効率的かつ最適化されたコード生成のためのマルチエージェント協調における適応型信頼ゲート
DebateCoderは、Pangu-1Bのような小規模言語モデル(SLM)が複雑なプログラミングタスクで直面する「推論のボトルネック」や、自身の誤りを修正できずに停滞する「失敗ループ」を打破するために開発された、革新的なマルチエージェント協調フレームワークである。
TL;DR(結論)
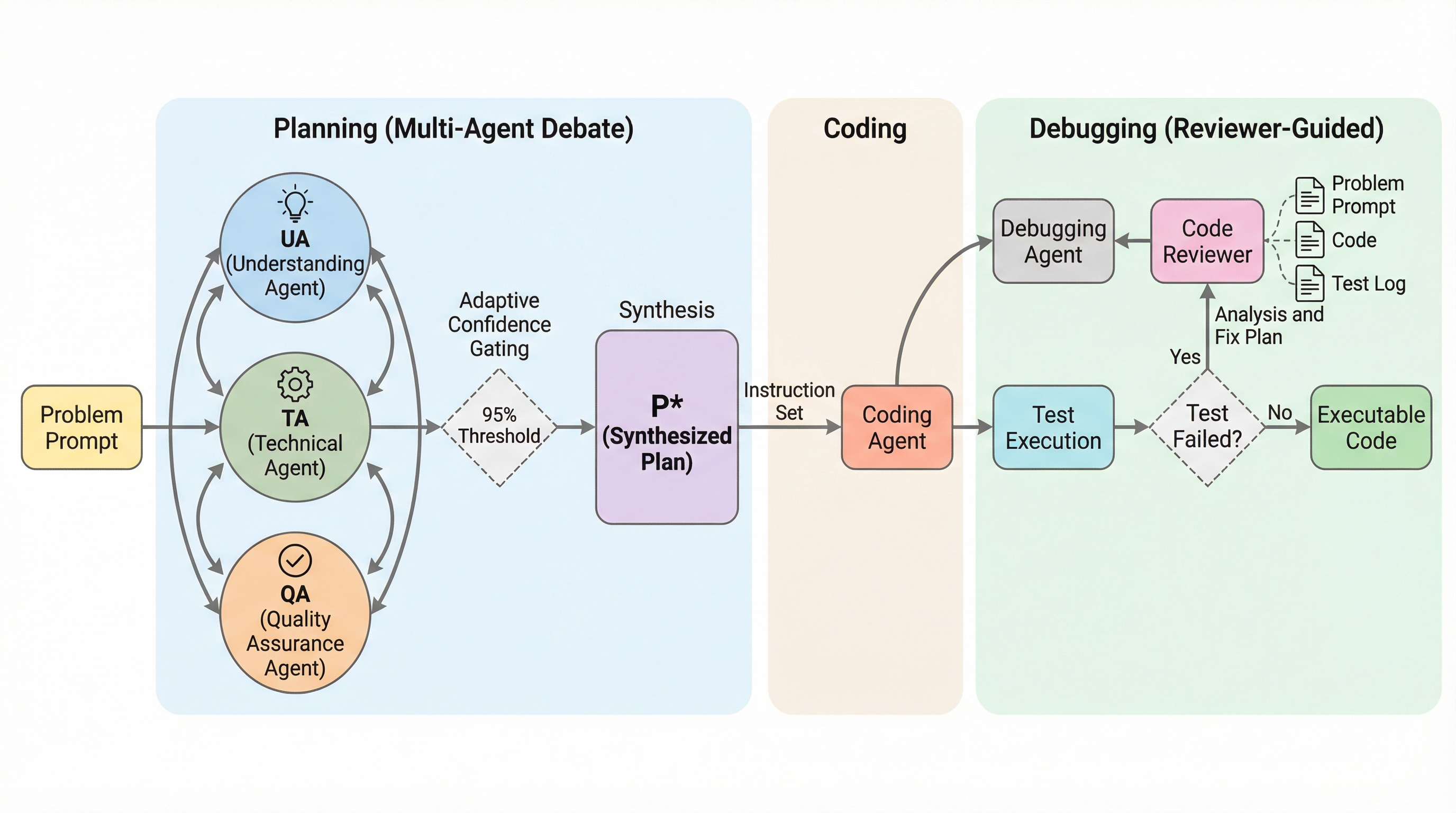
DebateCoderは、Pangu-1Bのような小規模言語モデル(SLM)が複雑なプログラミングタスクで直面する「推論のボトルネック」や、自身の誤りを修正できずに停滞する「失敗ループ」を打破するために開発された、革新的なマルチエージェント協調フレームワークである。 専門化された3つのエージェント(ユーザー、技術、品質保証)による多角的な議論プロセスと、集合的信頼度が95%を超えた場合に処理を簡略化する「適応型信頼ゲート」を導入することで、生成精度の向上とAPI呼び出し回数の約35%削減を同時に達成した。 HumanEvalベンチマークにおいて70.12%という高いPass@1精度を記録し、既存のMapCoderを大きく上回る性能を示したことで、計算リソースが限られた環境においても、適切な協調プロトコルを用いれば大規模モデルに匹敵する高品質なコード生成が可能であることを実証した。
なぜこの問題か
近年の自動コード生成分野は、GPT-4やClaude 3.5といった数千億のパラメータを持つ大規模言語モデル(LLM)によって劇的な進歩を遂げているが、これらの巨大なモデルは膨大な計算リソースと高い推論コストを必要とする。実用的なソフトウェア開発の現場では、より軽量でコスト効率の高い小規模言語モデル(SLM)の活用が期待されているものの、SLMをコード生成に利用しようとすると、主に2つの深刻な課題に直面することになる。第一の課題は「推論のボトルネック」である。SLMは多段階の対話や複雑な論理要件を処理する際に、文脈の一貫性を維持することが難しく、論理的な破綻を招きやすいという性質がある。第二の課題は「失敗ループ」と呼ばれる現象である。これは、SLMがツール呼び出しや自己デバッグの過程で自らの論理的誤りを正確に特定できず、同じ間違いを繰り返したり、修正によって新たなエラーを導入したりする傾向を指す。 既存のマルチエージェントフレームワークの多くは、巨大なモデルの強力な推論能力を前提として設計されており、SLMのようなリソース制約のあるモデルで効率的かつ正確な協調を実現する手法は十分に確立されていない。…
核心:何を提案したのか
本研究では、小規模パラメータモデルの推論能力を最適化するために設計された、効率的なマルチエージェント協調フレームワーク「DebateCoder」を提案している。このフレームワークの核心は、専門化された3つのエージェントによる構造化されたロールプレイングと、競争的な議論プロトコルを組み合わせた点にある。導入されたエージェントは、機能の完全性と使いやすさを重視するユーザーエージェント(AUA)、技術的実現可能性と性能効率を優先する技術エージェント(ATA)、そして堅牢性と信頼性を担保する品質保証エージェント(AQA)の3種類である。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related