LLMが答えを知らない場合の評価:比較信号を用いた数学的推論の統計的評価
大規模言語モデル(LLM)の数学的推論能力の評価において、ベンチマークのサイズ制限とモデルの確率的な変動が原因で、評価結果の分散が大きくなりランキングが不安定になる「再現性の危機」を解決するための統計的枠組みを提案した。
TL;DR(結論)
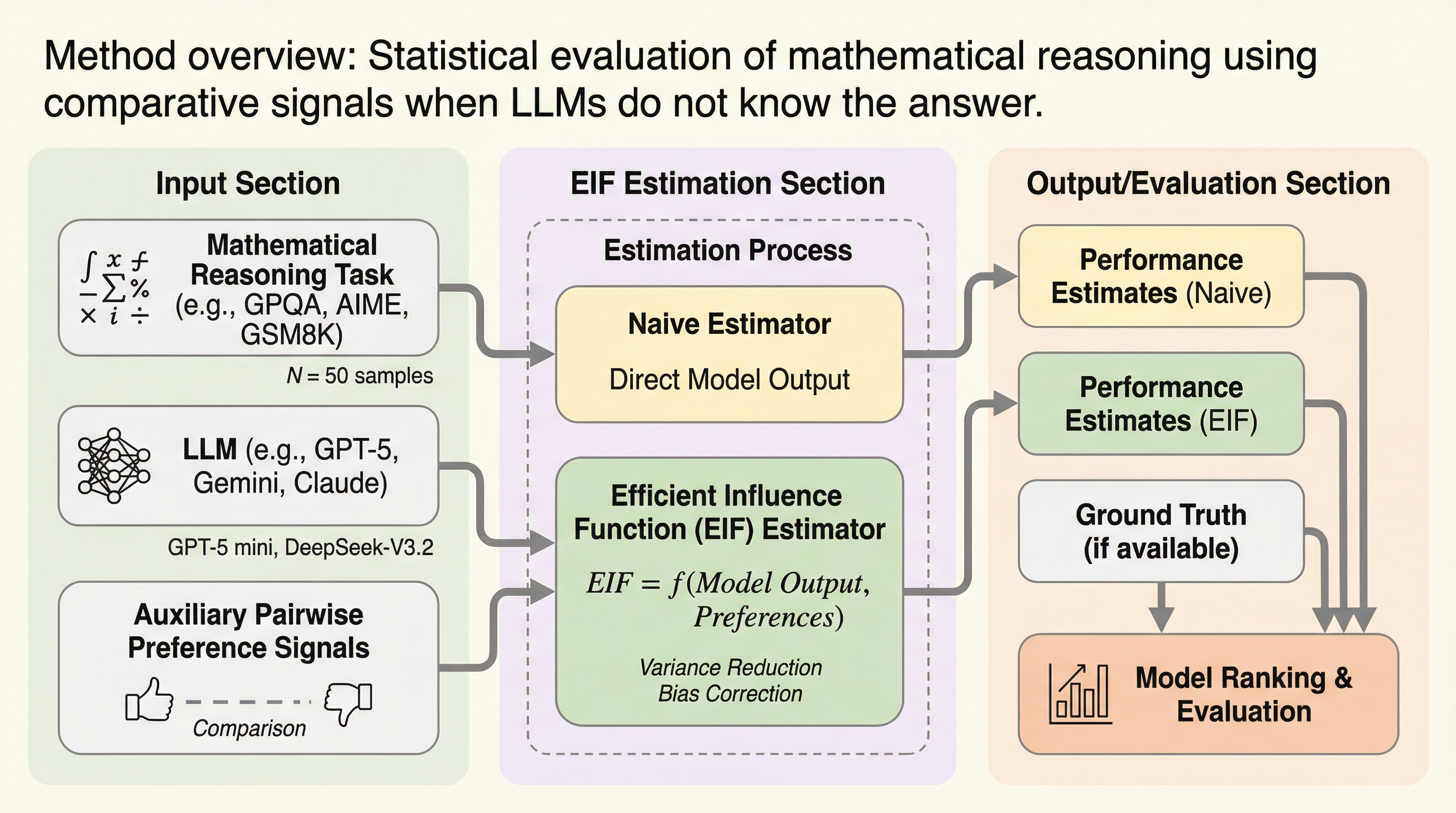
大規模言語モデル(LLM)の数学的推論能力の評価において、ベンチマークのサイズ制限とモデルの確率的な変動が原因で、評価結果の分散が大きくなりランキングが不安定になる「再現性の危機」を解決するための統計的枠組みを提案した。モデルが正解を導き出せない難問であっても、2つの解答候補のどちらが優れているかを判断する「比較信号」は信頼性が高いという「生成と検証のギャップ」を利用し、この補助的な信号を制御変数として組み込むことで、評価の分散を厳密に削減し統計的効率を最大化する手法を開発した。シミュレーションおよびGPQA Diamond、AIME 2025、GSM8Kを用いた実験により、提案手法である効率的影響関数(EIF)に基づくワンステップ推定器が、従来の単純平均よりも高い精度で性能を推定でき、特にサンプル数が少ない状況下で極めて安定したモデルランキングを実現することを実証した。これにより、限られたデータから最大限の情報を抽出する新しい評価標準を提示している。
なぜこの問題か
大規模言語モデル(LLM)の数学的推論能力を評価することは、モデルの真の認知能力を測る上で極めて重要であるが、現在の評価手法は深刻な再現性の危機に直面している。同じモデルであっても、評価プラットフォームや実施タイミングが異なれば、報告される正解率に大きな乖離が生じることが事実として確認されている。例えば、DeepSeek-R1-Distill-Llama-70Bというモデルにおいて、ある報告ではGPQA Diamondの正解率が65.2%とされているが、別の独立した評価では40.2%や55.7%と報告されており、本研究の再現実験でも59.09%という異なる数値が得られている。このような評価の不安定さは、主に2つの要因に起因している。 第一に、LLMは特に困難な数学問題において高い固有の確率性を持っており、出力の変動が非常に大きいという性質がある。同じプロンプトに対しても、サンプリングの過程で正誤が入れ替わることが頻繁に起こる。第二に、数学的推論のベンチマークは、専門家によるキュレーションが必要であるため、そのサイズが極めて限定的であるという問題がある。…
核心:何を提案したのか
本研究では、LLMの評価を統計的な推論問題として再定義し、補助的な「比較信号」を活用することで評価の精度を劇的に向上させる半パラメトリック評価枠組みを提案した。この提案の核心にあるのは、モデルが自ら正解を生成することはできなくても、提示された2つの解答のうちどちらがより優れているかを判断する能力(検証能力)は、生成能力よりも安定して高いという「生成と検証のギャップ」に関する経験的な観察である。この観察に基づき、ターゲットとなるモデルに補助的な推論チェーンを評価させ、その比較結果を「制御変数」として統計モデルに組み込む手法を開発した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related