共形予測における被覆率と区間長指標への疑問:短い区間が必ずしも優れているとは限らない理由
共形予測(CP)の評価で主流の「被覆率」と「区間長」という指標は、特定の確率で空集合を返す「Prejudicial Trick(PT)」という手法によって、統計的な妥当性を維持したまま数値だけを欺瞞的に向上させることが可能です。
TL;DR(結論)
共形予測(CP)の評価で主流の「被覆率」と「区間長」という指標は、特定の確率で空集合を返す「Prejudicial Trick(PT)」という手法によって、統計的な妥当性を維持したまま数値だけを欺瞞的に向上させることが可能です。 この手法は、周辺被覆率や条件付き被覆率を数学的に保証しながらも、同じ入力に対して実行のたびに異なる予測結果を出す「不安定性」や、一部のデータに対して情報を与えない「不公平性」という実用上の重大な欠陥を抱えています。 本論文は、標準指標の脆弱性を指摘するとともに、アルゴリズムが不当なランダム性を用いて数値を操作していないかを検知するための新指標として「区間安定性(Interval Stability)」を導入し、より健全な評価体系の構築を提唱しています。
なぜこの問題か
機械学習モデルは様々な分野で目覚ましい成果を上げていますが、予測結果に対して過剰な自信を持つ傾向があり、その信頼性が課題となっています。特に医療診断や金融予測といった、予測の誤りが重大な損失につながる高リスクな領域では、モデルがどの程度の不確実性を持っているかを正確に把握することが不可欠です。この課題を解決するために、予測の不確実性を定量化し、モデルの出力を適切に較正する技術が求められてきました。その中でも共形予測(CP)は、基礎となるモデルの分布に依存せず、有限のサンプルサイズで統計的な保証を提供できるという強力な特性から、不確実性評価の標準的な手法として広く採用されています。 従来の共形予測の研究において、アルゴリズムの性能を評価するための基準は、主に二つの指標に集約されてきました。一つは「被覆率(Coverage)」であり、これは予測された区間の中に実際の正解値が含まれる確率が、事前に設定した信頼レベル(例えば90%など)を上回っているかどうかを測定するものです。もう一つは「区間長(Interval Length)」であり、予測区間が狭ければ狭いほど、不確実性が小さく精密な予測であると評価されます。…
核心:何を提案したのか
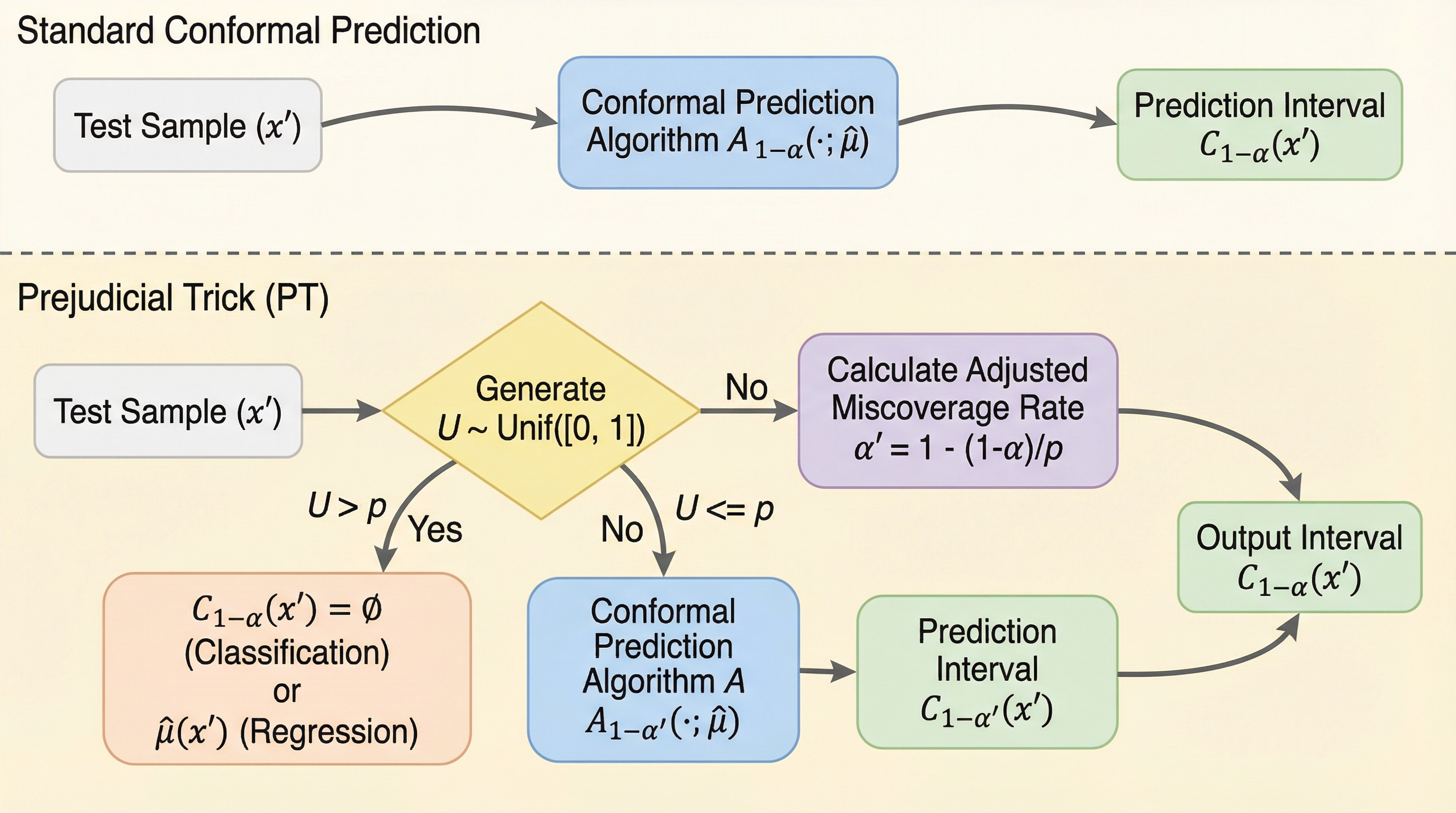
本論文の核心的な提案は、現在の共形予測の評価指標を欺くことができる「Prejudicial Trick(PT)」という手法の提示と、それに対抗するための新指標「区間安定性(Interval Stability)」の導入です。著者らは、まず「アリスとボブという二人の医師」の例え話を用いて、区間長という指標がいかに簡単に操作され得るかを説明しています。アリスは常に一定の信頼できる期間を提示しますが、ボブは特定の確率で「即座に回復する」という非現実的な予測(空の区間)を出し、それ以外の時には通常より少し広い区間を提示します。驚くべきことに、統計的な平均をとると、ボブの予測はアリスと同じ被覆率を維持しながら、平均的な区間長をアリスよりも短くすることができるのです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related