マルチエージェント連携と適応型信頼ゲートによる効率的かつ最適化されたコード生成
大規模言語モデルが自動コード生成で成果を上げる一方、Pangu-1Bのような小規模言語モデル(SLM)は複雑な論理推論において文脈維持が困難な「推論のボトルネック」や、同じ誤りを繰り返す「失敗ループ」という課題を抱えています。
TL;DR(結論)
大規模言語モデルが自動コード生成で成果を上げる一方、Pangu-1Bのような小規模言語モデル(SLM)は複雑な論理推論において文脈維持が困難な「推論のボトルネック」や、同じ誤りを繰り返す「失敗ループ」という課題を抱えています。 本研究が提案する「DebateCoder」は、ユーザー、技術、品質保証の3つの専門的役割を持つエージェントを対話・討論させることで、小規模モデルの潜在能力を最大限に引き出し、HumanEvalベンチマークにおいて70.12%という高いPass@1精度を達成しました。 さらに、95%の閾値を用いた「適応型信頼ゲート」を導入することで、簡単な課題では討論をスキップしてリソースを節約し、既存手法と比較して精度を向上させながらAPI呼び出し回数を約35%削減するという、高い効率性と実用性を両立させています。
なぜこの問題か
自動コード生成の分野では、大規模言語モデル(LLM)の登場により劇的な進歩が見られましたが、実用的なソフトウェア開発においては、膨大な計算資源の必要性や高い推論コストが大きな障壁となっています。そのため、より軽量で低コストな小規模言語モデル(SLM)の活用が強く求められていますが、小規模なモデルには特有の技術的限界が存在します。具体的には、Pangu-1Bのようなパラメータ数の少ないモデルは、複数ターンの対話において文脈の一貫性を維持することが難しく、複雑な論理的要件を処理する際に「推論のボトルネック」に直面しやすいという問題があります。 また、小規模モデルは自己修正能力が限定的であり、ツール呼び出しやデバッグの段階において、自身の論理的誤りを正確に特定して修正することができず、同じ間違いを何度も繰り返してしまう「失敗ループ(Failure Loop)」に陥りやすいことが先行研究で指摘されています。既存の高性能なマルチエージェント・フレームワークであるChatDevやMetaGPT、MapCoderなどは、その多くがGPT-4やClaude 3.…
核心:何を提案したのか
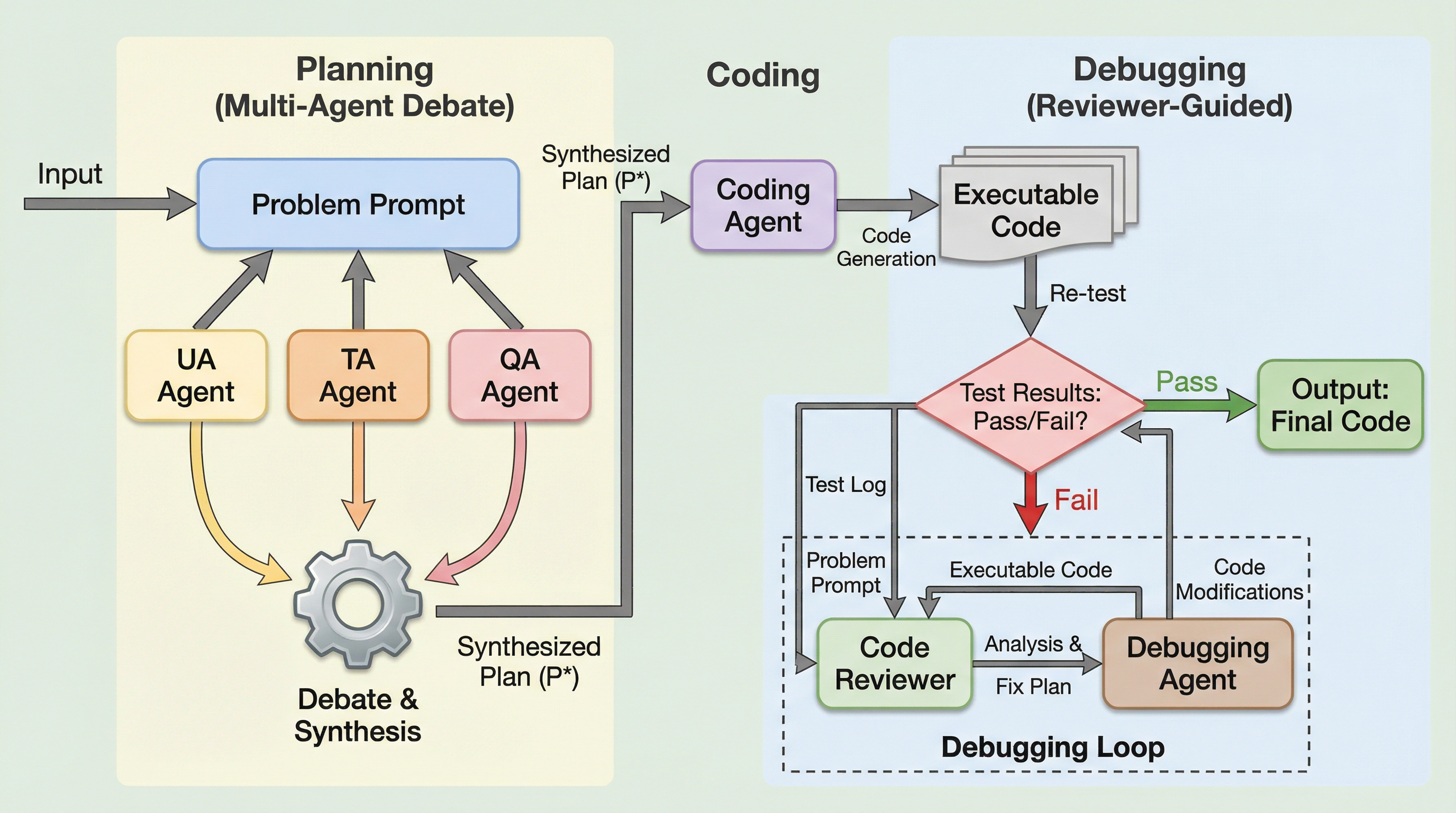
本研究では、小規模パラメータモデル向けに特別に設計された効率的な連携フレームワーク「DebateCoder」を提案しています。このフレームワークの核心は、専門化された3つの役割を持つエージェント、すなわちUser Agent(AUA)、Technical Agent(ATA)、Quality Assurance Agent(AQA)による構造化されたロールプレイングと、対立的な討論プロトコルにあります。AUAは製品所有者として機能の完全性と使いやすさを重視し、ATAは主任設計者として技術的な実現可能性と性能効率を優先し、AQAは品質保証エンジニアとして堅牢性と信頼性を検証するという、人間のソフトウェア開発チームを模した構成をとっています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related