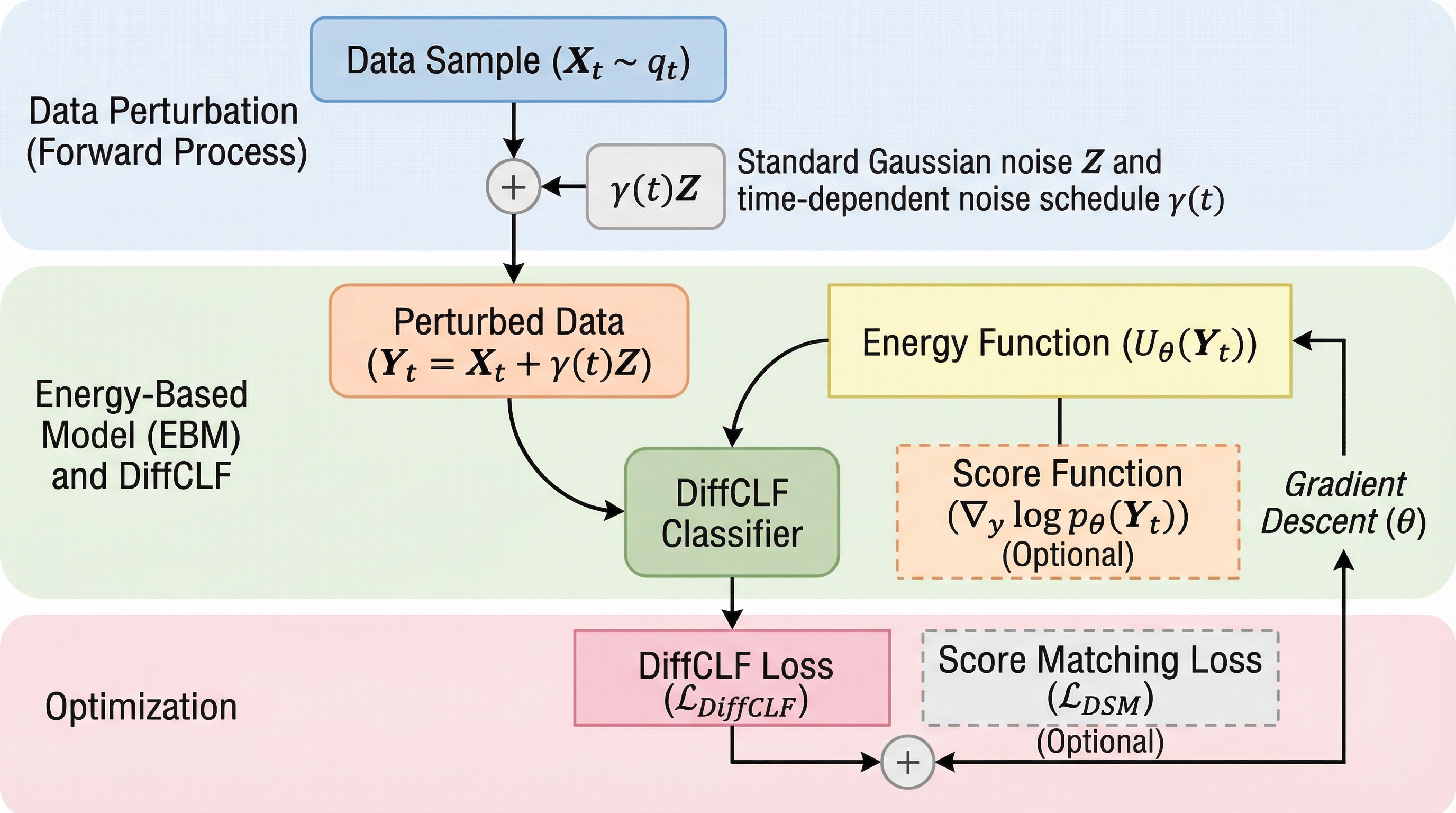
エネルギーベース生成モデル学習のための拡散分類損失
従来のスコアマッチング手法は、離れた高密度領域間の相対的な重みを正しく推定できない「モード盲目性」という根本的な課題を抱えていたが、本研究はこの問題を解決するために、エネルギーベースモデル(EBM)の学習を異なるノイズレベル間での教師あり分類問題として再定義する新しい目的関数「Diffusive Classification(DiffCLF)」を提案した。 DiffCLFは、モデルにどの時間ステップのノイズが付加されたデータであるかを識別させることで、エネルギー関数とその正規化定数を直接的かつ正確に推定することを可能にし、従来のデノイジング・スコアマッチングと容易に組み合わせることができる軽量で柔軟な枠組みを提供するとともに、理論的にも真の分布を一意に復元できることが証明されている。 ガウス混合モデルを用いた検証や、物理学・化学分野でのボルツマンジェネレーターの構築、複数のモデルを組み合わせる合成タスクにおいて、提案手法は既存のスコアベース手法を上回る高い忠実度と広範な適用性を示し、生成品質の維持と正確なエネルギー値の利用を両立させることで、生成AIの応用範囲を大きく広げる成果を達成した。