平均報酬Q学習における新しい収縮原理を用いた$\varepsilon^{-2}$依存性の達成
平均報酬マルコフ決定過程におけるQ学習は、割引報酬設定とは異なりベルマン作用素が収縮性を持たないため、理論的な解析が極めて困難であり、従来のモデルフリー手法では精度誤差に対して最適な収束レートを達成できていませんでした。
TL;DR(結論)
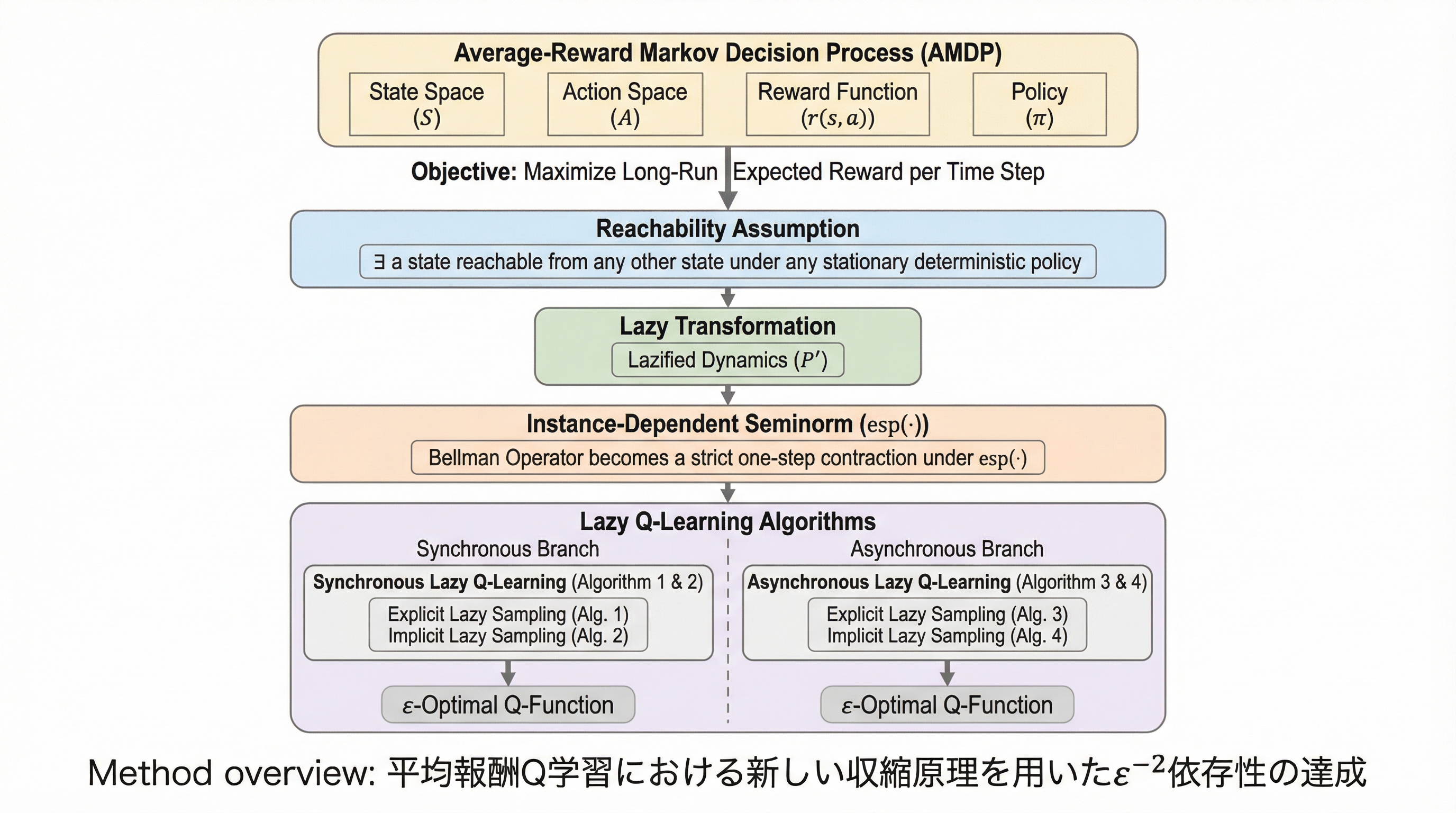
平均報酬マルコフ決定過程におけるQ学習は、割引報酬設定とは異なりベルマン作用素が収縮性を持たないため、理論的な解析が極めて困難であり、従来のモデルフリー手法では精度誤差に対して最適な収束レートを達成できていませんでした。 本研究では、特定の参照状態への到達可能性という自然な仮定の下で、システムが一定確率で現在の状態に留まる「レイジー変換」と、多段階のダイナミクスを捉える新しい「インスタンス依存型セミノルム」を導入することで、ベルマン作用素が1ステップで厳密に収縮することを数学的に証明しました。 この新しい収縮原理を用いることにより、同期型および非同期型の両方の設定において、精度誤差のマイナス2乗という理論的に最適なサンプル複雑性を、シンプルで実装が容易なモデルフリーのQ学習アルゴリズムとして初めて達成することに成功しました。
なぜこの問題か
強化学習は、アタリのゲームでの超人的なパフォーマンスや囲碁の習熟、ロボット工学など、多様な意思決定タスクにおいて顕著な成功を収めてきましたが、その理論的基盤の多くは報酬を割り引く「割引報酬設定」に集中していました。しかし、現実世界の多くの継続的なタスクや長期的な行動のモデル化においては、将来の報酬を減衰させない「平均報酬設定」の方が、長期的な期待利得を最大化する観点からより適切である場合があります。平均報酬設定における最大の技術的障壁は、割引因子が存在しないために、標準的なノルムの下でベルマン作用素が収縮特性を持たないことであり、これが収束率の解析を著しく困難にしてきました。 既存の研究では、この非収縮性の問題を解決するために、検証が困難な強い収縮性の仮定を明示的に置いたり、割引報酬やエピソード型の設定で近似したりする手法が取られてきましたが、その結果として得られるサンプル複雑性は精度パラメータのマイナス9乗やマイナス6乗といった、最適とは言い難い値に留まっていました。…
核心:何を提案したのか
本研究の核心的な提案は、平均報酬Q学習に「レイジー変換(Lazy Transformation)」と「新しいインスタンス依存型セミノルム(Instance-Dependent Seminorm)」を組み合わせた「レイジーQ学習(Lazy Q-learning)」を導入したことです。レイジー変換とは、各ステップにおいて一定の確率(本研究では主に2分の1)で現在の状態に留まり、残りの確率で元の遷移規則に従うという単純な修正です。この変換は、元の問題の最適な政策やQ関数の構造を維持しつつ、周期的なマルコフ連鎖を非周期的なものに変える性質を持っており、ベルマン方程式の解を保存したまま解析を容易にします。 また、本研究では「到達可能性(Reachability)」という仮定を採用しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related