プログラミング知識グラフを用いたコンテキスト拡張型コード生成
大規模言語モデルによるコード生成の精度を向上させるため、ソースコードの抽象構文木(AST)とドキュメントの構造をグラフ化した「プログラミング知識グラフ(PKG)」を提案している。 この手法は、情報の粒度を関数単位やブロック単位で制御し、不要な枝を切り落とすツリープルーニングや、生成後の再ランキングを組み合わせることで、検索精度の向上とハルシネーションの抑制を両立させている。 評価実験では、HumanEvalやMBPPといったベンチマークにおいて、既存の検索手法を最大34%上回る改善を確認し、複雑なプログラミング課題における有効性が示された。
TL;DR(結論)
大規模言語モデルによるコード生成の精度を向上させるため、ソースコードの抽象構文木(AST)とドキュメントの構造をグラフ化した「プログラミング知識グラフ(PKG)」を提案している。 この手法は、情報の粒度を関数単位やブロック単位で制御し、不要な枝を切り落とすツリープルーニングや、生成後の再ランキングを組み合わせることで、検索精度の向上とハルシネーションの抑制を両立させている。 評価実験では、HumanEvalやMBPPといったベンチマークにおいて、既存の検索手法を最大34%上回る改善を確認し、複雑なプログラミング課題における有効性が示された。
なぜこの問題か
大規模言語モデル(LLM)は自然言語からコードを生成する能力に優れているが、複雑なプログラミング問題に直面すると、依然として機能的な正確性を欠く場合がある。 コードの正確性は、APIの使用規則やコーナーケース、慣習的なパターンといった外部知識に依存することが多いが、これらの情報は必ずしもモデルのパラメータ内に一貫して蓄積されているわけではない。 この課題を解決するために、ライブラリのドキュメントやコードリポジトリなどの外部ソースから情報を取得して生成に活用する検索拡張生成(RAG)が実用的な仕組みとして注目されている。 しかし、既存のコード向けRAGにはいくつかの深刻なボトルネックが存在しており、検索されたコンテキストが冗長であったり、部分的にしか関連していなかったり、あるいはモデルを誤導させるようなノイズを含んでいる場合がある。 特に、モデルが長いコンテキストによって注意を散漫にさせられたり、検索された情報を十分に活用できなかったりする現象が報告されており、単純な検索手法では限界がある。…
核心:何を提案したのか
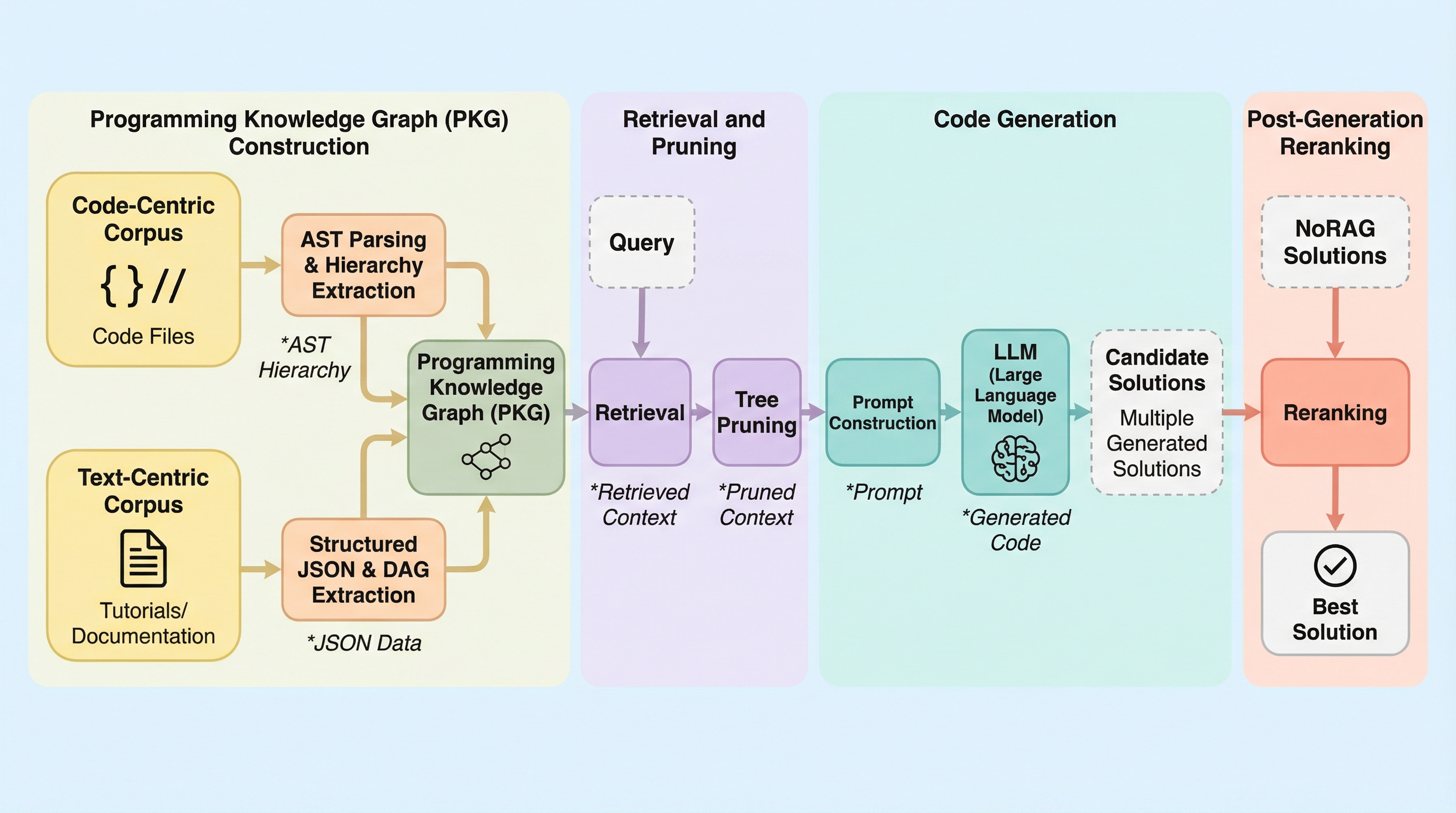
本研究では、コード生成のための新しい知識表現として「プログラミング知識グラフ(PKG)」を提案している。 PKGは、コード中心の資産とテキスト中心の資産の両方を、意味的な階層構造を持つグラフとして表現することで、より精密な情報の取得を可能にするものである。 具体的には、ソースコードをASTに基づいて解析し、関数からブロック、さらに子ブロックへと続く階層的な有向グラフとして構築する「コード中心PKG」を開発した。 これにより、関数レベルという粗い粒度での検索(Func-PKG)と、コードブロックレベルという細かい粒度での検索(Block-PKG)を使い分けることが可能になり、情報の具体性と網羅性のバランスを制御できる。 一方、テキスト中心の資産に対しては、チュートリアルやドキュメントを構造化されたJSON形式に変換し、セクションや例、説明などの関係を保持した有向非巡回グラフ(DAG)として表現する手法を導入した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related