経験的尤度に基づく公平性監査:分布に依存しない認証とフラグ付け
AIモデルのバイアスを検出するための新しい統計的枠組み「ELF A」を提案します。この手法は、データの背後にある分布を仮定しない非パラメトリックなアプローチであり、従来のブートストラップ法に比べて計算速度が数千倍から数万倍速く、統計的な正確性も高いという特徴があります。
TL;DR(結論)
AIモデルのバイアスを検出するための新しい統計的枠組み「ELF A」を提案します。この手法は、データの背後にある分布を仮定しない非パラメトリックなアプローチであり、従来のブートストラップ法に比べて計算速度が数千倍から数万倍速く、統計的な正確性も高いという特徴があります。具体的には、特定の属性グループに対する予測の偏りを「認証(公平性の証明)」と「フラグ付け(不公平なグループの特定)」の2つの機能で厳密に評価し、交差的なバイアスも正確に検出可能です。
なぜこの問題か
現代社会において、人工知能(AI)は採用、融資の承認、リスク評価、医療資源の配分、さらには刑事司法といった人生を左右する重要な意思決定プロセスに深く組み込まれています。しかし、予測精度が高いモデルであっても、それが必ずしも公平であることを保証するわけではありません。過去の偏ったデータで学習されたモデルは、既存の体系的なバイアスを維持し、さらには増幅させることで、意思決定における不平等を悪化させる深刻なリスクを孕んでいます。例えば、米国の刑事司法制度で使用されている再犯予測アルゴリズムにおいて、アフリカ系アメリカ人の誤検知率が白人の受刑者よりも大幅に高いことが報告されており、社会的な議論を呼んでいます。また、ターゲット広告や自動採用システムにおいても、特定の属性に対する差別的な扱いが文書化されています。このようなリスクに対応するため、第三者による公平性監査は、AIの信頼性を高めるための不可欠なメカニズムとなっています。公平性監査には主に2つの役割があり、一つはモデルが公平性の制約を遵守しているかを確認する「認証」であり、もう一つは不当な扱いを受けている特定の人口統計グループを特定する「フラグ付け」です。…
核心:何を提案したのか
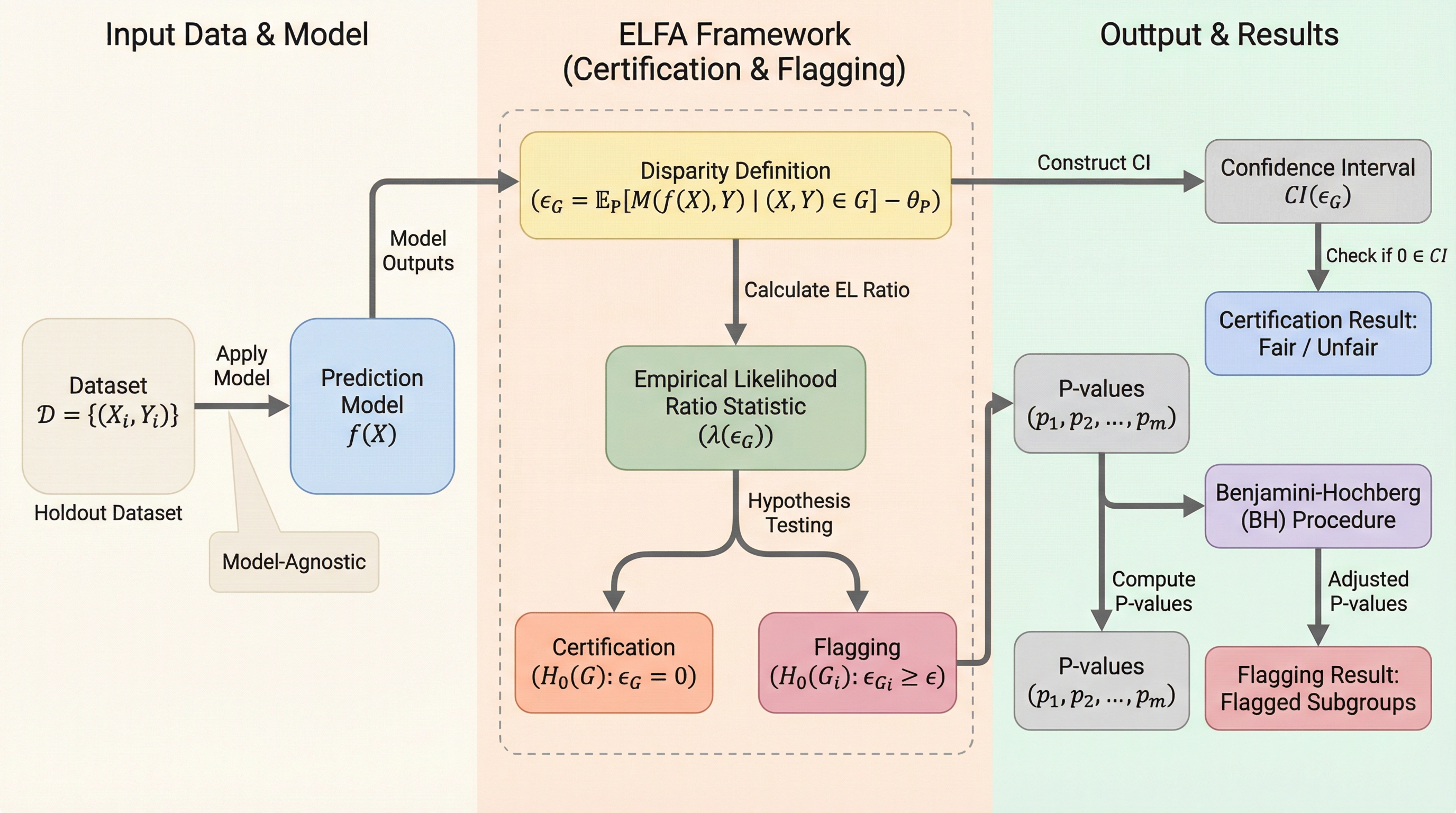
本論文の核心は、経験的尤度(Empirical Likelihood, EL)に基づいた公平性監査フレームワーク「ELF A」の提案にあります。経験的尤度法は、パラメトリックな分布の仮定を一切必要としないため、現実世界の複雑で多様なデータに対して非常に堅牢であるという大きな利点を持っています。このフレームワークは、モデルの出力のみを使用する「モデル・アグノスティック(モデルに依存しない)」な設計となっており、深層学習から線形モデルまで、あらゆる機械学習モデルに適用可能です。ELF Aの主な革新性は、モデルの性能格差に関する統計的尺度を構築し、その統計量が漸近的にカイ二乗分布に従うことを数学的に証明した点にあります。これにより、従来のブートストラップ法のように重い計算負荷をかけるリサンプリングを繰り返すことなく、厳密な信頼区間を構築し、統計的な推論を行うことが可能になりました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related