SuperInfer:スーパーチップ上でのLLM推論を最適化するSLO認識型スケジューリングとメモリ管理
SuperInferは、NVIDIA GH200のようなスーパーチップ環境において、大規模言語モデル(LLM)推論の遅延サービスレベル目標(SLO)を達成するために設計された、新しいスケジューリングおよびメモリ管理システムである。
TL;DR(結論)
SuperInferは、NVIDIA GH200のようなスーパーチップ環境において、大規模言語モデル(LLM)推論の遅延サービスレベル目標(SLO)を達成するために設計された、新しいスケジューリングおよびメモリ管理システムである。 オペレーティングシステムの設計思想を取り入れたプロアクティブなロータリースケジューラ「RotaSched」と、NVLink-C2Cの全二重通信を最大限に活用する転送エンジン「DuplexKV」を組み合わせることで、メモリ不足による処理の停滞を解消する。 評価の結果、既存の最先端システムと比較して、スループットを維持しながら最初のトークン生成までの時間(TTFT)のSLO達成率を最大74.7%向上させ、スーパーチップの広帯域なハードウェア性能をソフトウェア側から引き出すことに成功した。
なぜこの問題か
大規模言語モデル(LLM)のサービス提供において、ユーザーの満足度を左右するのは応答の速さであり、これを保証するために「最初のトークンが出るまでの時間(TTFT)」や「トークン間の生成時間(TBT)」に対して厳しいサービスレベル目標(SLO)が設定される。しかし、LLMの推論プロセスでは、各リクエストが生成中に増大し続けるキー・バリュー(KV)キャッシュを保持する必要があり、これがGPUメモリを大量に消費するという根本的な課題がある。リクエストが急増してGPUメモリが枯渇すると、新しいリクエストが処理を開始できなくなる「先頭待機(HOL)ブロッキング」が発生し、TTFTのSLO違反が深刻化する。 このメモリ不足を解消するために、KVキャッシュをCPUメモリへ一時的に退避させる「オフロード」技術が研究されてきたが、従来のシステムには大きな欠点が二つあった。第一に、既存のオフロードポリシーはSLOを認識しておらず、メモリ不足に対して受動的に反応するだけである。例えば、待機中のリクエストを優先する「Waiting-First」ポリシーはTTFTを改善するが、実行中のリクエストを長時間中断させるためTBTを悪化させる。…
核心:何を提案したのか
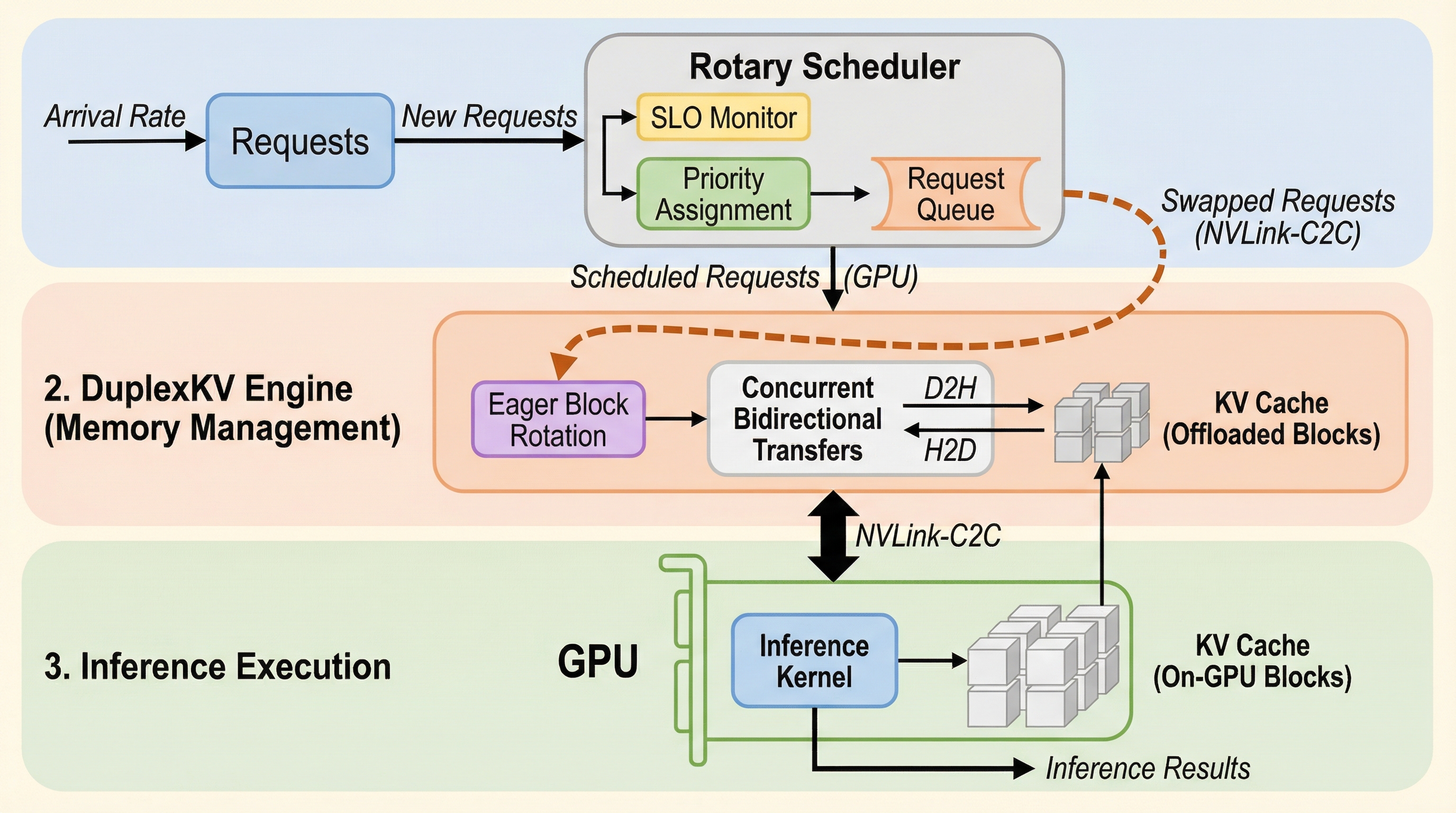
本論文では、スーパーチップの密結合なGPU-CPUアーキテクチャを最大限に活用し、SLOを認識したLLM推論を実現するシステム「SuperInfer」を提案している。このシステムの核心は、ハードウェアの特性に合わせたソフトウェアの再設計にあり、特にオペレーティングシステム(OS)のスケジューリング概念をLLM推論のメモリ管理に応用した点にある。SuperInferは、リクエストを単に「実行中」か「待機中」かで分けるのではなく、高速なメモリ転送を前提とした「ロータリー(回転)」という新しい状態を導入した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related