LLMポストトレーニングにおけるパラメータサーバの再考
大規模言語モデル(LLM)の事後学習では、入力データのシーケンス長が大きく異なるため、従来の集合通信を用いた分散学習(FSDP)ではデバイス間に深刻な計算負荷の不均衡が生じ、最大50%もの待機時間が発生していました。
TL;DR(結論)
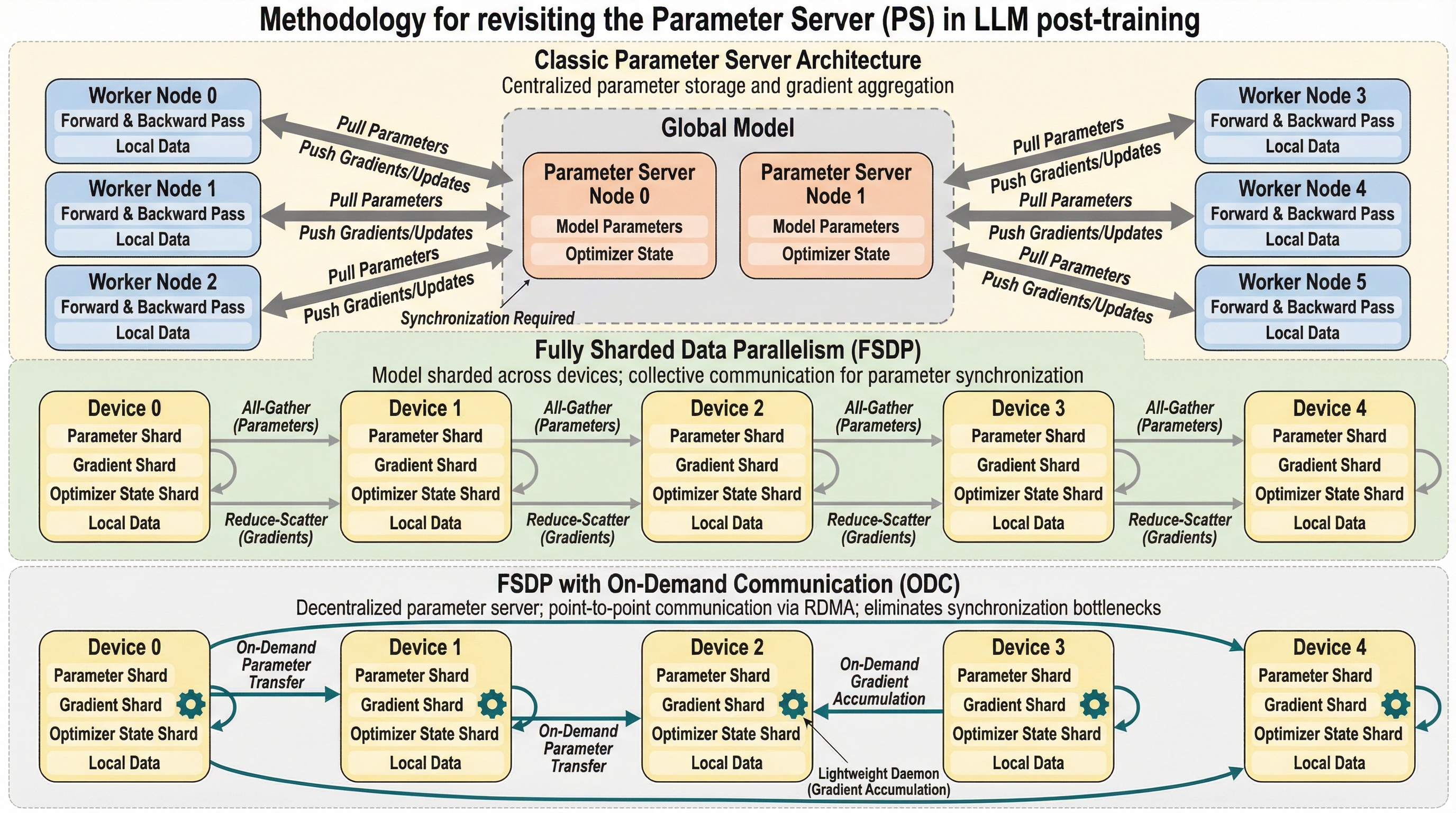
大規模言語モデル(LLM)の事後学習では、入力データのシーケンス長が大きく異なるため、従来の集合通信を用いた分散学習(FSDP)ではデバイス間に深刻な計算負荷の不均衡が生じ、最大50%もの待機時間が発生していました。本研究では、古典的なパラメータサーバの概念を現代のFSDPに統合した「オンデマンド通信(ODC)」を提案し、レイヤーごとの同期を排除してミニバッチ単位での緩やかな同期を実現しました。検証の結果、ODCは教師あり微調整(SFT)や強化学習(RL)において、標準的なFSDPと比較して最大36%の高速化を達成し、計算リソースの利用効率を劇的に向上させることが確認されました。この手法は、メモリ効率を維持したまま、不均衡なワークロードに対して高い耐性を持つ次世代の学習基盤となります。
なぜこの問題か
現代の分散学習、特にデータ並列(DP)学習の分野では、計算負荷が全デバイスで均一であることを前提として、シンプルで効率的な集合通信(Collective Communication)が主流となってきました。初期の分散システムでは、ネットワークの遅延やハードウェアの異質性に対応するためにパラメータサーバ(PS)方式が採用されていましたが、GPUクラスターの均質化と高帯域な相互接続の普及により、NCCLなどのライブラリを用いた集合通信が標準的な地位を確立しました。このパラダイムの成功は、画像認識や音声認識、初期の自然言語処理といった、ワークロードが比較的安定しているドメインに支えられてきました。しかし、大規模言語モデル(LLM)の事後学習(Post-training)の段階において、この「負荷が均一である」という長年の前提が根本から崩れつつあります。 実際のテキストデータには極端に短いものから非常に長いものまで多様なシーケンスが含まれており、アテンション機構の計算コストがシーケンス長の二乗で増加するため、デバイス間での計算時間の差が顕著になります。…
核心:何を提案したのか
本研究では、不均衡な負荷に対して堅牢であった古典的なパラメータサーバ(PS)の概念を現代のFSDPに再導入する「オンデマンド通信(ODC)」を提案しています。ODCの核心は、従来のFSDPが依存していたレイヤーごとの集合通信を、ポイント・ツー・ポイント(P2P)の通信プリミティブに置き換えることにあります。これにより、各デバイスは他のデバイスの進行状況に縛られることなく、自分が必要なタイミングでパラメータを取得し、計算が終わった瞬間に勾配を送信することが可能になります。具体的には、FSDPのメモリレイアウトを維持したまま、all-gatherを特定のデバイスから必要なシャードだけを取得するgather操作に、reduce-scatterを計算済みの勾配を直接送信して蓄積するscatter-accumulate操作に変更しています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related