的な仕組みです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related