精度を超えて:ツール使用エージェントの能力限界をマッピングする認知負荷フレームワーク
従来のベンチマークは最終的な精度のみを報告し、モデルが失敗する原因となる認知的ボトルネックを隠蔽していたが、本研究は認知負荷理論(CLT)に基づき、タスクの複雑さを構造的な「本質的負荷」と提示方法による「外来的負荷」に分解して定量化する新しい評価フレームワークを提案した。
TL;DR(結論)
従来のベンチマークは最終的な精度のみを報告し、モデルが失敗する原因となる認知的ボトルネックを隠蔽していたが、本研究は認知負荷理論(CLT)に基づき、タスクの複雑さを構造的な「本質的負荷」と提示方法による「外来的負荷」に分解して定量化する新しい評価フレームワークを提案した。 このフレームワークを検証するため、負荷をパラメータで調整可能な世界初のベンチマーク「ToolLoad-Bench」を構築して主要モデルを評価した結果、負荷の増大に伴って性能が急落する「パフォーマンスの崖」が特定され、各モデルのベースライン能力と負荷への感度を定義する独自の認知プロファイルをマッピングすることに成功した。 検証の結果、特化型モデルであるxLAM2-32BがGPT-4oなどの巨大な汎用モデルを上回る高い負荷耐性を示し、提案フレームワークによる予測が実際の測定結果と統計的に高度に一致することが証明されたことで、より効率的で信頼性の高いAIエージェントシステムを構築するための理論的かつ実践的な基盤が確立された。
なぜこの問題か
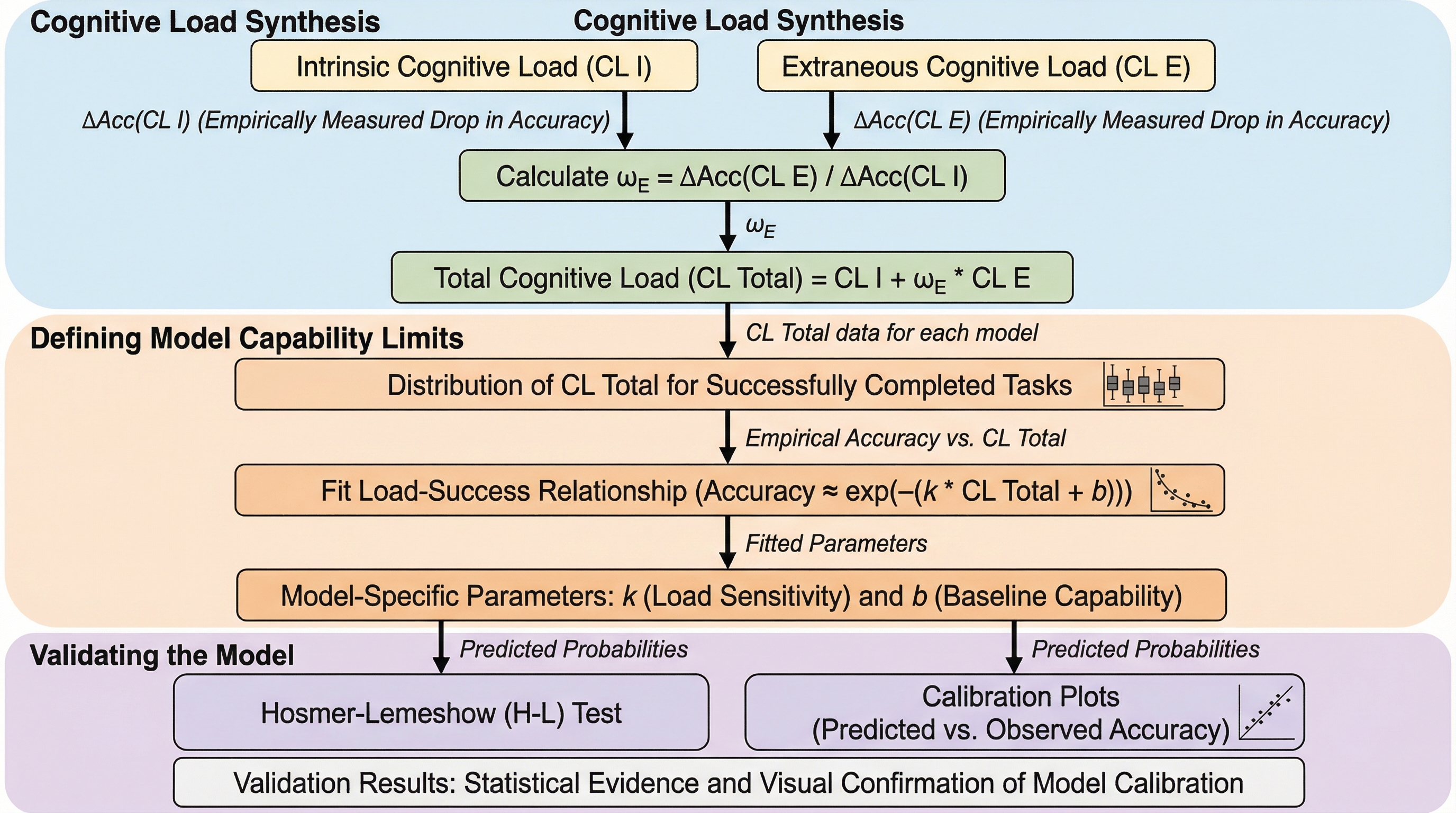
大規模言語モデル(LLM)のパラダイムは、受動的なテキスト生成器から、外部ツール、API、データベース、その他のソフトウェアと相互作用して現実世界の複雑な問題を解決する自律的なエージェントへと急速に進化している。このツール使用能力は、モデルが自身のパラメータに蓄積された知識の限界を超えて行動するためのエンジンであり、これまで解決困難であった多段階のタスクを遂行することを可能にしている。この進展に伴い、モデルのツール使用習熟度を測定するための洗練されたベンチマークが数多く開発されてきた。例えば、数千のAPIを網羅するテストベッドや、関数呼び出しの標準的なリーダーボード、さらには対話型や状態を持つシナリオを探索する新しい評価手法などが存在する。これらの評価は、モデルの全体的な進捗を追跡しランキングを決定する上で極めて貴重な役割を果たしてきた。 しかし、既存の評価パラダイムには重大な欠陥が存在する。それは、評価の結果が最終的な「正解率」という単一の数値に集約されてしまう点である。このようなブラックボックス型の評価は、モデルが何を達成できるかは明らかにするが、いつ、そしてなぜ失敗するのかという重要な情報を覆い隠してしまう。…
核心:何を提案したのか
本研究の核心的な提案は、教育心理学における認知負荷理論(CLT)をAIエージェントの評価に初めて形式的に適用した、診断的な評価フレームワークである。認知負荷理論とは、人間のワーキングメモリには有限の容量があり、タスクの要求がその容量を超えると学習や問題解決が妨げられるという理論である。本研究はこの概念をAIの文脈に翻案し、モデルの計算コンテキストや推論能力を人間のワーキングメモリに見立てて、タスクの複雑さを定量化可能な構成要素に分解した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related