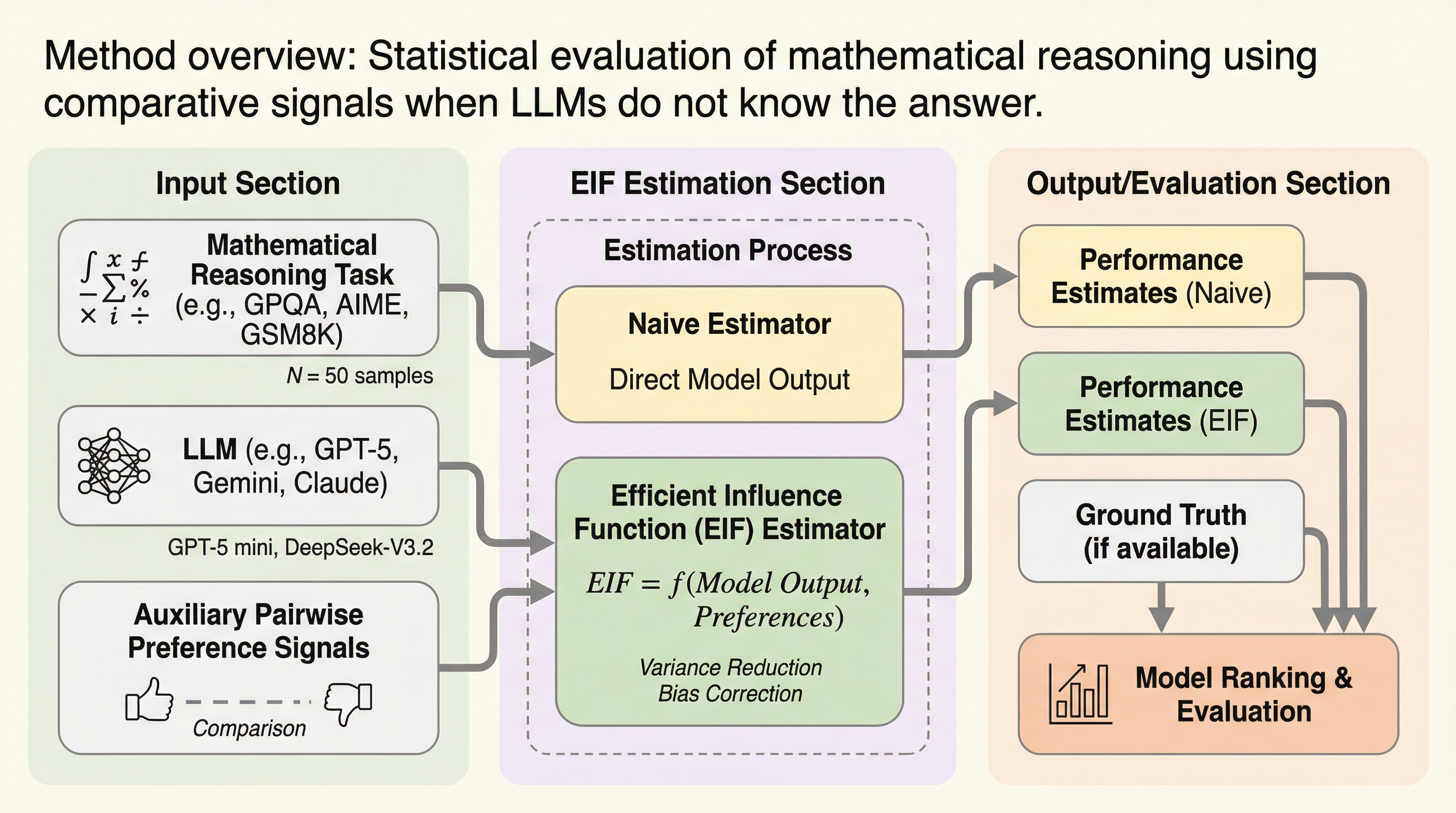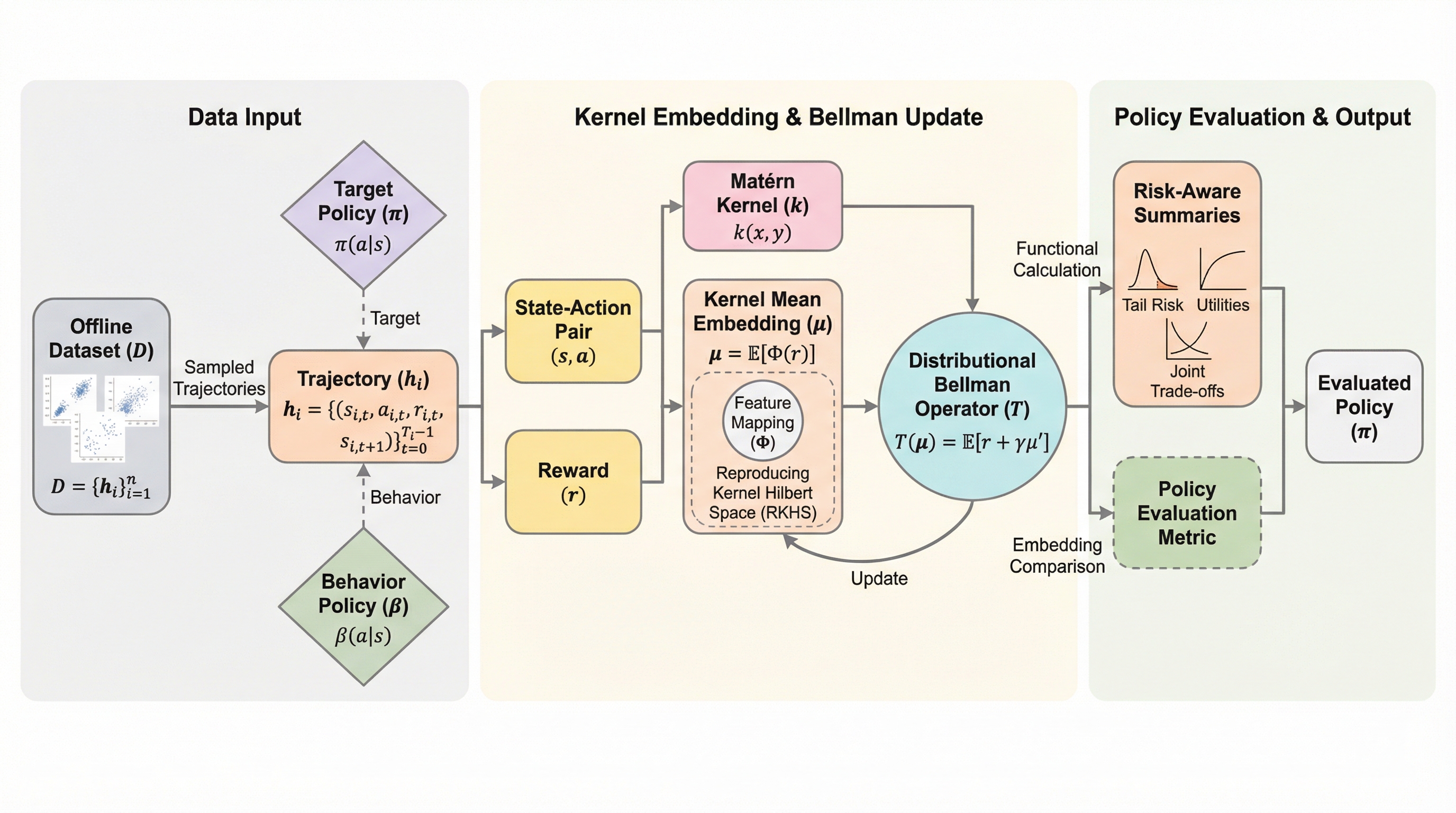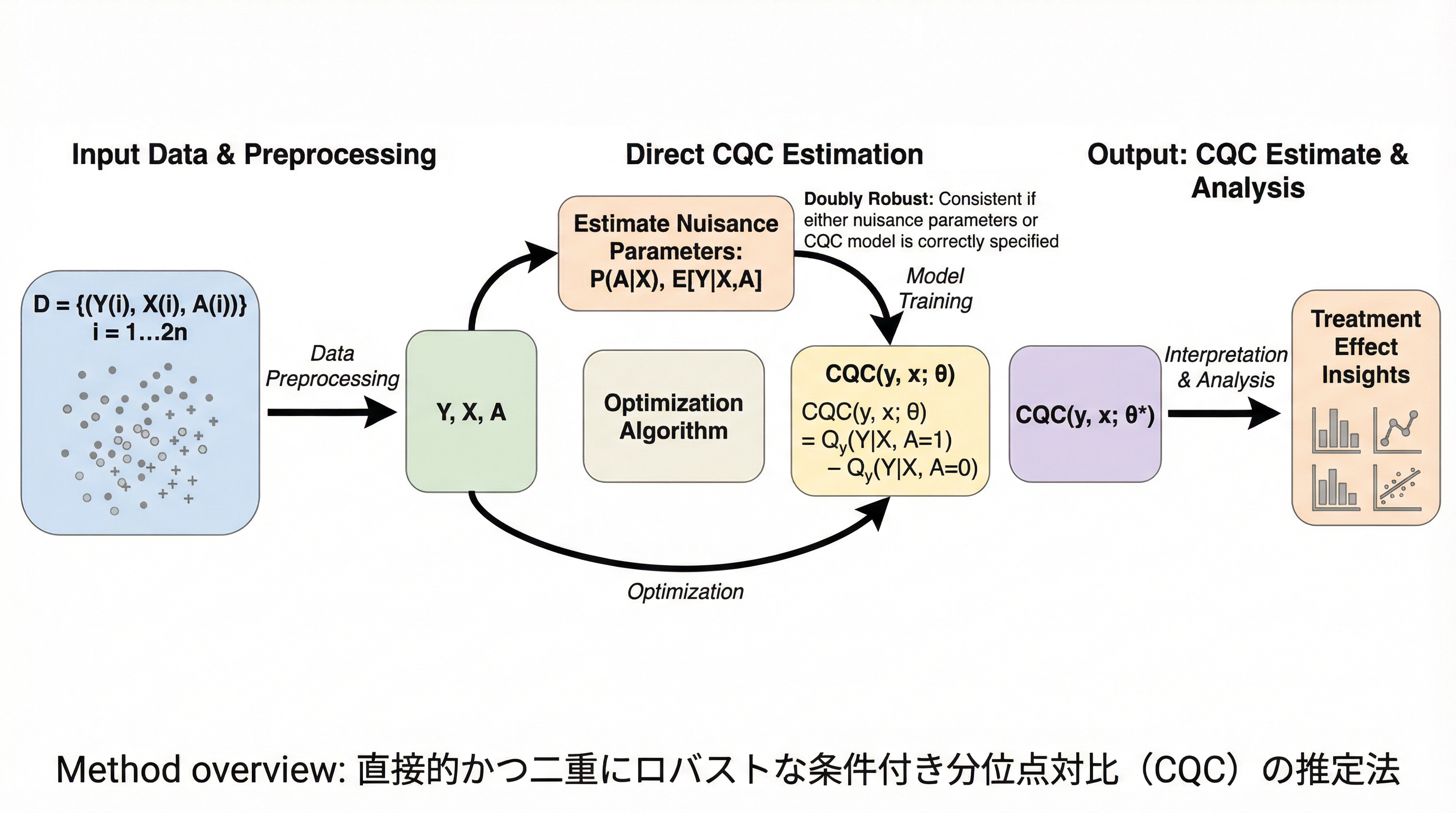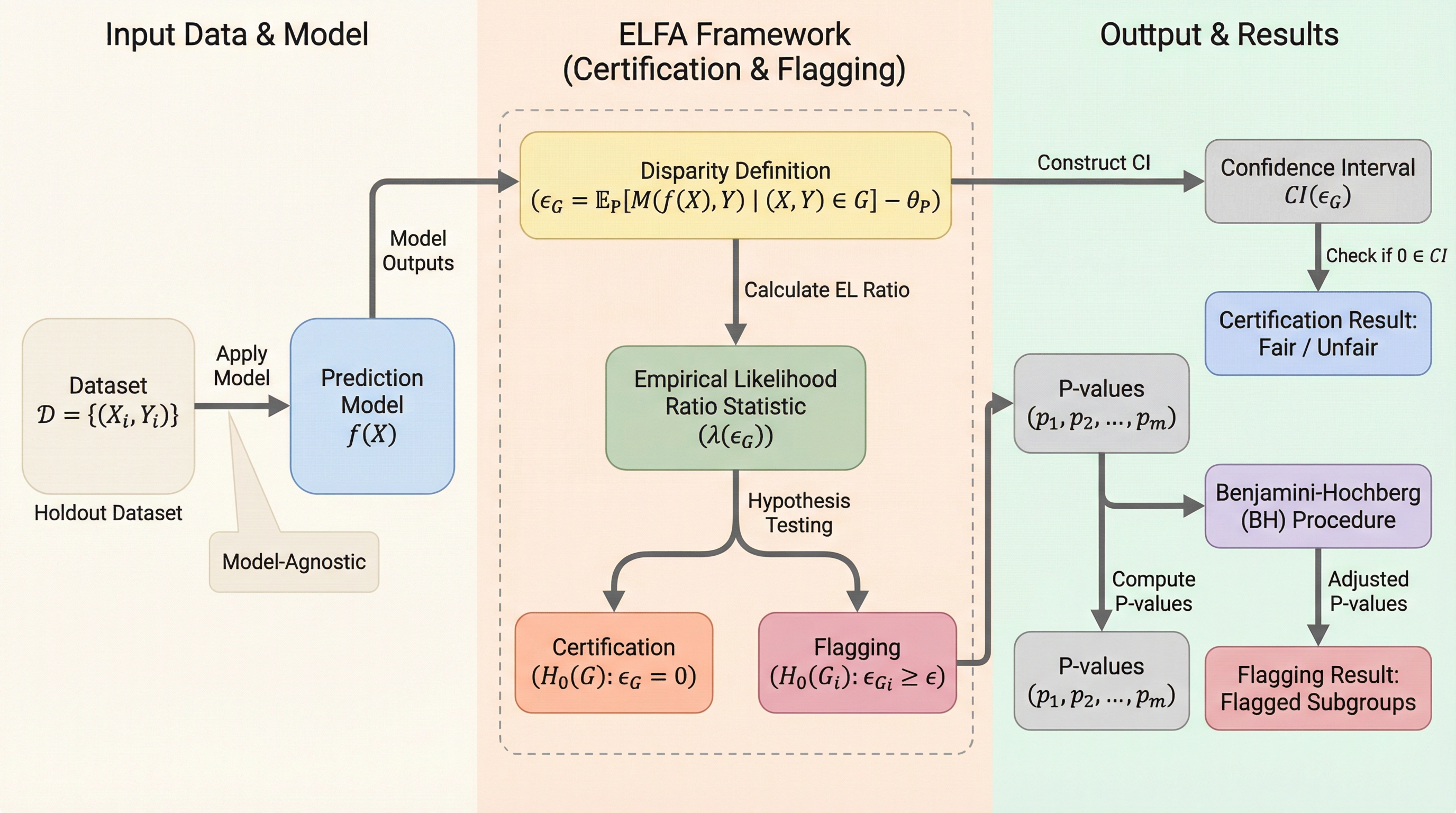
パフォーマティブ予測における単一・複数プレイヤーの統一的推論フレームワーク:手法と漸近的最適性
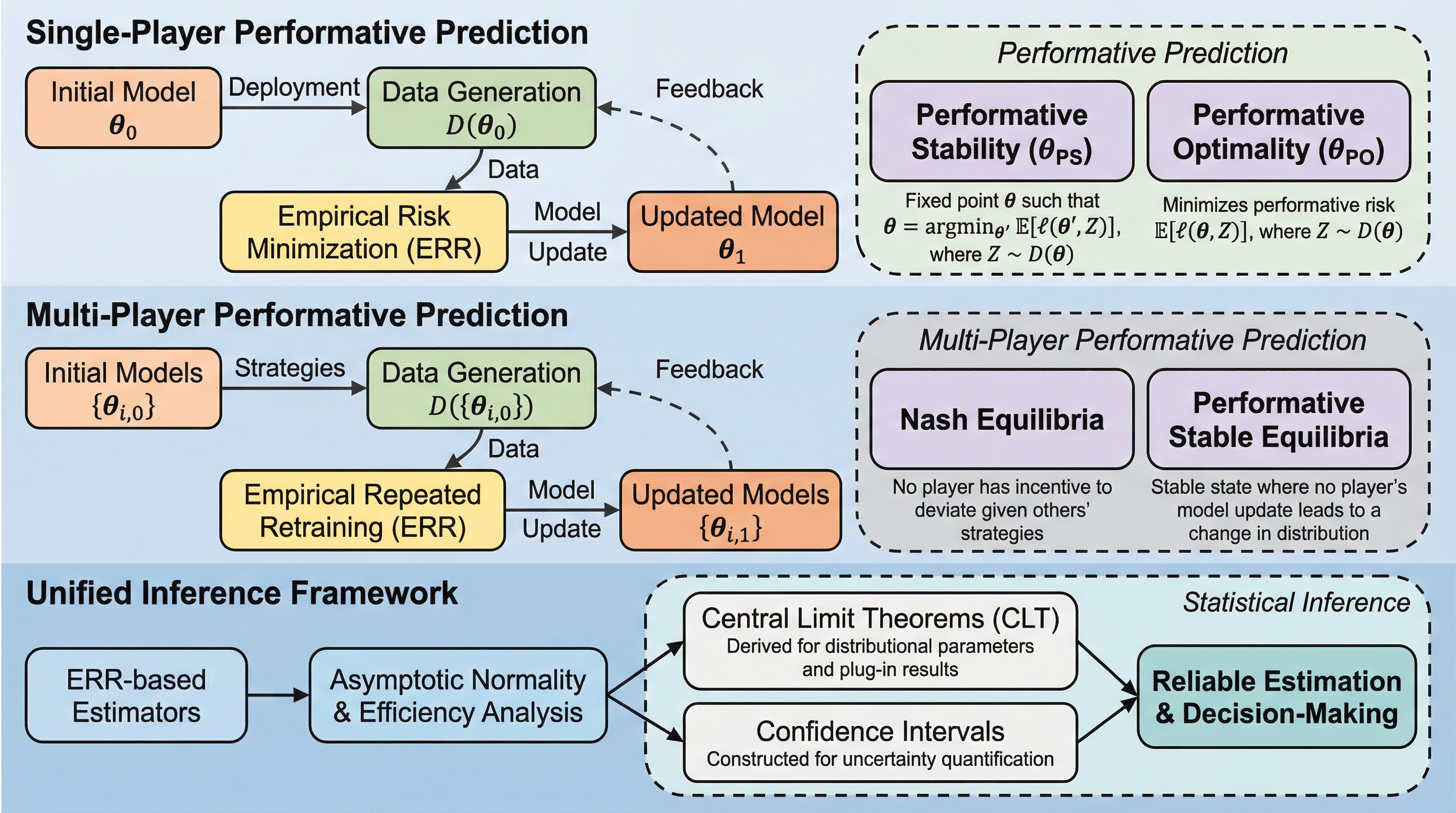
パフォーマティブ予測とは、予測モデルの導入自体が予測対象のデータ分布を変化させ、複雑なフィードバックループを引き起こす環境を特徴づける概念である。本研究では、これまで個別に扱われてきた単一エージェントと複数エージェントのパフォーマティブ性を統合的に扱う統計的推論フレームワークを導入し、前者を後者の特殊なケースとして定義した。 パフォーマティブ安定性の推定には反復的リスク最小化(RRM)の手順を提案し、その漸近正規性と漸近効率性を厳密な推論理論によって確立することで、モデルの安定性と信頼性を評価する基盤を構築した。また、パフォーマティブ最適性については、再校正済み予測動力推論(RePPI)と重要サンプリングを統合した新しい二段階プラグイン推定量を導入している。 このフレームワークは、分布パラメータとプラグイン結果の両方に対して中心極限定理の形式的な導出を行い、提案された推定値が半パラメトリック効率限界を達成し、分布の誤設定に対しても堅牢であることを示した。これにより、動的でパフォーマティブな環境における信頼性の高い推定と意思決定のための、原則に基づいたツールキットが提供されることになった。