協調学習のための動的フレームワーク:適応型フィードバック機構を備えた高度なLLMの活用
本研究では、高度な大規模言語モデルであるGPT-4oを動的なモデレーターとして統合し、リアルタイムでの議論促進と学習者のニーズへの適応を可能にする新しい協調学習フレームワークを提案しました。検索拡張生成(RAG)技術と多層的なフィードバック機構を組み合わせることで、従来の静的なシステムでは困難だった参加者間の公平な関与の促進や、文脈に応じた柔軟なプロンプト調整を実現しています。FairytaleQAデータセットを用いた検証により、学生のエンゲージメント向上や批判的思考の育成、さらには多様な学習環境におけるスケーラビリティと包括的な教育体験の提供が確認されました。
TL;DR(結論)
本研究では、高度な大規模言語モデルであるGPT-4oを動的なモデレーターとして統合し、リアルタイムでの議論促進と学習者のニーズへの適応を可能にする新しい協調学習フレームワークを提案しました。検索拡張生成(RAG)技術と多層的なフィードバック機構を組み合わせることで、従来の静的なシステムでは困難だった参加者間の公平な関与の促進や、文脈に応じた柔軟なプロンプト調整を実現しています。FairytaleQAデータセットを用いた検証により、学生のエンゲージメント向上や批判的思考の育成、さらには多様な学習環境におけるスケーラビリティと包括的な教育体験の提供が確認されました。
なぜこの問題か
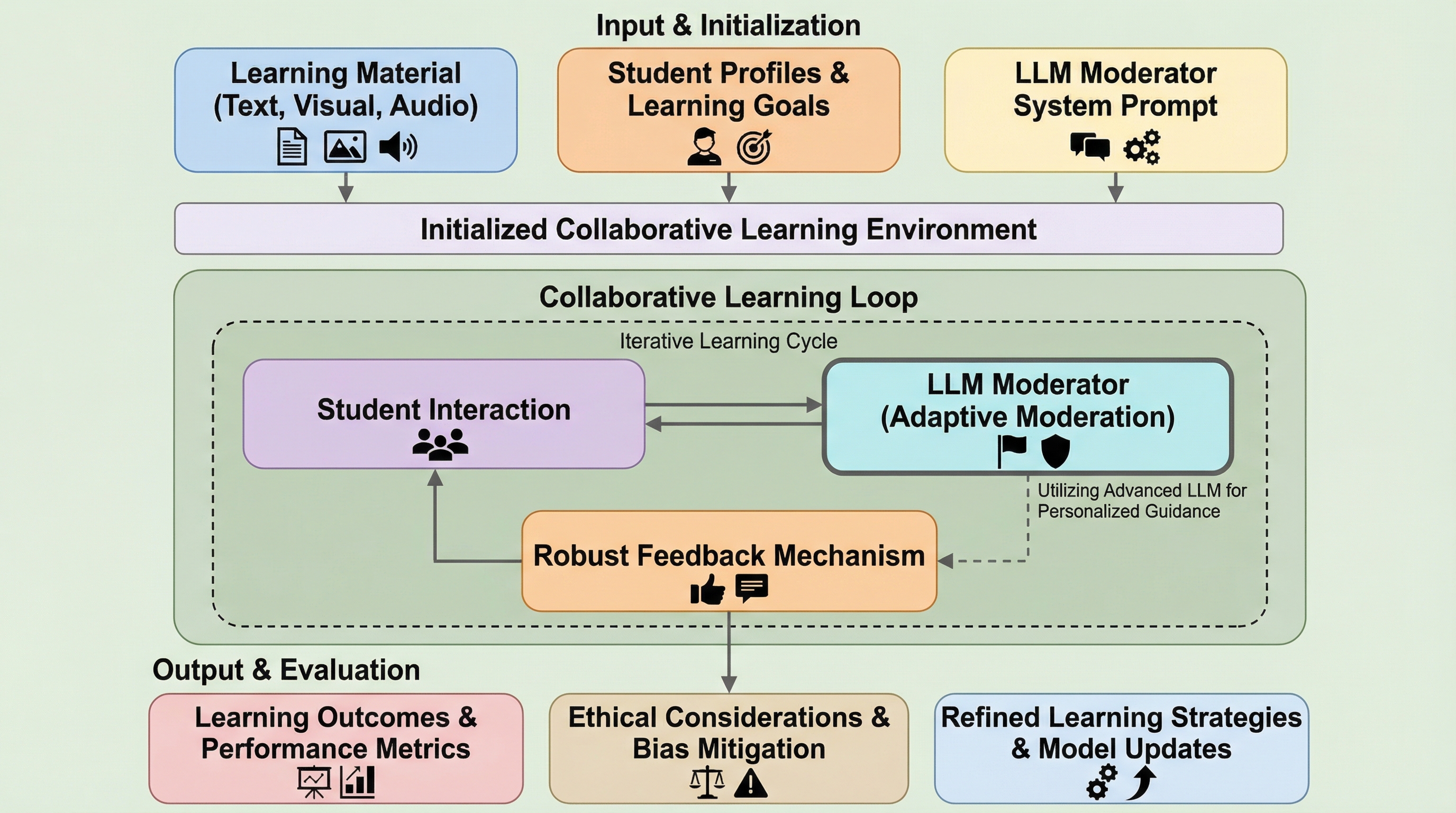
教育分野における大規模言語モデル(LLM)の統合は、学生がコンテンツに関与し、学習環境で協力する方法に革新的な変化をもたらしています。LLMは高度な自然言語処理能力を備えており、パーソナライズされた学習体験の提供や、対話形式の議論の促進、グループ内での共同作業のモデレーションにおいて重要な役割を果たします。特に、批判的思考の育成やエンゲージメントの向上、そして個別およびグループ学習の両方における包括性の確保において、その影響力は非常に大きいと考えられています。しかし、既存の教育支援システムには依然として多くの課題が残されており、それらがLLMの真の可能性を制限しているのが現状です。 従来のPeerGPTやグループ学習用の会話型AIモデルなどの実装では、フィードバック機構の欠如やパーソナライズの不十分さ、さらには多様な学習シナリオに対するスケーラビリティの不足が指摘されています。また、GPT-3.5ベースのシステムを含む多くの既存モデルは、推論能力やリアルタイムの適応性に限界があり、最先端の教育ソリューションとしては不十分な側面があります。…
核心:何を提案したのか
本研究では、最先端のLLMであるGPT-4oを活用し、適応型フィードバック機構を備えた協調学習のための動的フレームワークを提案しています。このフレームワークの核心は、AIを単なるコンテンツ生成ツールとしてではなく、グループの動態をリアルタイムで分析し、議論を導く「動的なモデレーター」として位置づけている点にあります。具体的には、検索拡張生成(RAG)技術を統合することで、特定のデータセットに基づいた正確かつ文脈に即した情報の提供を可能にしています。これにより、既存のシステムが抱えていた推論能力の不足やリアルタイム適応の難しさを解消しています。 提案されたフレームワークの大きな特徴の一つは、多層的なフィードバックアーキテクチャを採用していることです。この仕組みにより、参加者の反応やエンゲージメントの指標、タスクの成果を利用して、AIのモデレーション能力を反復的に洗練させることができます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related