ベクトル値分布強化学習の方策評価:ヒルベルト空間埋め込みによるアプローチ
本研究は、多次元の報酬指標と連続的な状態行動空間を扱うオフライン強化学習において、将来的なリターン分布を精度高く推定する新フレームワーク「KE-DRL」を提案している。 従来の分布型強化学習で主流だったワッサースタイン距離は、高次元空間での計算コスト増大と統計的不安定性が課題であったが、再生核ヒルベルト空間への埋め込みとマテルン核を用いた積分確率指標を導入することで、この問題を理論的かつ計算的に解決した。 数学的な解析により分布型ベルマン作用素の縮小性と一様収束性を証明するとともに、エクスペディアのホテル検索データを用いた実証実験を通じて、テールリスクの評価や複数報酬間の複雑なトレードオフを考慮した意思決定における実用的な有効性を明らかにした。
TL;DR(結論)
本研究は、多次元の報酬指標と連続的な状態行動空間を扱うオフライン強化学習において、将来的なリターン分布を精度高く推定する新フレームワーク「KE-DRL」を提案している。 従来の分布型強化学習で主流だったワッサースタイン距離は、高次元空間での計算コスト増大と統計的不安定性が課題であったが、再生核ヒルベルト空間への埋め込みとマテルン核を用いた積分確率指標を導入することで、この問題を理論的かつ計算的に解決した。 数学的な解析により分布型ベルマン作用素の縮小性と一様収束性を証明するとともに、エクスペディアのホテル検索データを用いた実証実験を通じて、テールリスクの評価や複数報酬間の複雑なトレードオフを考慮した意思決定における実用的な有効性を明らかにした。
なぜこの問題か
現代のデジタルプラットフォームや医療現場における意思決定では、単一の指標を最適化するだけでは不十分なケースが極めて多い。例えば、旅行予約サイトや小売プラットフォームにおいて、企業は価格設定やプロモーションの戦略を立てる際、目先の売上だけでなく、長期的な顧客維持率やエンゲージメントといった複数のビジネス指標を同時に考慮する必要がある。同様に、医療における多剤併用療法の選択では、治療効果の最大化と副作用の抑制、さらには治療費用の抑制という、互いにトレードオフの関係になり得る複数の目的をバランスよく達成することが求められる。しかし、従来の強化学習アプローチの多くは、これらの多次元的な報酬を単一のスカラー値に統合して扱うため、リターンの相関関係や極端な事象が発生するテールリスクを十分に捉えることができないという根本的な限界があった。 また、実社会の多くの応用場面では、新しい方策をオンラインで直接試行錯誤することは、倫理的なリスクや多大な運用コストを伴うため困難である。そのため、過去の運用ログデータのみを活用して新しい方策の性能を評価する「オフライン強化学習」の重要性が急速に高まっている。…
核心:何を提案したのか
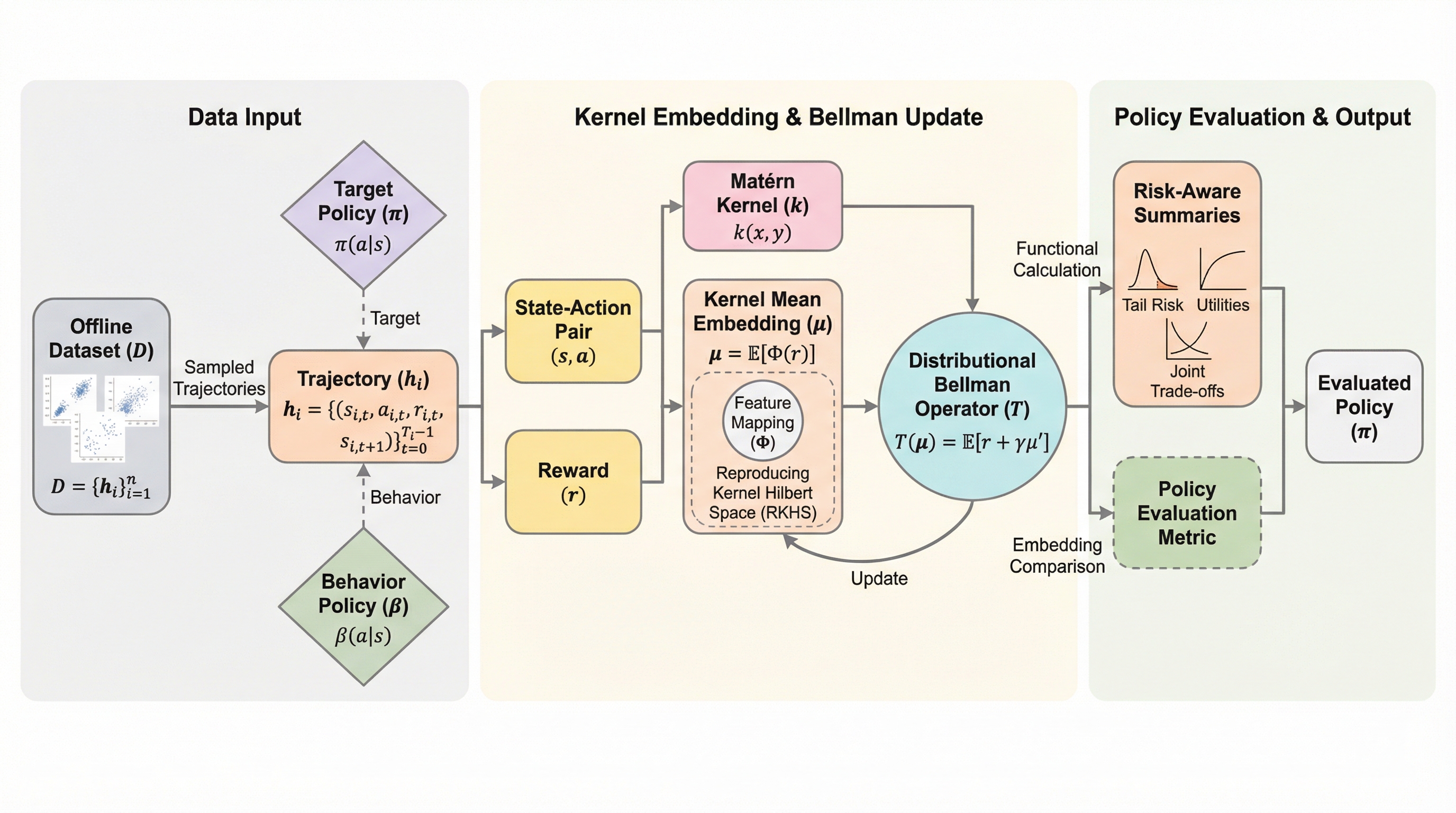
本論文は、カーネル埋め込みを用いた多次元分布型強化学習フレームワークである「KE-DRL(Kernel Embedding Distributional Reinforcement Learning)」を提案している。この手法の核心は、確率測度を再生核ヒルベルト空間(RKHS)に写像し、カーネル平均埋め込みを利用して多次元のリターン分布を推定する点にある。これにより、計算が困難なワッサースタイン距離を、より扱いやすく計算効率の高い積分確率指標(IPM)に置き換えることに成功した。特に、カーネルの選択としてマテルン(Matérn)核を採用している点が重要であり、これによりワッサースタイン幾何学との理論的な橋渡しが可能となっている。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related