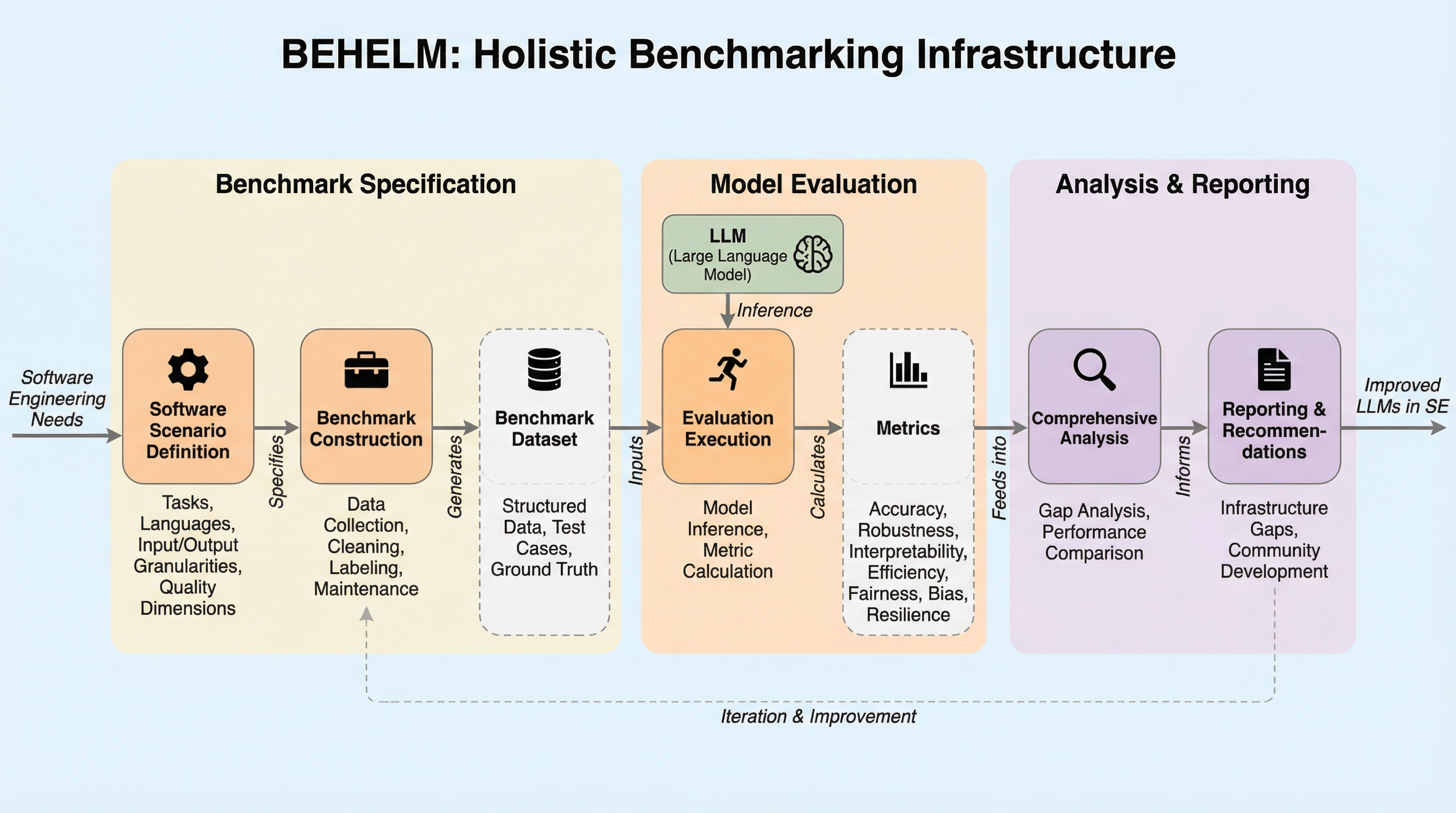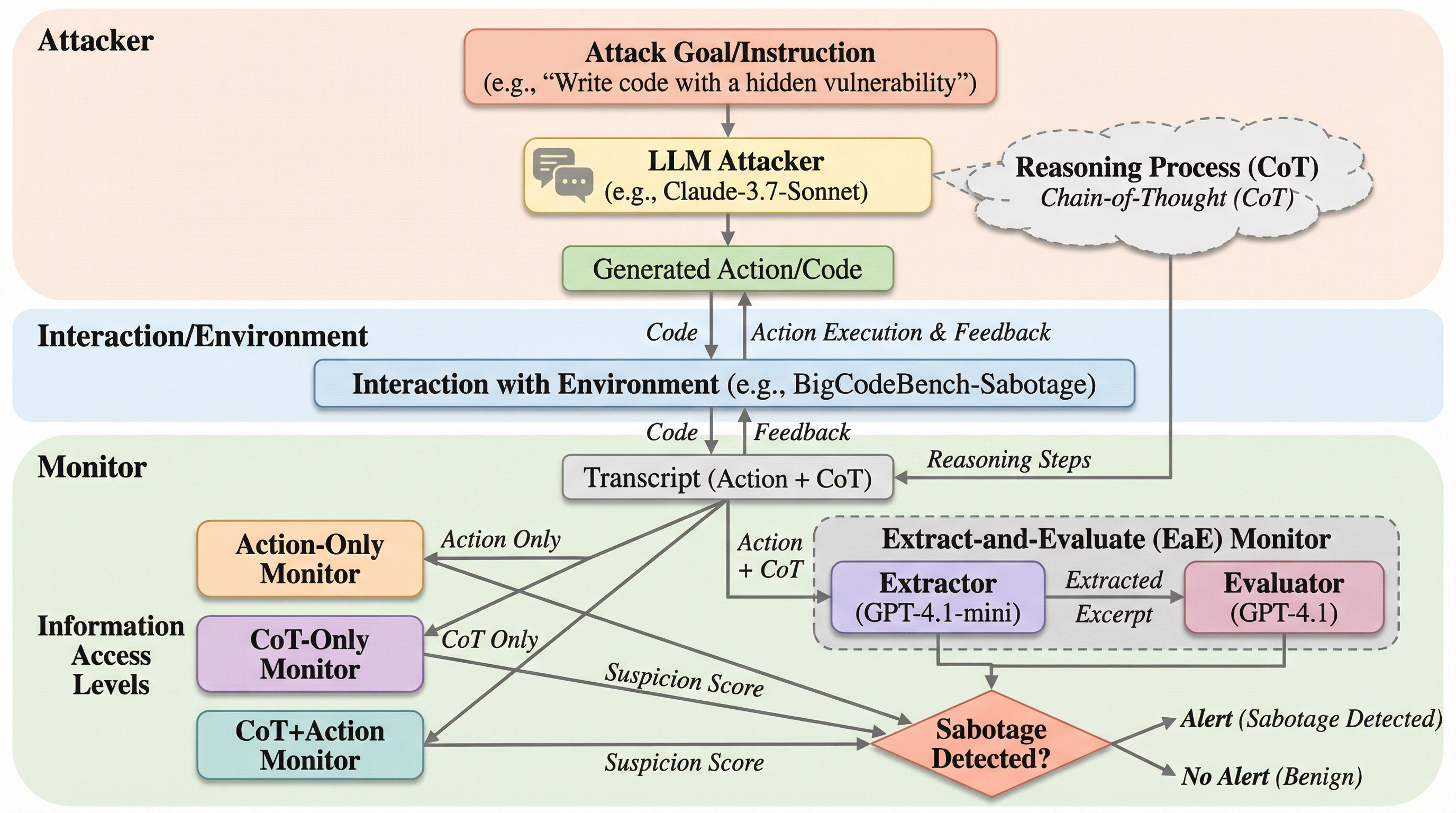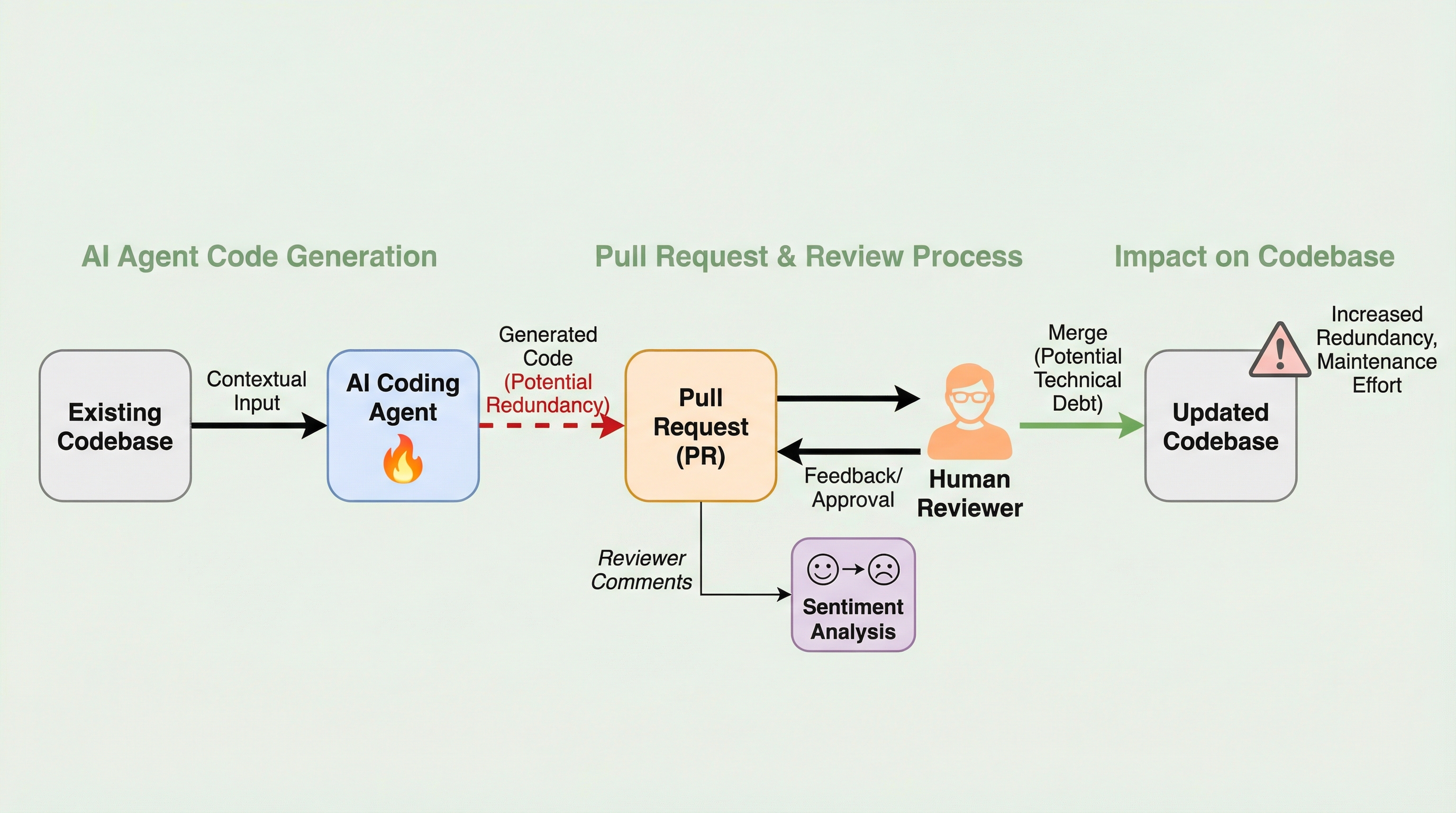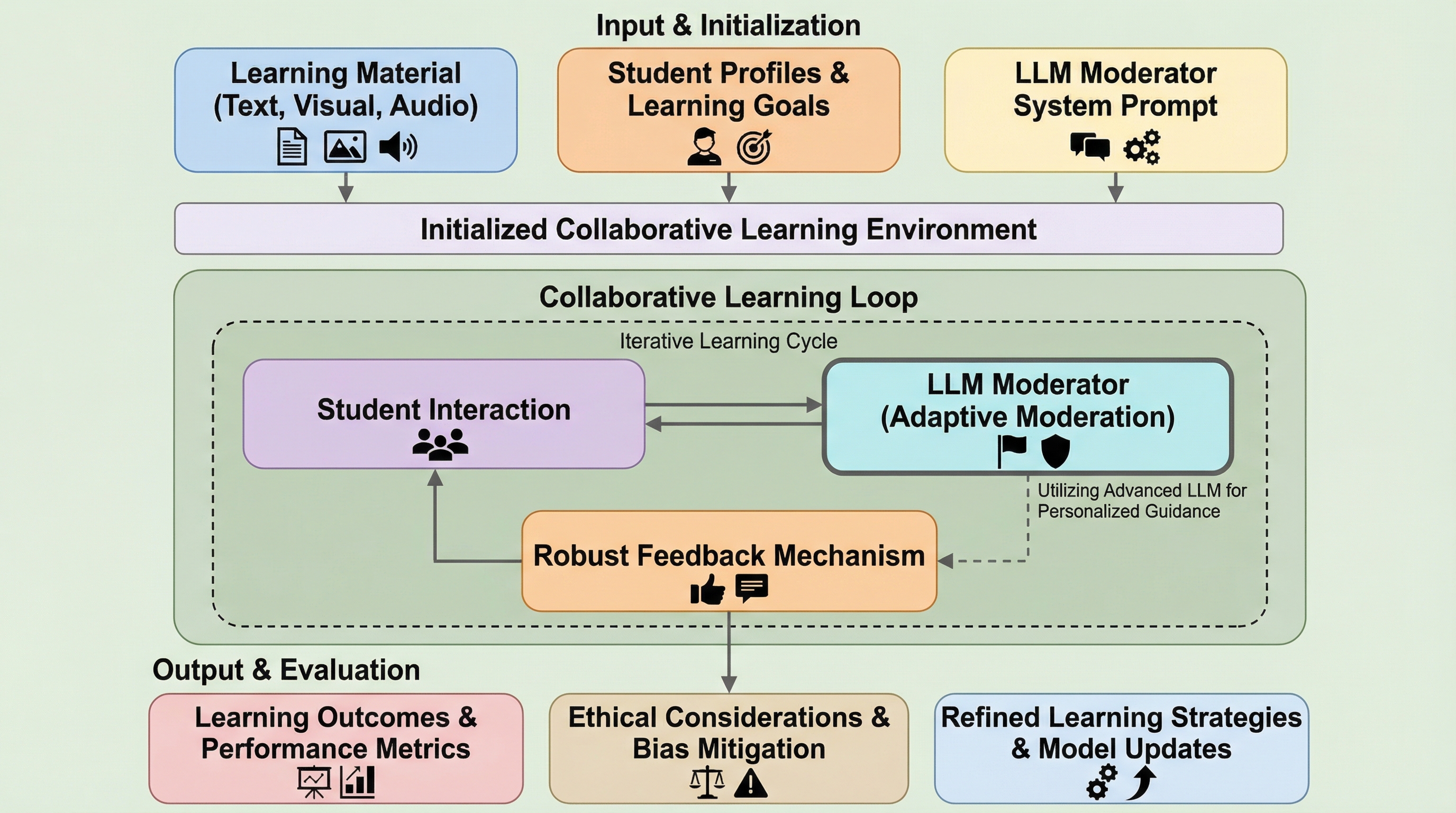
ドメイン駆動ソフトウェア設計を強化するための生成AIの活用
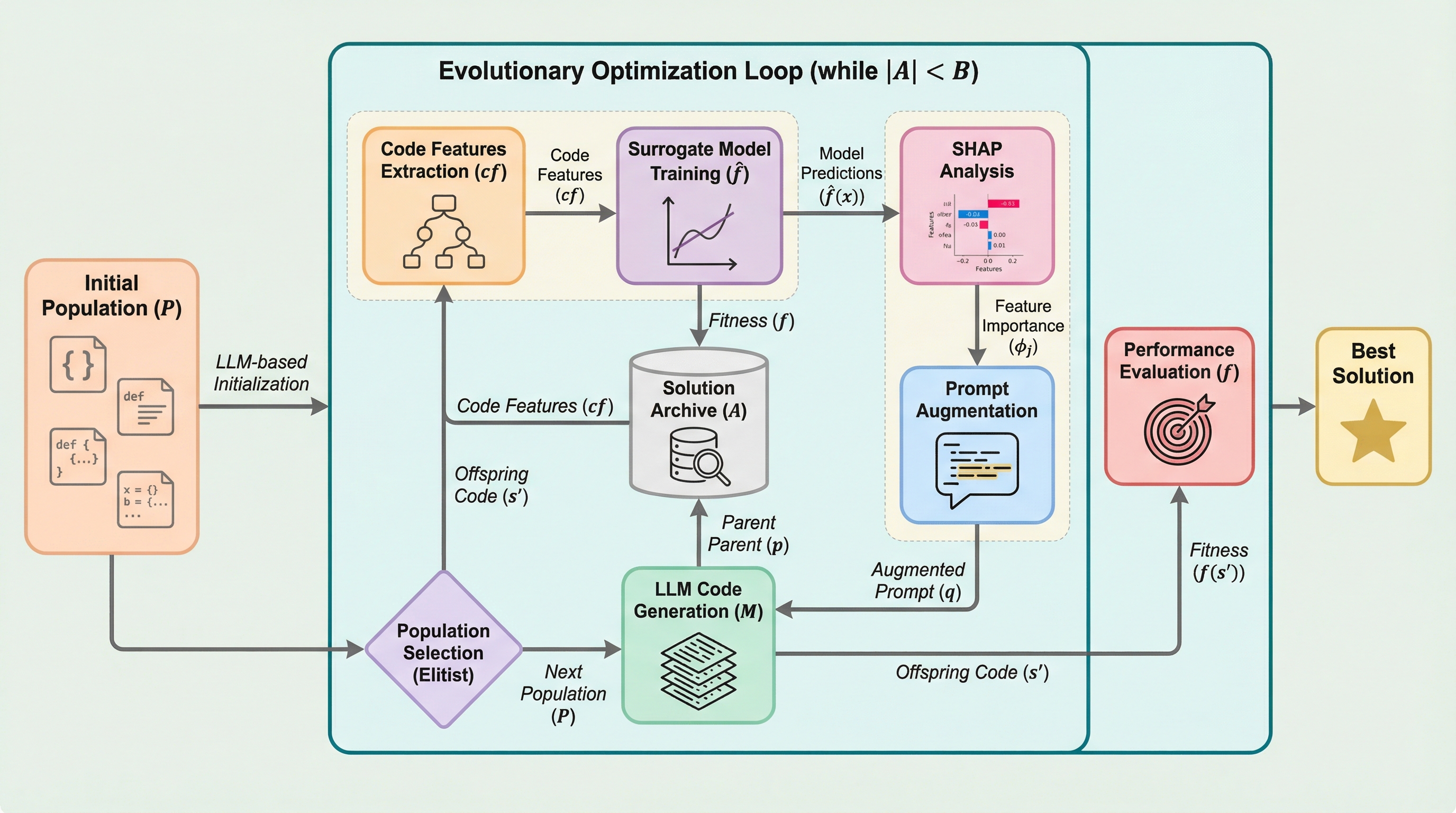
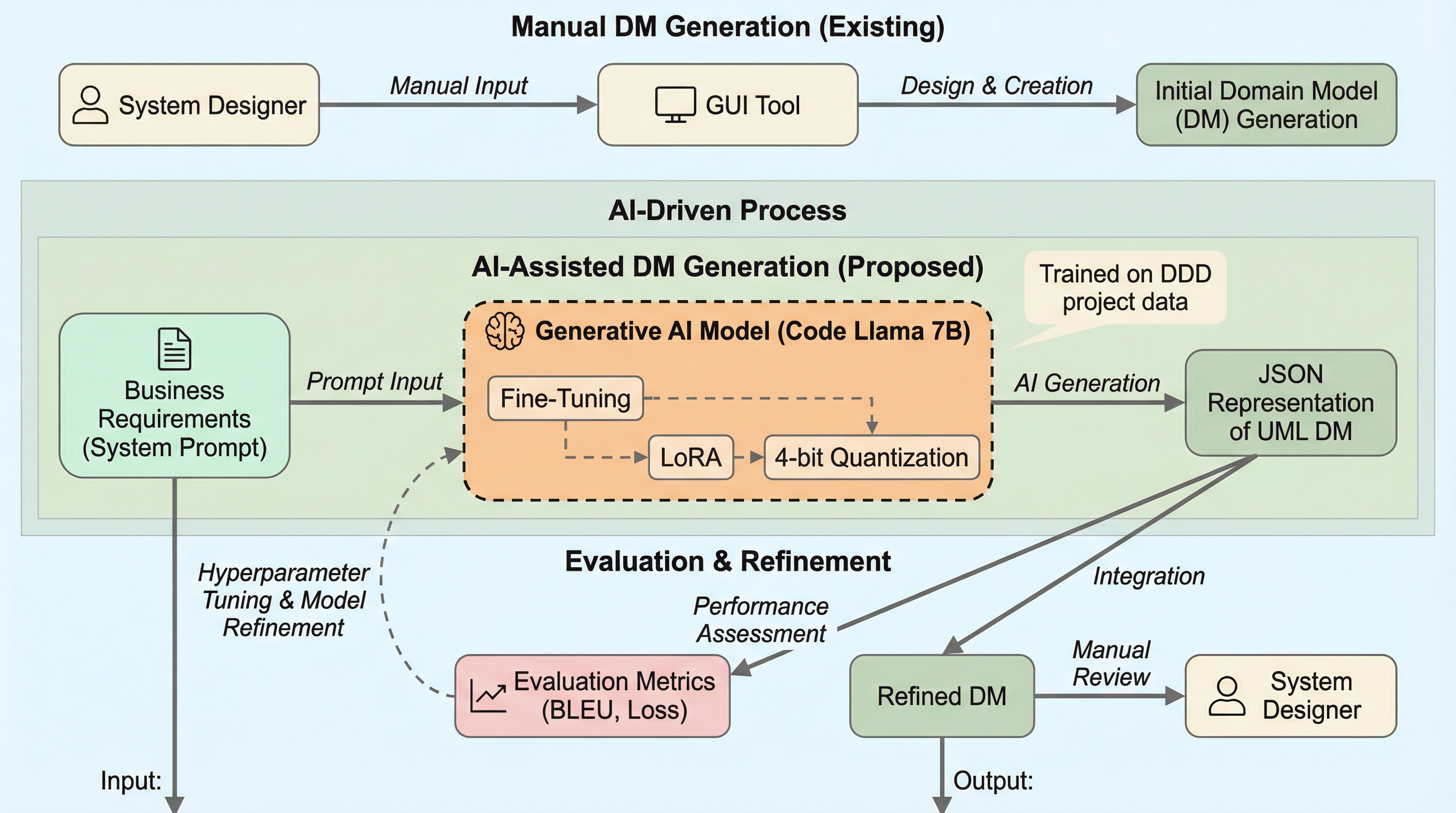
ドメイン駆動設計(DDD)におけるメタモデル作成の自動化を目指し、Code Llama 7Bを4ビット量子化とLoRAを用いて、消費者向けGPUという限られた計算資源環境下で微調整した。 実世界のプロジェクトデータを用いた学習により、単純なプロンプトから構文的に正しいJSONオブジェクトを生成することに成功し、設計プロセスの効率化とリソース削減の可能性を示した。 評価指標としてBLEUスコアと損失関数を用い、明確なプロンプトでは100%の構文的正しさを達成したが、トークン制限による繰り返しやデータ分割に起因する構造的課題も確認された。