統計的保証付きLLM性能評価の効率化:FAQ手法の提案
大規模言語モデル(LLM)の膨大な評価コストを削減するため、過去の評価データを活用して最適な質問を適応的に選択する新手法「FAQ(Factorized Active Querying)」が提案されました。
TL;DR(結論)
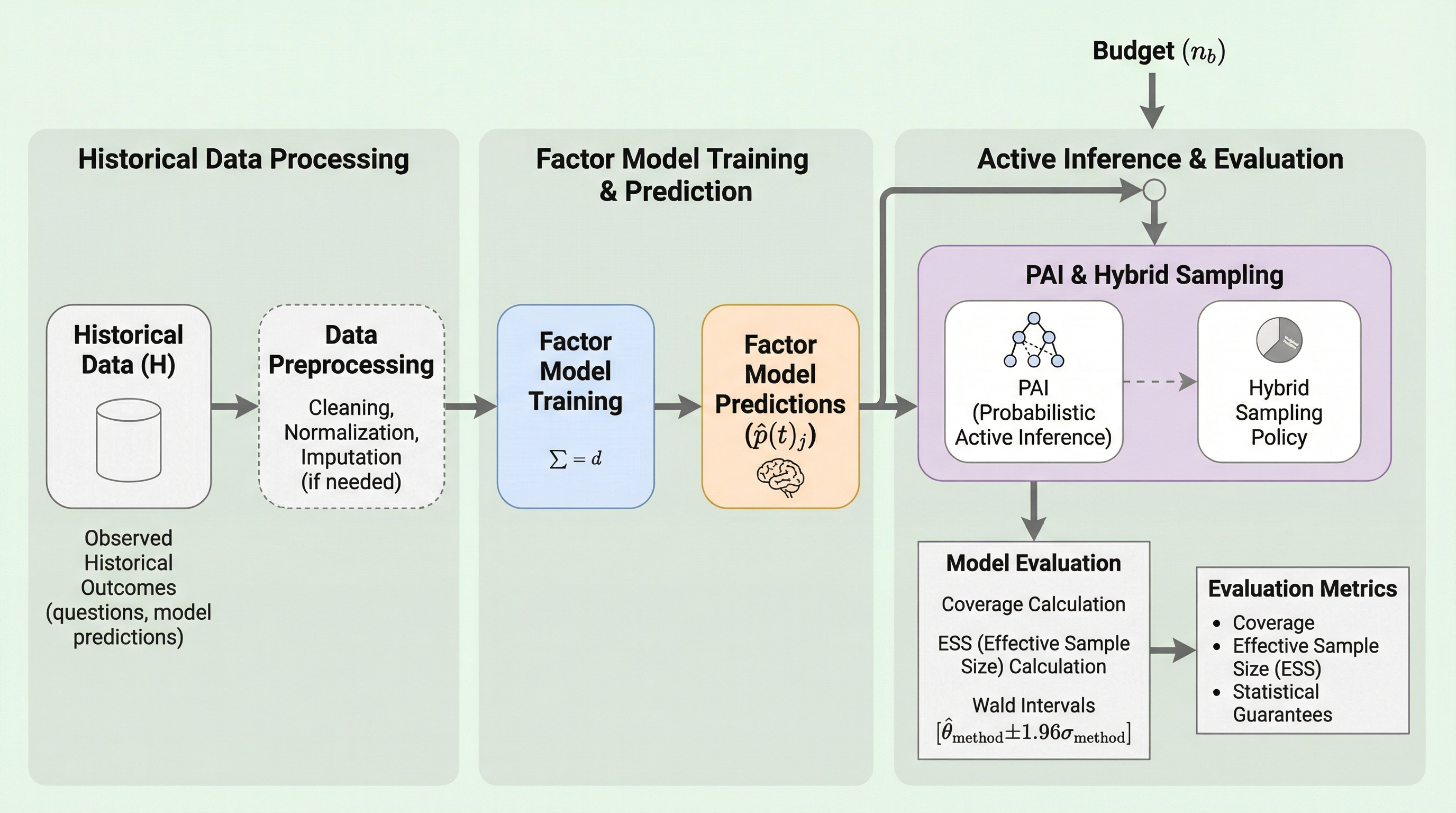
大規模言語モデル(LLM)の膨大な評価コストを削減するため、過去の評価データを活用して最適な質問を適応的に選択する新手法「FAQ(Factorized Active Querying)」が提案されました。 この手法は、ベイズ因子モデルによる性能予測と、統計的な厳密さを担保する新枠組み「PAI(Proactive Active Inference)」を組み合わせることで、信頼区間の妥当性を維持したまま評価に必要なクエリ数を最大5分の1に削減します。 4,400以上のモデルと2万問以上の質問を含む大規模データセットでの検証により、計算負荷を極めて低く抑えつつ、一様サンプリングと比較して高い推定精度と統計的な信頼性を両立できることが実証されました。
なぜこの問題か
現在、大規模言語モデル(LLM)は単なる研究段階を超え、医療、法律、教育といった高度な専門性が求められるドメインでの実用化が急速に進んでいます。これに伴い、組織が評価・監視すべき候補モデルの数は爆発的に増加しており、例えばHuggingFaceには186万以上のモデルがホストされ、そのうち30万以上がテキスト生成タスクに分類されています。これらの多くは特定のベースモデルを微調整したバリエーションであり、それぞれがクエリの内容に応じた独自の強みと弱みを持っています。しかし、これらのモデルを網羅的に評価することは、リソースの観点から極めて困難な課題となっています。 最新のベンチマークセットは、専門家による高コストな判定が必要な問題や、多段階の対話を含むタスク、あるいは検証を伴う長文の推論を要求するタスクへとシフトしています。例えば「MMLU-Pro」のようなベンチマークには1万2千もの質問が含まれており、数百から数千のモデル候補をすべて評価するには、APIコスト、実行時間、専門家のアノテーション費用の面で膨大なリソースが必要となります。…
核心:何を提案したのか
本論文では、統計的保証を維持しながらLLM評価を効率化する革新的な手法として「FAQ(Factorized Active Querying)」を提案しています。FAQは、限られたクエリ予算の中で、モデルの正解率に対する信頼区間を可能な限り狭めることを目的としています。この手法の最大の特徴は、以下の3つの主要コンポーネントを統合した点にあります。 第一に、不完全な歴史的データから情報を抽出する「ベイズ因子モデル」です。過去に評価されたモデルと質問の正誤結果行列から、モデルの潜在的な能力と質問の特性を低次元の因子として学習します。これにより、新しいモデルが数問の質問に答えただけで、未回答の質問に対する正誤を確率的に予測することが可能になります。第二に、分散減少と能動学習を組み合わせた「ハイブリッドサンプリングポリシー」です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related